
语境聚合:人工智能的核心战场





人工智能模型掌握的“语境”信息越多,用户体验就越出色。若一家人工智能公司掌握的关于你的“语境”信息比其他公司多100倍,那它便拥有巨大的竞争优势。“语境”信息之争远比一系列人工智能浏览器之争重要。
一、什么是语境
假设你结婚30年,有三个孩子,住在北京。这30年来,你积累了大量关于生活、家庭、家人喜好、愿望和问题等方面的知识。谁更适合回答关于你过去30年生活的问题呢?是谷歌、亚马逊、Meta、DeepSeek,还是你的配偶?显然是你的配偶,因为他们拥有几十年的生活阅历。
向大语言模型(LLM)提问:
“我应该如何改造我的主浴室?”
仅提出这个问题,大语言模型没有任何背景信息。它既不知道你现在的浴室是什么样子,也不清楚其与你家其他部分的风格是否协调。这样的回答很难被认为是优质且相关的。所以,那些对人工智能持怀疑态度的人,若用这种方式测试,会觉得人工智能不太靠谱。但如果你问配偶这个问题,会得到更贴合实际的答案。
人工智能模型需要与情境、问题或对话相关的背景信息,才能生成准确、快速且有用的答案。这些背景信息包括:
• 聊天记录
• 用户意图,即您想要实现什么目标。
• 领域或任务,比如编程、写作、医学、历史等方面的内容。
• 外部数据,如智能手机、Google云端硬盘、印刷材料等上的数据和信息。
• 世界知识,关于时间、地点、人物、相关实体的事实。
这并非单纯的大数据问题。情境是丰富、关联、基于时间、感知位置且不断演进的关于你所处世界的知识。就像已婚配偶的例子,情境是信息,是经验,是对你偏好、习惯和过往经历的深入理解。从这个意义上讲,情境可被视为一种“数字配偶”,也就是真正了解你的人工智能。(这听起来有点不可思议。)
在京东商城上,你能亲身体验到“语境”信息的应用。它知道你购买过什么以及搜索过什么。所以,当你再次访问时,会看到“继续上次购物”的提示,或者看到推荐你可能喜欢的商品,还会建议你重新购买之前买过的商品。
例如,Instagram Reels每秒都会运行复杂算法,根据你过去的观看记录,为你提供更多可能喜欢的短视频。但它对你的亚马逊购物记录、谷歌搜索记录、健康信息、电子邮件、旅行记录、好友关系,甚至你iPhone上的所有信息都一无所知。要是它能知道这些呢?
有一家名为MemO的初创公司致力于保存“语境”信息。它允许用户保存与不同学习记忆库(LLM)的交互记录,并在不同的LLM之间共享这些记忆,从而最大限度地减少令牌的使用和重复学习。而且在这个系统中,用户完全掌控着自己的记忆“语境”。
二、并非所有人都在今天使用人工智能
尽管媒体和市场对人工智能大肆宣传,但并非所有人都接受了它。对于人工智能公司而言,挑战不在于说服高级用户,而在于转化持怀疑态度的中间群体。这部分用户是市场的主要组成部分,也是机遇所在。
对于那些持怀疑态度的人来说,他们面临的问题和任何新技术都会遇到的问题一样:它有什么好处?它比我目前的方式好在哪里?我的同事/朋友在用它吗?为什么要改变?
持怀疑态度的中立人群不会因为模型质量而接受人工智能;只有当人工智能让他们感到个性化、有用且无摩擦时,他们才会接受;而且,当人工智能拥有足够的“语境”信息,能够为中立人群想要完成的任务提供独特的用户体验时,他们才会接受。
三、语境聚合
情境聚合是指持续收集和连接用户生活的每一个片段,包括他们购买、观看、阅读、写作和说话的内容,形成一个统一的理解。其回报是获得一种高度个性化的体验,这种体验几乎如同心灵感应一般。每一个精彩的回答都会促使你提供更多信息,从而创造出一种复利优势,这种优势可能会远远超过当今的搜索或社交护城河。
这种优势会让你不断地向“语境”聚合器提供信息,让它看起来比你更了解你自己。这构成了一道巨大的竞争护城河,其规模可能超过迄今为止任何其他消费者领域的护城河。
语境聚合是成为以人工智能为中心的新型聚合器的方法,正如Ben Thompson在聚合理论中所定义的那样。
通过整合用户“语境”信息,以人工智能为中心的公司可以提供独一无二的卓越用户体验(超越同类最佳水平),这是用户从未体验过的。它能提供答案,帮助用户更高效地完成工作,效果远超以往,甚至超出用户的想象。
如今的平台已经出现了部分内容聚合的现象。但问题是,每个平台都只涵盖了你生活的一部分。
你目前的信息分散在许多不同的科技公司中。谷歌和Meta都是信息聚合商,他们根据你与他们服务的互动情况了解很多关于你的信息,但也有很多信息他们并不知晓。
你通过谷歌搜索旅行目的地,他们或许能看到你发送的航班和酒店预订确认邮件,但不会知道你旅行的全部细节。然而,你手机里的照片可能记录了这一切。
想象一下,如果你在ChatGPT上搜索旅行目的地,然后佩戴一个OpenAI的“语境”捕捉设备,它能记录你去过的所有地方、吃过的食物、住过的地方。有了这些信息,他们是不是就能更好地为你推荐未来的旅行目的地了?也许他们会在你感兴趣的地点推送机票和酒店的优惠信息。如果他们提供的建议和细节让你惊喜不已,你会不会更愿意继续提供更多信息?而且,如果这一切都是免费的呢?
四、摩擦问题:为什么多模态人工智能至关重要
目前的语言学习模型(LLM)是文本预测模型。输入和阅读文本是人工智能应用于大众市场的一大难点。
多模态输入能够加速人工智能的发展。每一种新的输入方式,如语音、照片、摄像头、传感器,都能降低提供“语境”信息的成本。这就是为什么多模态人工智能的普及速度将远超网络或移动技术。
对于那些持怀疑态度的人来说,语音和照片似乎更容易被接受。你现在可以上传照片,征求别人对房间重新装修的建议。但并非人人都知道这一点。而且,一张照片并不能展现房屋的全貌,也无法体现居住者对室内设计的偏好。照片固然有帮助,但它仍然只是冰山一角,无法展现房屋的全貌,也无法了解你之前的选择,更无法得知你伴侣的喜好。
再说一遍,如果你佩戴的设备可以在你走动时拍摄你家的照片,并允许你在需要时提供语音解说,那么就能以更少的阻力捕捉到更多相关的“语境”信息。
降低摩擦不仅能更快地构建情境,还能增强网络效应。每个新用户都会为系统贡献更多有意义的情境。
五、优势飞轮
像谷歌、Netflix、亚马逊、Meta和Airbnb这样的现有聚合平台服务于非常广泛的横向市场。正如本·汤普森在《聚合理论》中所指出的,它们服务的用户越多,服务质量就越好。
这里存在一些差异。信任和隐私将在用户是否愿意提供更多背景信息方面发挥更大的作用。而且,毫无疑问,人工智能提供的结果必须至少在某些特定方面表现出色,才能使这种良性循环发挥作用。
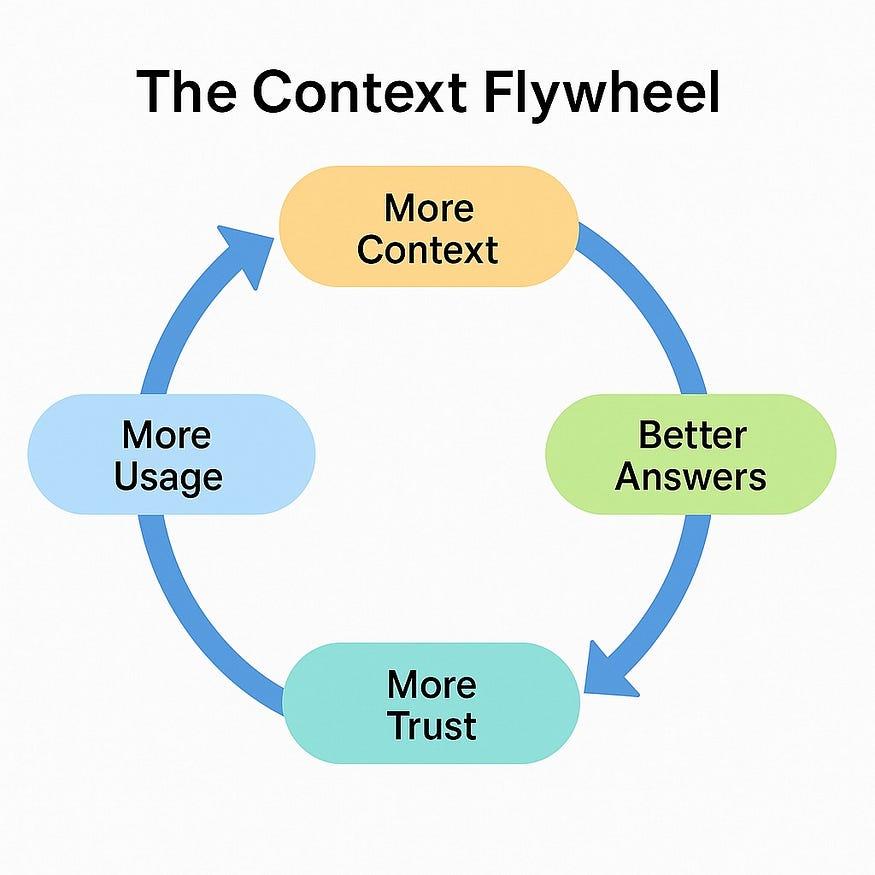
如果采用“语境”聚合技术,情况会如何发展?人工智能公司是否有可能聚合足够的“语境”信息,从而无需为新用户提供过多的“语境”信息,就能为其提供独特的用户体验?或许他们可以从新用户那里获取足够的“语境”信息,从而预测出许多用户未提供的“语境”信息?这将使人工智能公司能够更快地整合其聚合信息。
小结
当然,“语境”聚合涉及诸多深刻的伦理和隐私问题,这本身就是一个庞大的话题,值得单独探讨。监管也是一个需要全面讨论的话题。
在这场人工智能的战争中,最终的赢家并非拥有最庞大模型或最佳人工智能浏览器的一方,而是那些拥有最丰富、最值得信赖的“语境”信息,服务于最多用户,并将这些信息转化为前所未有的独特用户体验的一方。这种用户体验不仅能精准满足用户的需求,更能带来远超预期的丰富体验。这样的体验将进一步巩固“语境”聚合器在人工智能领域“几乎包揽一切”的地位。
但是,要想获得成功,这样的用户体验必须帮助大众,尤其是那些持怀疑态度的中间群体,以他们从未想过的方式更快、更轻松、更经济地完成事情。而且,正如我所说,它必须以一种令用户惊叹不已的方式呈现,超越他们的想象。
如果一家以人工智能为中心的公司想要赢得情境战争,它应该开发哪些类型的服务和设备?当萨姆·奥特曼谈到实现超级智能时,这在情境战争中扮演着怎样的角色?用户是否需要感受到他们拥有超级智能,才能与具备丰富情境信息的人工智能伙伴建立联系?
最后,我们来做一个思想实验:试着想想,一个超级智能的人工智能会为你做哪些事情,让你考虑向它提供更多关于你的信息。
对于软件开发人员来说,编码就是一个很好的微观例子。像Claude Code(以及其他类似工具)这样的工具了解你的整个代码库、文档、测试和提交历史。你之所以信任它们,是因为它们返回的结果往往令人惊艳。
同样的信任循环,“语境”带来更好的结果,从而带来更多信任,这将决定“语境”聚合之战的赢家。
本文来自微信公众号“数据驱动智能”(ID:Data_0101),作者:晓晓,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com