
六小强大模型,推动AI进入「海淀时刻」





有些人将2025年定义为AI觉醒的第一年。
因为2025年还没过三个月,就已经有了流量DeepSeek,前阵子爆红的“炸子鸡”智能体Manus,让男女老少,对AI的触觉不再是一个很高的研究成果,更是提高生产效率的关键。
昨天,百度还发布了文心大模型X1和文心大模型4.5,继续为大模型产业提供“上强度”。
模型一发布,海外KOL就像DeepSeek一样惊呆了。
Bill·Gurley是华尔街著名的科技投资者,他说:美国人工智能公司应该把100%的时间花在开发和创新上,而不是在华盛顿闲逛。
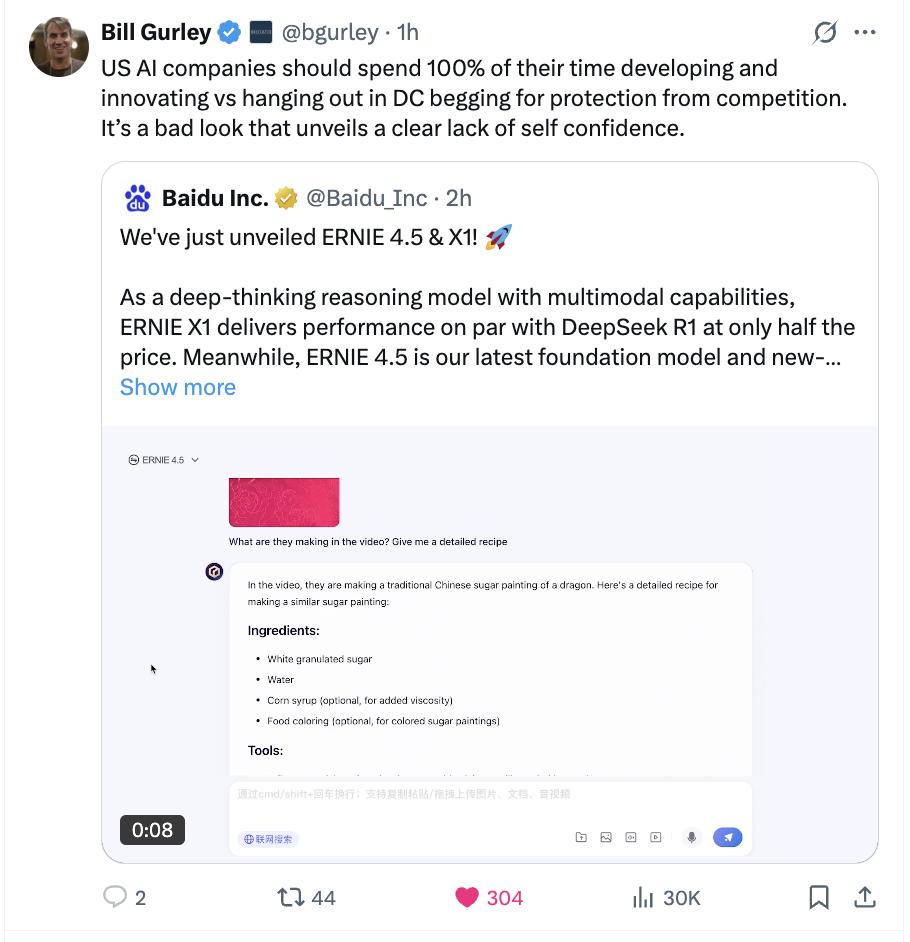
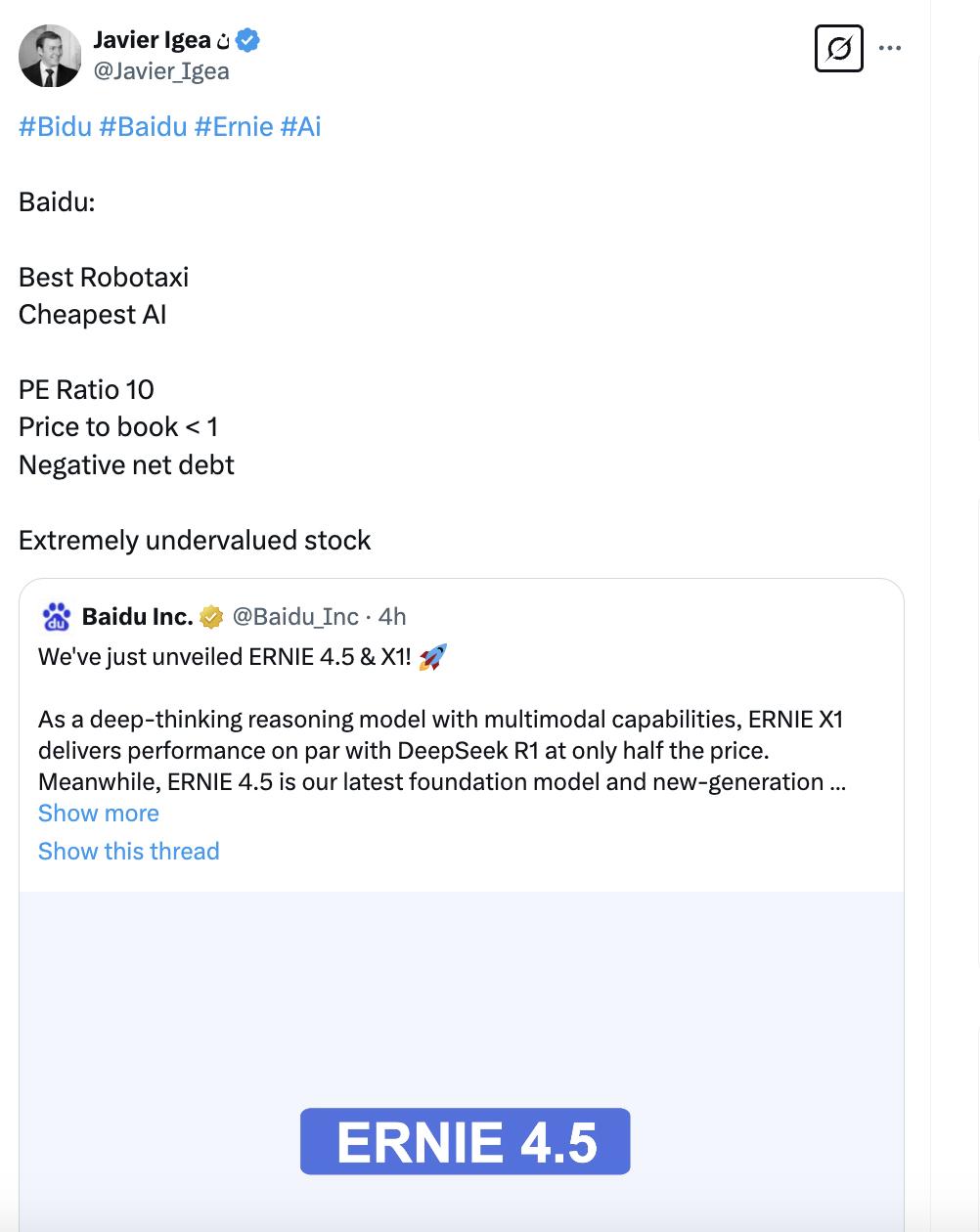
著名的意大利价值投资者哈维尔·伊格亚已经开始再次对百度进行估值:
01 大型模型的进化,一直在继续
每个人都强烈围观文心大模X1和文心大模4.5,原因没有其他,就是模型“好用”。
其中文心大模型X1,使得大模型“好用”达到了一个新的高度。
文心大模型X1的官方介绍是:第一个能够独立使用工具的深度思考模型,具有较强的理解、规划、反思、进化能力。
如何理解这种能力?《节点财经》首先考了一个小问题,让它谈谈名创优品的上市过程和分析:

在这里,文心大模型X1只是完成了我们给它的初步任务,它可以轻松简洁地分析著名创优产品发展的重要节点。
《节点财经》看到很多评价博主用文心大模型X1来解决数学题。我们准备增加一些难度,让它在注册会计师财务管理课程中做一些考题。每个人都知道财务管理考试的难度。
在这个经典的考题中,文心大模型X1的探索非常适合没有学过财务管理课程的用户。虽然教材的答案简洁明了,但文心给出了一个完整的思考过程。

另外,《节点财经》还考了一个需要结合财务知识进行推理的财务管理题目:

文心大模型X1以比正确答案更清晰的方式进行推理,并解决了财务知识叠加计算的问题。
《节点财经》还看到,评价博主还为X1设置了很多人,说是软装设计师。如果上传房子的照片,可以重新设计软装效果;也是健身教练。上传一张照片可以分析健身姿势是否正确;或者剧本杀外挂、数学专家、旅游策划人、电影电视剧之王、游戏专家等。由于其在中文知识问答、文艺创作、文稿写作、日常对话、逻辑判断、复杂计算和工具调用等方面的表现较强。
但《节点财经》认为,X1更准确的人物设计,应该能够真正让普通用户对大模型的感知落地——如果有什么不能“X1”。
此外,百度还推出了新的文心大模型4.5。作为百度新一代底座大模型,文心大模型4.5的许多基准测试结果优于GPT4.5。、DeepSeek-在GPT4.5中,V3等平均分为79.6分,高于79.14。
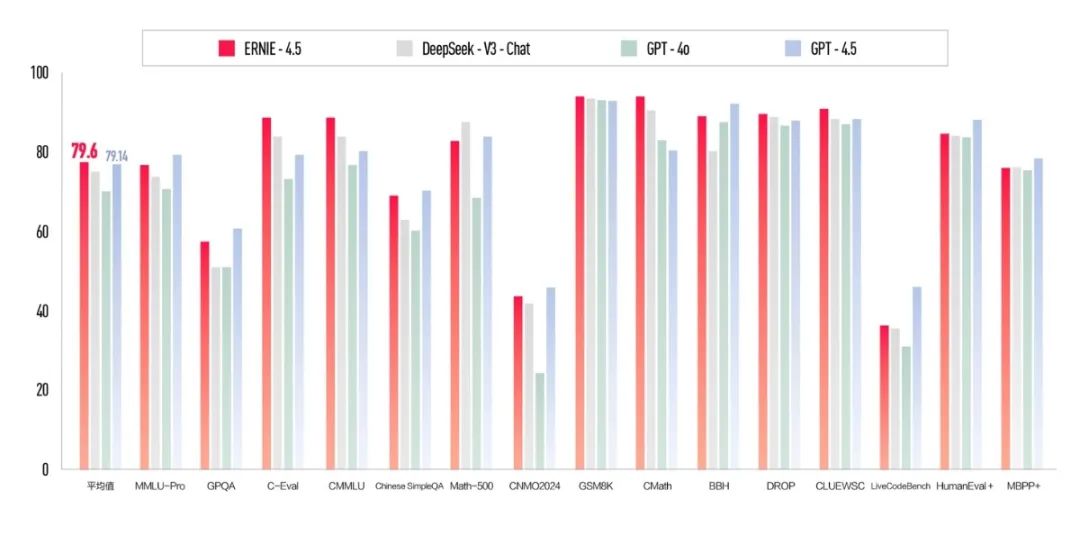
特别是文心大模型4.5在多模态理解能力上有了显著提高,不仅有图形推理、图表分析的“智商”和“高情商”。
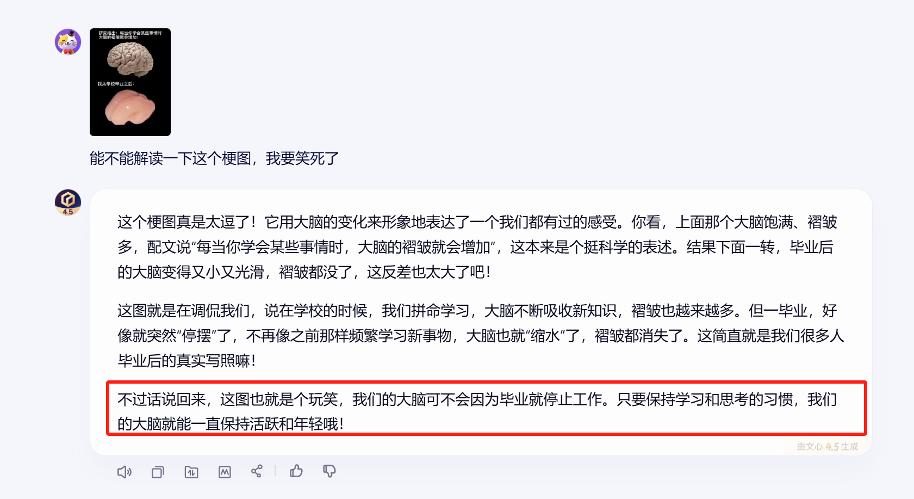
例如我让它帮我解读一个梗图,它解读后还“高情商”地鼓励我上班也要继续学习:
总而言之,文心大模型X1和4.5那就是“各有千秋”,可以在不同的场景中提供强烈的思考。
与此同时,文心大模型4.5系列和更前沿的文心5.0也在密集的研发中。特别是百度此前宣布,文心将于4月1日免费发表。这次发布不仅带来了两个全新的大模型,还提前提前提供了免费时间,全面提升了客户体验。
正如李彦宏所说,“我们仍然需要继续投资芯片、数据中心和云基础设施,以创建更好、更智能的下一代模型。”这也说明百度一直在投资模型,从未完成过桌子。
02 海淀除文心大模型“亮剑”外,还有“六小强”
除了文心大模型X1和4.5的“亮剑”之外,最近大模型的牌桌上还有很多令人兴奋的新品,可以看出大模型已经从原来的“百模对决”大步走进了行业深度应用的试验场。《节点财经》还发现了一个有趣的现象,那就是海淀区发生了这些大模型的“豹变”。
就在百度官方公布的前几天,豆包接入了Tiktok。在观看短视频内容的同时,客户可以借助豆包的AI能力立即获得与视频相关的详细答案,从而满足自己的即时知识需求。
Aautorapper的视觉大模型很有灵性。和文心大模型一样,不到一年就发布了几次迭代,娱乐领域的各种AI短片不断更新。很多用户看到一句话就想问,这是人类做的吗?
年初还发布了月亮的暗面。Kimi k1.5多模态思维模式,再一次对日常生活中所需的代码编写、解题能力进行了深度升级。
不难看出,AI大模型的应用场景越来越广泛,例如文心大模型X1和4.5的出现,已经达到了“模型即应用”的目标。;快手可灵也成为了一些著名导演的生产设备。如今,教育、艺术、办公、金融、医疗、制造等行业已经开始积极拥抱大模型应用,这也促进了大模型在底层的进化。
目前,大型技术栈大致可以分为芯片层、框架层、模型层和网络层四个关键层,百度已经成为世界上很少有公司能在这四个层面上布局的公司之一。
此外,寒武纪等公司还覆盖云、边缘智能芯片及其加速卡、整机训练、CpuIP和软件,可以满足云、边、端不同规模的人工智能计算需求,帮助许多大型公司降低部署成本;
在框架层和模型层,智谱研究等大型企业与智能汽车、制造、大消费、金融、政务服务、医疗健康、游戏娱乐、文化旅游产业等多家行业公司建立了合作关系...
这四个关键层次的背后,是流量入口、数据资产、用户场景和AI能力的多维结合。所以海淀不仅有学校“六小强”,大模型企业也在以“六小强”的趋势,更高效地将技术注入业务毛细管,在千行百业中占据大模型的先发优势。
03 “海淀样版”大模型
为什么海淀能在大模型进化过程中不费吹灰之力地拿出“六小强”?
从行业角度来看,海淀区已经构建了一个基本的自控全产业链技术体系,包括芯片、框架、大模型、落地应用等。
比如在“六小强”中,百度全栈布局、寒武纪布局芯片、智谱研究专注B端、快手可灵偏向娱乐落地、豆包偏向C端与Tiktok相结合、月亮暗面偏向文字思维。海淀在每一个大型产业链的关键节点都是“强大而强大”的,这也构成了相关产业带的“吸引磁场”。
就支持而言,海淀并不喊口号,的确是真金白银的支持,其中既有耐心资本,也有大胆资本。
早在2023年,北京市就率先推出了地方大模型政策的第一枪。海淀区率先打样,提出从人才落户、资金补贴、公租房等方面给予人才补贴,打造核心产业规模2300亿元。
此后,中关村科学城科技增长基金连续发布,第三期规模达到100亿元,科技增长基金总规模增至200亿元。此外,中关村科学城科技增长三期基金还强调“坚持投资早、投资小、投资长期、投资硬科技”。
特别是海淀在很多城市追求大型模型项目时,长期以来一直关注应用的结合,计划每年安排最高1亿元的资金支持大型产业实验室建设和核心需求场景开放,引领产业创新,赋能实体经济。
可以看出,数百亿的“耐心资本”给了AI公司更多的时间和发展空间,而投资早、投资小的“大胆资本”则提高了AI相关企业的投资风险承受偏好。
特别是这六小强,实际上是“耐心而大胆”的代表。
比如百度对AI的耐心在过去的十年里花费了1700亿元研发,使得文心的大模型不断降低成本,文心的言论完全免费,大模型的调用价格不断降低;智谱研究和月亮的暗面从清华走出来,让大模型的相关应用从实验室走向大众;快手可灵多年来一直从内容业务中诞生,率先在视觉模型上落地,被业界评为“超越sora”...
做一个生动的对比。在海淀,大模型“六小强”的氛围与学校“六小强”非常相似。小强们都展示了自己的优势,促进了教育资源的普遍利益。大模型六小强也在推广“AI普惠”。他们开发的产品和服务不仅仅是手机上的app。、AI全能助手在工作和生活中也构成了“海淀样板”的大模式发展。
写在最后
不久前,李彦宏提出了一个关于大模型“两步走”的论点:一是通过技术创新不断降低大模型和人工智能的成本;其次,将大力推动人工智能的大规模应用。
这两个步骤看似由浅入深,实则暗示着大型攀登者不仅要保持仰望星空的气魄,突破技术无人区的束缚;我们应该有脚踏实地的耐心,在广阔的工业数字领域培育智能经济的新生态。
站在人工智能第三波的顶端,我们知道前方不会是一条平坦的道路。当技术创新和应用实践的飞轮继续旋转,当智能之光逐渐照亮实体经济的每一个角落时,一个人工智能深度参与的新时代正在慢慢开始。
本文来自微信微信官方账号“节点财经”(ID:作者:六金,36氪经授权发布,jiedian2018)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com