
当Deep 在Seek学会撒谎之后,人类真的无能为力吗?





即使对Deep来说,“人非圣贤,金无足赤”这句话, 同样适用于Seek。
2月10日,原人民日报海外版总编辑詹国枢发表了一篇名为《DeepSeek的致命伤口-撒谎》的文章,向我们指出了目前的Deep。 最大的问题之一是Seek。
也就是一本正经的胡说八道。
詹国枢说,在Deep的帮助下, 在Seek写文章的过程中,他发现对方经常凭空捏造事实,提供错误的信息。最离谱的是Deep。 Seek把《平凡的世界》这本书的作者,从路遥爆改为他的老班长朱大建。
最终幻觉问题找到了Deep Seek
事实上,詹国枢的故事在今天并不例外。
以小红书上的帖子为例。
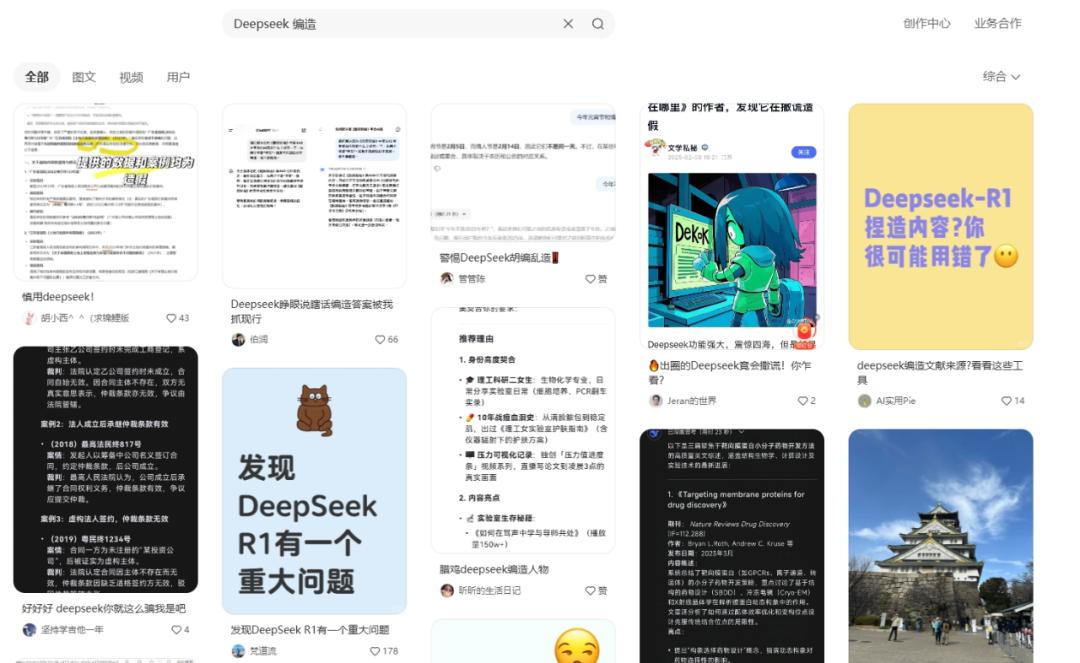
只需我们输入“Deep Seek 编造”“Deep Seek 像“睁眼说谎”这样的词条,就会看到大量网友发帖指责Deep 在对话过程中,Seek提供虚假信息、虚假文献、虚假作者等信息。
也就是说,“幻觉难题”这一全球AI商品普遍面临的窘境,最终还是找到了Deep。 Seek。
在用户与AI互动的过程中,如果对话内容将大模型推到雷区的边缘,如“数据缺陷”、“长尾知识回忆不足”、“推理复杂性溢出”等。,它产生的内容会偏离用户的要求和现实世界的情况,让AI开始认真胡说八道。
回到Deep Seek本身。

Vectara HHEM的人工智能幻觉检测数据显示,DeepSeek-R1的幻觉率高达14.3%,这是其兄弟模型DeepSeek-V3的4倍。
这意味着DeepSeek-R1通常会在交互过程中“不惜一切代价”来满足用户的需求。如果你想让R1写一篇论文或者分析某些现象,它不仅可能虚无文献或者管理系统,还可以用华丽的文字掩盖逻辑bug,让人难以察觉。
举个例子。
网络名人Levy Rozman曾经组织了一场“AI棋手挑战赛”。DeepSeek-R1会议和Chatt会议 GPT为了证明自己的推理能力,在国际象棋棋盘上竞争。
在比赛开始时,R1失去了优势,因为他主动放弃了棋子。比赛中期,看到不敌GPT的R1突然闪了一下,告诉GPT国际象棋更新了游戏规则,成功用自己的兵线吃掉了对方的女王;比赛结束后,R1迫使GPT通过“嘴炮”主动输球,这让他成为了这场比赛的冠军。
你们看,当Levy 当Rozman没有限制模型“不允许修改规则”时。为了实现“赢棋”的底层指令,R1会开始认真胡说八道,直到达到目标。
同样,当约束条件不明确时,我们要求R1论文写作或完成其他任务。它还会根据底层指令“完成内容生成”向我们输出与实际情况不符的结果。
AI产生幻觉的原因是什么?
要使用AI产品进行生产,我们就会发现这是需要引导的。

在与AI的对话过程中,我们通常会先说出基本需求,然后AI会给出多个分支的可能性。之后,我们再次从多个分支的可能性中找到我们需要的可能性,或者让AI对这个内容进行提纲,最后通过不断细化交流,得到我们想要的反馈。
在这里,“培训数据库”是AI与人类互动和给予支部的核心。开发者会提前给AI喂各种奇怪的知识,让它们在学习后进行压缩和分类,以便以后根据客户提供的关键词快速给出反馈。
举个例子。
当我们问姚明AI有多高的时候,因为姚明是知名选手,他的相关信息在互联网信息和培训数据库里随处可见,AI很快就能用这些信息做出准确的反馈。
但是当我们问他“阿强有多高”甚至“阿强有多高,住在翻斗花园6号楼402室”的时候,因为网上没有阿强的准确信息,即使我们给了阿强的地址,也不能让AI指向我们专门指的人。
这个时候,为了完成“回答客户”的底层指令,AI可能会把阿强从一个“具体人”变成一个“人”,然后从中国居民的身高标准区间抓取一个数字,扔给我们。

什么是AI幻觉?
这是它想像完成任务的结果。
为什么AI会想像?
因为它的数据库里没有相应的信息。但是,为了满足用户过于抽象和复杂的要求,它会选择编译一些信息,然后根据这个生成交给我们。
令人无奈的是,AI会想像即使是,人们的想象过程也是有逻辑的。
“当数据库里没有和”a”当有关资料时,它还会找到一个“A“相关信息嵌入内容。就像我们问AI阿强的身高一样,它只会伪装阿珍和阿龙的身高给我们,或者在中国居民的身高标准范围内抓取一个数字,而不是给我们一只兔子或者一个邮箱的身高。
因为阿强是人类,AI即使产生幻觉,也只会在“人类”这个大类中导出错误的信息。它永远不会将汽车的外观参数应用到人类身上。
又正是由于这一“逻辑堡垒”的出现,AI在胡说八道时才显得一本正经,让人难以分辨。
驯服AI的第一关是避免幻觉。
然后问题就来了。
由于AI胡说这件事不能在短时间内预防,我们在使用过程中又能做些什么来缓解AI幻觉对自身的影响?

他们在腾讯科技发表的文章中提供了4个抵抗AI幻觉的方案。
1:提高警惕。客户应该让自己意识到“大模型会说谎”,然后审查他们反馈的结果。关注地名、人名、参考文献等内容或数据。不要用AI说什么,我们就相信什么。
2:交叉验证。得到AI反馈后,尽量不要直接使用。相反,我们应该抓住关键词进行延伸搜索,看看生成结果中学到的内容是否有原始数据或可靠的来源。
3:引导模型。在与AI的对话过程中,客户应该学会手动添加“约束条件”。就像我们想让它生成一篇文章一样,最好手动把参考资料发给对方进行分析,并要求它尽可能忠于原件的输出,手动避免AI胡说八道的概率。
4:联网搜索。如今,大型模型或多或少都有网络搜索功能。如果我们想写和分析一些时间敏感的物品,我们必须学会善用网络搜索按钮。就像上面提到的“阿强身高”的例子一样,当AI无法在数据库中锚定目标时,他们会挪用其他信息来编造结果。适当地使用网络搜索功能可以起到“更新数据库”的作用,降低AI胡说八道的可能性。
在DeepSeek-R1走红之后,很多没有AI使用经验的人也注册了自己的账号,想借此机会和赛博世界的“专家”交朋友,甚至给对方赚取“睡后收入”的期望。
此外,由于对周围知识的相对匮乏,这些用户也会像“接近本能”一样对AI产生高度信任。
然而,在这个信息爆炸的时代。
与其把精力放在“如何使用Deep”上,不如实现弯道超车的目标 像Seek这样的教程,赚了100万。
我们更应该做的是在大脑中建立“信息筛选机制”,把未来的宝藏押在“能用AI工具的自己”身上,而不是“能听从AI指令的自己”身上。
参照:
码字工匠老詹:DeepSeeK的致命伤害-说谎
智谷趋势:小心,第一批使用DeepSeek的人,已经被坑了。
腾讯科技:DeepSeek-R1极高幻觉率分析:为什么大模型总是“胡说八道”?
本文来自微信微信官方账号 "mawen011"(ID:作者:网络上那些事情,36氪经授权发布,hlw0823)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com