
OpenAI重磅推出Operator-首款AI智能体正式亮相








2025年1月24日,OpenAI发布了第一款AI智能体Operator,它是一款可以在浏览器上执行简单在线任务的网络应用程序,如预订音乐会门票、在线订购杂货等。
基于GPT-4o的Operator新模型Computerator-Using Agent(CUA)目前只对注册ChatGPT给予支持 Pro(每月200美元高级服务)美国客户开放,计划在未来向其他用户推出。
Operator之所以如此强大,是因为它背后的Computer-Using Agent(CUA)模型。该模型基于GPT-4o,通过与图形用户界面的界面进行构建(GUI)互动,展现惊人的能力。
CUA模型具有与人类相同的视觉能力(通过屏幕截屏“看到”界面元素)和通过强化学习获得的先进推理能力。
能像人一样操作,在浏览器界面上“看到”按钮、菜单和输入框,熟练地使用鼠标和键盘与之互动。
CUA基于对多年多模态理解和推理交叉领域的基础研究,特别是在任务过程中,CUA模型的自我纠错能力是一大亮点。
遇到难题或出错时,可以依靠推理能力进行自我调整;
如遇不能解决的情况,将礼貌地将控制权交给客户,实现人机合作之间的顺利转换。
值得注意的是,Operator在安全和隐私保护方面表现良好。
OpenAI明确表示,Operator在运行过程中,绝不会使用客户之前与ChatGPT交流的数据,全方位呵护用户隐私。
并且,名为“接管方式”的功能为其安全保驾护航,在输入支付信息或登录凭证等关键操作时,会要求用户手动完成。
与此同时,OpenAI提到, 虽然CUA还处于起步阶段,并且有局限性,但是它设定了一个新的最先进的标准结果,在OSWorld上实现了38.1%的全计算机使用任务通过率,在WebArena上实现了58.1%。 87%的WebVoyager。
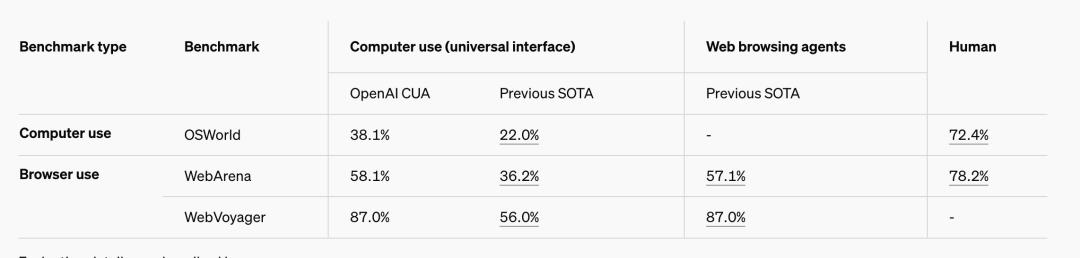
这一结果凸显了CUA在各种环境下使用单一通用动作空间进行导航和操作的能力。
Computer-Using Agent(CUA)如何运作?
通过一个集成感知、推理和行为的迭代循环,CUA按照用户的指示进行操作:
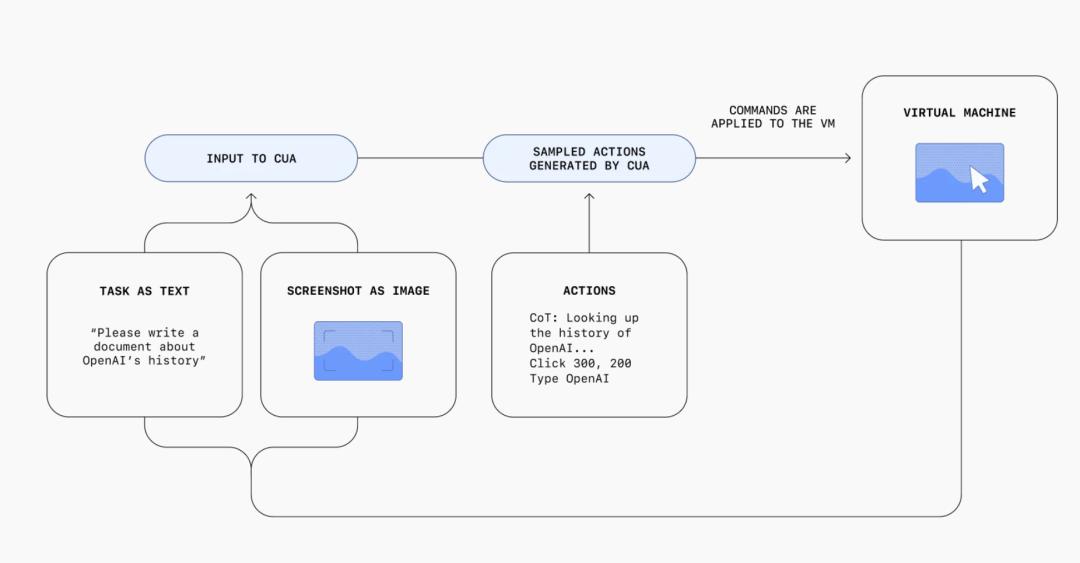
简而言之,CUA模型实现与GUI(图形用户界面)的主要交互技术:
视觉感知
屏幕截图分析:CUA模型具有类似于人类的视觉能力,它将首先截图屏幕。然后,利用图像识别技术分析截图中的各种元素,例如识别按钮的位置、颜色、形状、菜单的结构和输入框的内容。这就像人类用眼睛观察屏幕一样,是互动的基础。
元素定位和分类:CUA模型在识别屏幕元素后,会对这些元素进行定位和分类。它确定了屏幕坐标系中每个元素的位置,并根据元素类型进行分类(如点击按钮、输入输入框等)。),以便后续与之准确互动。
操作规划
任务分解:CUA模型在接收到需要在GUI上解决的问题时,会将这个复杂的任务转化为几个小的子任务。例如,如果你想在一个电子商务网站上购买商品,子任务可能包括搜索商品、选择商品规格、点击购买按钮等。
操作序列生成:根据任务分解的结果,CUA模型会生成操作序列。它会考虑每个元素之间的关系和操作的顺序,比如先点击一个菜单进行选项,然后在弹出的列表中选择特定的项目。
执行操作
鼠标和键盘模拟:CUA模型通过模拟人类使用鼠标和键盘的操作来实现与GUI的互动。点击识别的按钮,它会模拟鼠标单击操作;对于需要输入内容的输入框,它会模拟键盘输入相应的字符。
实时反馈和调整:在操作过程中,CUA模型会密切关注屏幕的变化,获得实时反馈。如果操作没有达到预期效果,比如点击按钮没有响应或者有错误提示,会根据反馈信息调整操作策略,重新规划后续操作步骤。
自我纠正和学习
错误检测和回溯:如果在任务过程中出现错误,CUA模型可以检测到问题。它可能会回到上一个操作过程,重新评估情况,尝试不同的操作方法。
强化学习推广:CUA模型利用强化学习技术不断优化其与GUI的互动策略。模型逐渐学会更高效、更准确地实现目标,通过不断尝试不同的操作方法,并根据结果获得奖励或处罚信号。
今天OpenAIOperator的出现,也标志着AI发展的下一步,让模型可以利用人类日常依赖的相同工具,为大量新应用打开大门...
本文来自微信微信官方账号 “亿欧网”(ID:i-yiou),作者:不寒而栗,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com