
2D头像生成3D虚拟人开视频会,谷歌新作让人难以忍受。









将来人与人之间的交流,是这样吗?
当视频远程会议开始时,许多人不喜欢打开摄像头。即使打开了,每个人都被框在不同的窗口。虽然这种形式使用起来很方便,但总是缺乏一些现场感。
最近,谷歌提出了一项旨在解决这一问题的研究。 ChatDirector 可采用静态技术 2D 头像生成 3D 让大家一起来虚拟人「坐在会议室里」会议,只是看起来有点夸张:

ChatDirector 通过空间视频头像、虚拟环境和自动布局转换,构建了一个真实的虚拟环境。
虽然只是初步研究,虚拟形象的嘴型可以准确匹配,但总觉得有点喜剧效果。这部大片评论说不能紧张:这可能会为在线会议创造一个轻松的氛围。
ChatDirector 这是一项研究原型,它将传统的视频会议转化为使用。 3D 视频头像,共享 3D 情境和自动布局转换。
在此之前,谷歌展示 Visual Captions 和开源的 ARChat,目标是促进即时视觉效果的口头交流。在 CHI 2024 上展现的《ChatDirector: Enhancing Video Conferencing with Space-Aware Scene Rendering and Speech-Driven Layout Transition》其中,谷歌介绍了一种新的原型,通过在空间感知共享大会环境中为所有参与者提供语音驱动的视觉帮助,增强了基于语音驱动的传统基础。 2D 视频会议感受屏幕。
设计思考
谷歌研究人员邀请了来自企业内部不同岗位的十名参与者,包括软件工程师、研究人员和研究人员 UX 设计者,共同探讨影响虚拟会议质量的因素,分析视频会议系统与零距离互动的特点,最后将建议提炼成原型系统的五个基本参考标准:
DC1、通过空间感知可视化来增强虚拟会议环境。同样的空间对于改善视频会议的感受非常重要。实用系统应采用典型的零距离会议形式,在指定座位的桌子周围安排参与者,营造出切实的共同存在感和空间定位感。
DC2、需要提交语音驱动的协助,而不是简单地复制实际会议。鉴于演讲者在小组对话中的频繁变化和话题的快速转换,系统应提供额外的数字功能,让参与者跟进对话过程,积极参与会议。
DC3、再现零距离互动视觉效果。开虚拟会议时,参与者通常会在电脑前保持静止。为了模仿头部旋转、眼睛接触等动态身体动作,系统应该加强他们在屏幕上的动作。这些动作可以作为更有效的跟进对话的提示。
DC4、尽量减少认知负荷。该系统应避免同时显示过多的信息,或者要求用户频繁操作。这种方法有助于防止分心,并允许参与者更有效地倾听和说话。
DC5、确保兼容性和可扩展性。系统应适应标准视频会议设备(如带摄像头的笔记本电脑),以促进广泛应用。这种兼容性还会促进其他生产力功能和工具(如屏幕共享和其他应用)的无缝集成,从而加强系统的整体效用。
空间感知场景渲染 pipeline
为了解决 DC1(虚拟会议环境可视化通过空间感知增强)和 谷歌首先设计了DC5(确保兼容性和可扩展性)的渲染。 pipeline,将人的视觉呈现重建为 3D 肖像头像。
谷歌深度推理轻量级神经网络。 U-Net 上构建了此 pipeline,并且结合自定义渲染方法,这种方法将 RGB 以及深度图像作为输入和输出 3D 肖像头像网格。
该 pipeline 从深度学习 (DL) 从网络开始,利用网络从即时开始。 RGB 在网络摄像机视频中推断深度。然后使用 MediaPipe 自拍分割模型的分割前景,并将处理过的图像送到图像上。 U-Net 神经网络。
在这些图像中,编码器逐渐缩小图像,而解码器将特征分辨率提高到原始分辨率。来自编码器的 DL 为了帮助恢复几何细节,如深层边界和薄结构,特征与具有相同分辨率的相应层相连。
下图所示的自定义渲染方法 RGB 以深度图像为输入,并重建 3D 肖像头像。
研究小组开发了一个视频会议环境,可以感知空间, 3D 远程参与者在会议环境中显示 3D 肖像化身。
每一个本地用户的设备,ChatDirector 会产生:
- 附加由 Web Speech API 音频输入识别语音文本
- 由 U-Net 根据神经网络推断 RGB 图像和深度图像。
与此同时,当系统接收到每一个远程用户的数据时,它将被重建 3D 肖像化身,并显示在当地用户的屏幕上。
为达到视差效果,该团队根据使用情况使用 MediaPipe 人脸检测所检测到的本地用户的头部移动来调整虚拟渲染摄像头。音频将被用作输入语音驱动布局转换算法,该算法将在下一节中解释。
通过数据通信 WebRTC 实现。
ChatDirector 系统结构。
一位本地用户拥有它 3D 视频会议环境角度,肖像头像空间感知。
语音驱动的布局转换算法
为了解决 DC2(提供语音驱动协助,超越现实世界聚会的简单复制)和 DC3(再现零距离互动的视觉线索),研究人员开发了一种决策树算法。
根据正在进行的对话,该算法可以调整渲染场景的布局和化身动作。用户可以通过接受自动视觉辅助来跟随这些对话,然后就不需要了。 在DC4(最小化认知负荷)上浪费额外的能量。
对算法的输入,他们把群聊建模成一系列的语音轮换。
每一刻,每一位参与者都将处于三种语音状态之一:
沉默:与会者正在听别人说话;
与某人交谈(Talk-to):与会者正在与特定的人交谈;具体来说,通过检查参与者的名字(他们加入会议厅时的输入结果),可以测试他们是否在与某人交谈。
宣布(Announce):与会者正在和所有人交谈。使用关键字进行检查(例如「everybody」、「ok, everybody」),Web 语音 API 这种类型的语音状态是自动识别的。
该算法产生了两个关键导出(DC3)来增强视觉辅助。首先是布局状态,它决定了会议场景的整体可视化。
这种方法包括几种:
- 「一对一(One-on-One」,为了直接与本地用户互动,只显示一个远程参与者;
- 「两组对话(Pairwise)」,将两个远程参与者并排排列,表达他们的一对一对话;
- 「全景(Full-view)」,默认设置显示所有参与者,表示一般讨论。
ChatDirector 规划转换算法。
算法导出:布局状态。从左到右分别是:一对一。(One-on-One)声音状态,两组对话(Pairwise)声音状态,全景(Full-view)语音状态。
在线视频会议现在更加逼真,领导和你可以交换眼光。
基于研究团队 3D 肖像化身渲染能力,通过操纵远程化身的动作,模拟类似于零距离大会的对视。
它们将化身状态(Avatar State)为了控制每一个化身的方向,设置为算法的附加导出。
这一设置中,每一个化身都可以处于两种状态:「当地」状态,其中化身旋转面向本地用户,「远程」状态,其中化身转动与另一位远程参与者互动。
定性性能评价:用户研究
研究小组进行了一项实验室研究,以评估基于语音布局转换算法的性能和空间感知会议场景的整体有效性,涉及 16 参与者,分为四个团队。
研究表明,与传统的标准视频会议相比, ChatDirector 与语音处理相关的问题有了明显的改善,这体现在用户对注意力转移辅助的积极评价上。
另外,该团队还对威尔科克森符号秩进行了调查报告。(Wilcoxon Signed-Rank Test )。
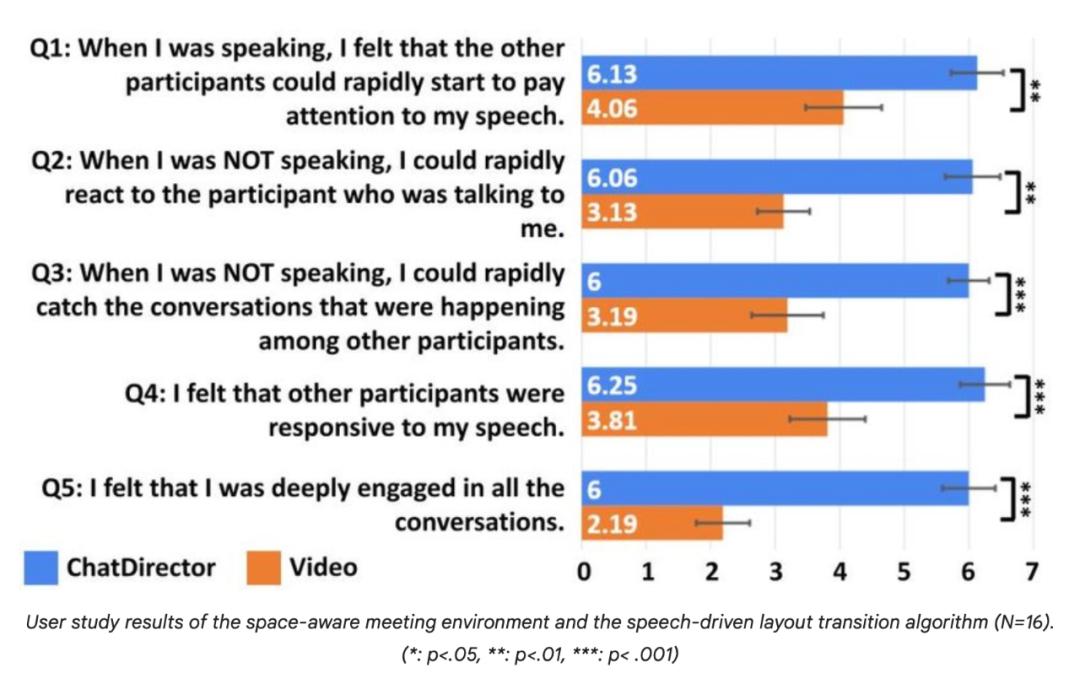
客户对会议环境空间感知和语音驱动布局转换算法的研究结果(N=16)。( *:p<.05, **: p<.01, *** :p< .001)<.05, **: p<.01, *** :p< .001)
此外,根据 Temple Presence Inventory(TPI)评分,以及标准为基础 2D 与视频会议系统相比,它提高了并存感和参与性。
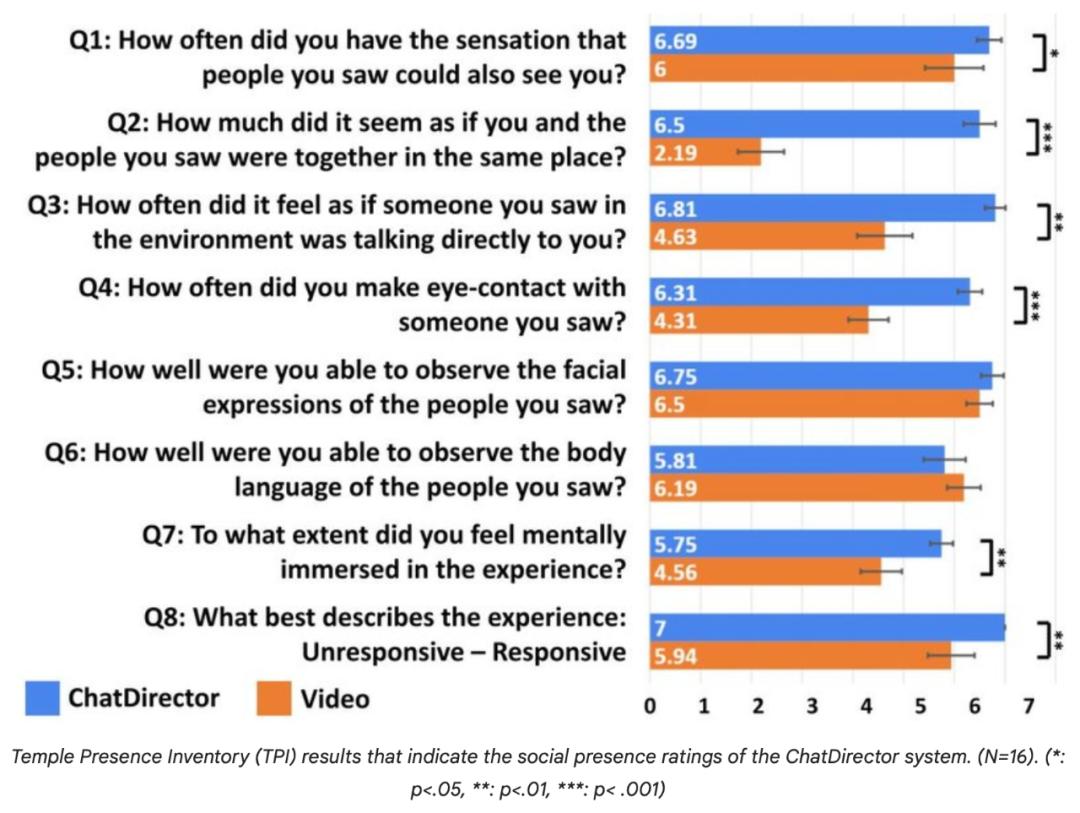
Temple Presence Inventory(TPI)数据显示了 ChatDirector 系统性社会存在评级(N=16)。( *:p<.05, **: p<.01, *** :p< .001)<.05, **: p<.01, *** :p< .001)
因为 ChatDirector 以视频会议室用户肖像化身为基础,人像安全问题将成为未来研发的重中之重。
最后,研究小组表示希望, ChatDirector 在日常计算平台上,可以激发先进的感知和交互技术,以提高共同在场的感觉和参与性,不断创新。
同时,研究人员指出,处理负责任的问题 AI 考虑到它的数字相似性的含义是极其重要的。因为这样转换「用户的视频」这可能会导致他们对自己肖像的控制,因此需要进一步的研究和仔细的考虑。
在安排这类工具时,基于用户的同意和遵守相关道德标准是非常重要的。
这个团队也提供了一个 ChatDirector 交互式技术演示,在视频内容中展示更多 3D 视频示例。
视频链接:https://youtu.beZL48C1Y/mO2rZL
参考链接:https://research.google/blog/chatdirector-enhancing-video-conferencing-with-space-aware-scene-rendering-and-speech-driven-layout-transition/
本文来自微信微信官方账号“机器之心”(ID:编辑:泽南、亚鹂、36氪经授权发布,almosthuman2014)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com