
DeepSeek让腾讯阿里再次上桌。







巨人的行动无疑是行业的真正方向标。在腾讯调整组织结构专攻AI产品后,阿里还宣布,未来三年在云和AI的基础设施投资预计将超过过去十年的总和。AI的发令枪已经响了。
"领导是认真的"
春节复工后,她在深圳一个传统行业担任行政职务的困难被告知她还有一项工作:“用DeepSeek完成一些工作,提高工作效率,部门领导要求每周整理并报告AI工具的使用结果。”

这让她大吃一惊。“我们是传统行业。虽然我们以前使用过一些AI技术,但我们只有R&D同事,不涉及我们的行政部门。”棘棘发牢骚:「每天的行政只是收发快递,贴发票,跑腿,有必要用AI吗?」
但是后来,她意识到这次公司领导特别认真。根据她的说法,几天之内,公司迅速建立了一个“AI战略部门”,并邀请外部讲师培训所有人员使用DeepSeek,并要求所有部门每周提交结果。实施AI的范围也是前所未有的——有领导在培训会上说,从下个月开始,企业计划逐步优化部分可以用AI替代的岗位人员。

秋然在北京一家互联网公司总部工作,也感受到了DeepSeek卷起的热潮。
她回忆说,节后复工一周左右,公司给全体员工发了一条通知,忽略了:“请集思广益,深入思考DeepSeek可能给业务带来什么促进,或者可以在什么场景下落地,并提交思考结果。”
技术支持部门行动迅速,一些工具是通过DeepSeek的开源思路建立起来的。秋然说:“作为一家互联网公司,我们有自己的AI优势储备,业务形式已经非常成熟,所以老板之前一直都很谨慎,不愿意为了AI而刻意向外求AI。”

但是DeepSeek打破了之前所有的犹豫,秋然透露:“听部门领导说,老板觉得如果此时不做动作,可能会在这波浪潮中被甩下。”
老板们的危机感不难理解,DeepSeek的效果令人惊叹,这直接推动了各家各户的决策。棘棘告诉凤凰网科技,员工们私下悄悄交流,发现领导层都被DeepSeek的效果“震撼”了,“ChatGPT之前、Claude发布的时候,公司也有小规模的业务同事尝试过,但是都是各有各的‘智障’,过两天就不提了。”
DeepSeek打破了AI是“人工智能障碍”的刻板印象。据她从新成立的AI部门的同事处了解,该公司甚至考虑增加AI技术的投资。
假设小企业的分析还存在失误的可能性,那么巨人的行动,无疑是这一行业的真正方向标。
二月二十日晚,阿里发布财务报告,阿里集团CEO吴泳铭在财务报告电话会议上表示,“ AI时代对基础设施有着清晰而巨大的需求,将积极投资AI基础设施。预计未来三年云和AI基础设施投资将超过过去十年的总和。"

一位与阿里有过接触的应聘者对凤凰网科技说:“阿里也在AItoC业务层面大举招贤纳士”,“看得出来,很积极”。
就在几天前,腾讯还宣布了组织结构的调整,主要针对AI产品线。在腾讯元宝从TEG(技术工程业务集团)转向CSIG(腾讯云与工业业务集团)后,更多的产品和应用,如QQ浏览器、搜狗输入法和ima,也将汇聚到CSIG。
在接入DeepSeek-R1之后,腾讯也是第一个接入DeepSeek的巨头,微信迅速掀起了市场波澜。
AI的发令枪,已经响了。
狂欢与隐患并存
尽管有很多新的涌入者,但是身处其中的一些人并不感到惊讶,在苏州一家智能制造企业担任CTO的冯牧就是其中之一。
他告诉凤凰。com科技:“成本、技术、环境和各种因素共同创造了行业的狂欢。对于很多像我们这样的企业来说,他们没有很强的R&D大模型能力,在科技革命的过程中非常被动。然而,DeepSeek开源了这样一个强大的模型。(为我们)提供了一剂良药,一种从0到1不平整技术壁垒的方法论。”
正如他所说,上游技术创新带来的好处自然流向下游阶段。但另一方面,压力也给了与DeepSeek同处于底座大模型研发环节的同行。

同样具有优秀研究能力的企业,开始反思自己到底错过了什么。
DeepSeek V3和R1的最大功能亮点是特别优秀的思维链。(Long-CoT)能力。
月亮暗面研究员Flood Sung透露,早在一年多前,月亮的暗面创始人周昕宇就已经验证了长思维链的有效性,但公司首先意识到了长文本。(Long-Text)考虑到成本问题,Kimi选择了优先考虑攻关长文本功能的重要性。
这条路线在DeepSeek爆红之前完全没有问题。
2024年,月之暗面一度借用长文成为中国最热门的大型企业,但长文本的商业化场景一直不够清晰,目前仍在探索中。
冯牧对凤凰网科技的解释:“你可以把长思维链理解为解决复杂问题的能力。当一个大模型有推理思维时,它在编程、数学计算等领域的应用能力就会提高。这就是为什么DeepSeek应该标记OpenAI的o1模型,而后者也是一个标榜思维能力的大模型。”
冯牧强调o1和DeepSeek V3发布时间差:“o1正式版于2024年12月初发布,V3于12月底发布,两者的性能都可以断腕。我们过去常说,国内大模型和国外发展相差几年。至少在这种模式下,DeepSeek帮助我们平衡了一些差距。”
亮丽的效果,也使得DeepSeek迅速下沉,撬动了过去任何一家大型公司都无法撬动的用户盘。
根据QuestMobile的统计,1月28日DeepSeek的日活跃用户数量首次超过豆包,并于2月1日突破3000万大关,成为历史上最快实现这一里程碑的应用。而且随着各大手机厂商、微信等公司正式宣布接入DeepSeek,流量疯狂涌向后者的趋势仍在不断增加。
在这种背景下,从网络时代传承下来的大力投放方式是否有效?凤凰网科技询问百度、腾讯、昆仑万维等公司,下一步是否考虑大型产品调整投放策略,截至发布时尚无回复。
但是从数据中,或许可以看出市场的答案。
AppGrowing数据显示,最近豆包App、Kimi等广告营销量大幅下降,最低水平几乎降至近180天。
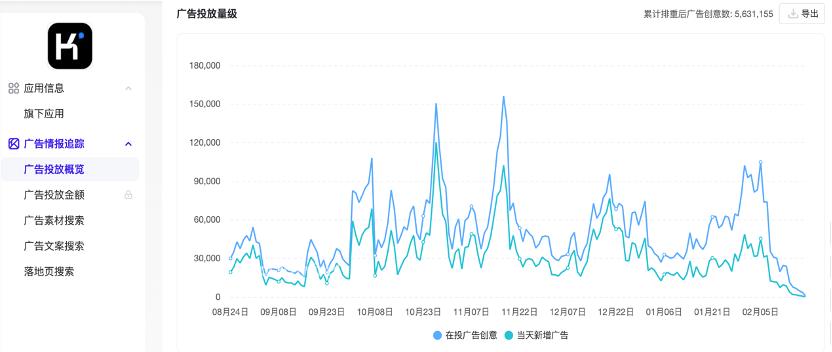
那些没有意识到的变化
几天前,DeepSeek悄悄地取下了张贴在办公楼下的LOGO。在DeepSeek飓风席卷半个月后,北京融科信息中心作为DeepSeek与英特尔、中金、德州仪器等公司交流的办公室,竟然成为一处景点。
DeepSeek就像一条鲶鱼,搅拌市场。即使是在DeepSeek楼上工作的百度风险投资也无法避免,被质疑离这么近却错过了投资机会。百度风险投资首席执行官高雪不得不亲自回应,声明对方没有意外融资。
尽管DeepSeek故意保持低调,但是从今天开始,许多人的工作仍然与DeepSeek密切相关。
DeepSeek的独特标签除了思维链模型之外,还有开源模式和低计算能力需求。这三点几乎摆脱了国内市场主流玩家下注的所有玩法,甚至重新定义了游戏规则。
百度原本坚持闭源路线,决定允许所有PC端和APP端用户从4月1日0:00开始免费使用模型服务,并计划从下一代模型开始正式开源。
作为长思维链的代名词,“深度思维”功能逐渐成为众多大模型的核心标签。从1月份开始,百度、阿里、字节、科大讯飞、百川智能、月亮暗面等AI公司为其模型提升了深度思维能力。
怎样看待DeepSeek另辟蹊径给出的答案?
“没有人敢定义它是对的,只能说它真的是一个不可忽视的创新。”北京市朝阳区AI大型培训服务企业AI领域连续创业者和创始人告诉凤凰科技。com。
“我想了很久,最终的答案是这是囚徒的困境——如果关闭源头,作为一家创业公司,谁会用你的东西?”为什么要和大厂竞争?所以创业公司只能开源,但是开发者必须只有效果论,那么在DeepSeek之前,世界上最好的开源模式是海外Llama,你应该如何追上Meta?他说:“所以我最初的预测是,国内大厂迅速进行军备竞赛,做出一些效果不错的模型,然后开源一部分,千行百业集中在大厂的底座上。”
企业家承认,他没有想到DeepSeek会在这场相关背景实力的比赛中脱颖而出。现在在西二旗的一家大工厂工作,曾经有硅谷工作背景的算法工程师也表达了类似的情绪。
这种“DeepSeek效应”席卷了市场,也蔓延到了产业链的上游。
根据DeepSeek发表的相关论文,只有280万GPU被用来训练V3。根据OpenAI创始成员之一Andrej 相比之下,Karpathy解读的模型训练成本是DeepSeek的十倍以上。(Llama 3 405B使用了3080万GPU小时)。
正是如此,DeepSeek-V3和R1模型被称为“有限算率下的精彩工程”,也引发了市场对GPU淘金热持续时间的反思。
DeepSeek发布后,全球领先的GPU英伟达股价一度暴跌,其中单日跌幅最大达17%。但截至成文,英伟达股价已基本回升至本轮下跌前的水平。
即便如此,当DeepSeek指出一条更经济的道路时,玩家是否应该继续沉迷于这场相关的算率资源“无限战争”?接下来,有些人可能会给出更保守的答案。
(冯牧是文章中的化名)
本文来自微信微信官方账号“凤凰网科技”,作者:徐珍,编辑:董雨晴,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com