
中美AI发展路径分化:组织与创新的深层观察






本文来自微信公众号:TOP创新区研究院,作者:产业研究组
2026年5月,来自艾伦人工智能研究院AI2的技术研究者Nathan Lambert,只用了36小时就走访了北京中关村、五道口一带多家核心AI实验室——包括DeepSeek、月之暗面、智谱,还有美团、小米的底层研发部门。
回到美国之后,他发布了一篇长文,直接在硅谷引发了轩然大波。
他得出了一个出人意料的结论:
中美AI发展的差距,本质上并不由芯片出口禁令决定,真正影响走向的是一个更隐秘、也更关键的因素:
组织熵增。
如果问现在的OpenAI或者Anthropic,最大的痛点是什么?
答案不是H100芯片,而是“稳定的研发环境”。
这个说法该怎么理解?
Lambert点出了当前硅谷AI行业的一大顽疾:
明星科学家政治。
旧金山湾区的AI实验室里,弥漫着浓厚的“AI救世主”精英心态。
如果顶级研究员提出的模型方案没有被采纳,他们往往不会从团队全局出发调整方向,反而会直接带着整个团队离职,还会在社交平台引发舆论争议,给原公司造成巨大压力。
为了安抚这些头部研究者,硅谷实验室只能用高额股权、虚设高管职位来妥协,内耗不断加剧。
曾经引发Llama团队分崩离析的核心原因,正是这种内部组织内耗。
但在北京的AI园区里,主流的风格是“平民精英协作”。
走进DeepSeek或者月之暗面的研发办公室,你会发现核心研发团队里绝大多数都是二十出头的年轻人。他们刚走出清华、北大、浙大等高校的实验室,没有“拯救世界”的宏大空谈,只有“把每一个问题解决”的务实执着。
这种“新人即核心伙伴”的组织模式,带着近乎极致的工程谦逊,能把每一分算力都用到极致,最终爆发出惊人的研发效率:
在这里,没人会觉得数据清洗、算子优化是低端的“脏活累活”,大家都把这些基础工作当成迭代升级的必经之路。月之暗面创始人杨植麟在团队内推行扁平化沟通——
这里没有副总裁、总监这些层级头衔,只看代码和效果说话。

硅谷在打造AI“造神运动”,北京在搭建AI“作战军团”。
神总会有褪去光环的一天,但军团只会在实战中不断进化。
约束下生长的通用人工智能路径
当外部限制成为技术进化的催化剂
过去两年,美国商务部原本以为,只要掐断高端AI芯片的供应,就能卡住中国AI发展的脖子。但他们忽略了进化论里的一个基本规律:极端严苛的环境,反而会催生出适应力极强的新物种。
当硅谷AI企业习惯了动用几万块H100芯片,用“暴力算力”堆出模型效果的时候,中国的AI实验室在做什么?
他们在显存的每一个字节里,抠出每一分可能的性能提升。
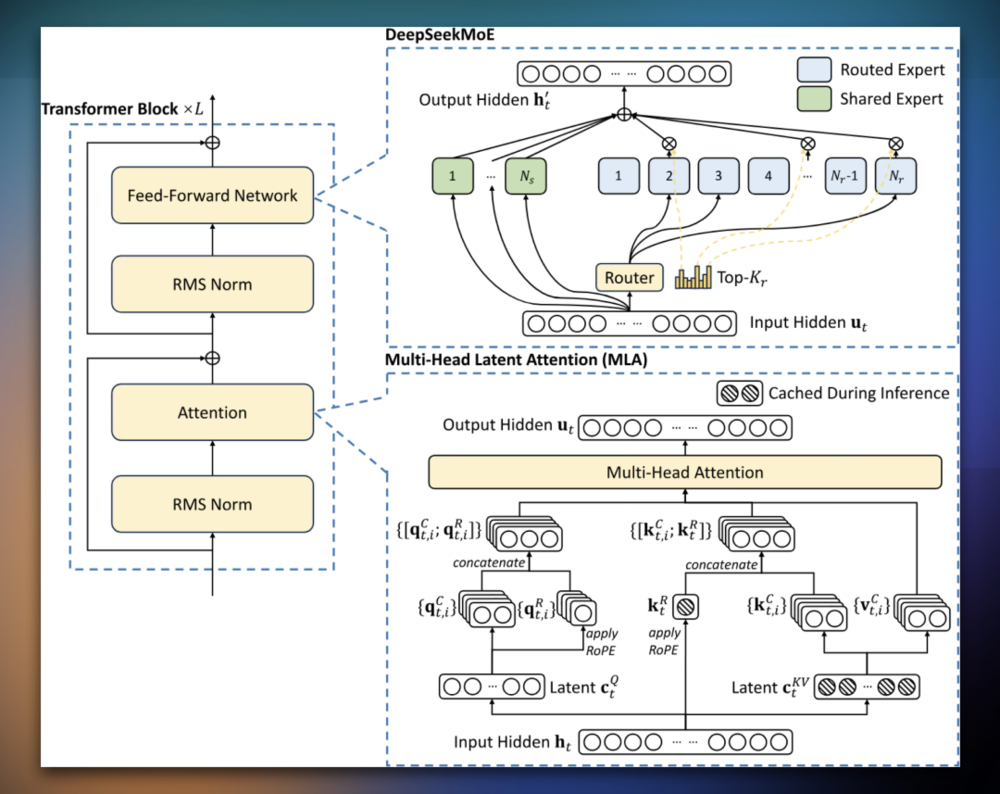
比如多头潜变量注意力MLA技术:
这个精巧的算法设计,本质上就是为了应对算力显存不足的困境诞生的。
还有混合专家模型MoE的异构架构设计:
这套方案就是为了让一两千块旧芯片,跑出堪比几万块新芯片的吞吐量,把现有硬件的潜力榨到极致。
Lambert忍不住感叹:中国AI研究者已经成了全球最顶尖的“算力魔术师”。
更让硅谷感到焦虑的是,
这种“低算力高效能”的技术路径,已经开始反向向外输出。
当全球开发者发现,Kimi K2.5的推理成本只有GPT-4o的几分之一,当代码编辑器Cursor悄悄把底层引擎换成中国大模型的时候,美国原本靠算力构建的AI优势,正在从内部被撼动。

如果只花500万美元就能达到别人5亿美元才能实现的效果,
到底谁才是真正的技术领先者?
开源生态与技术蒸馏:中国AI的棋路
中国AI实验室正在下一盘硅谷完全看不懂的棋。
一位清华大学的副教授曾经说过:
“在中国程序员圈子里,开源已经成了一种共识。”
这句话其实只说了一半。
另一半真相是:
开源是中国AI打破美国技术垄断定价权的核心路径。
硅谷的AI商业逻辑是闭环收费,靠API服务抽取“技术税”;
中国的AI发展逻辑是开源普惠,主动开放模型权重给全球开发者。
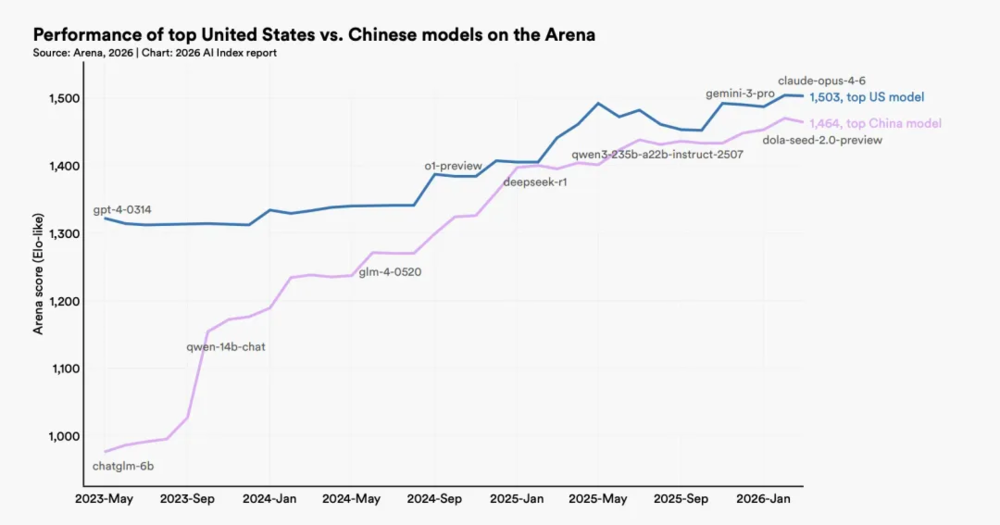
当美国投入数千亿研发AI,中国只用了百亿级投入,就将技术差距缩小到个位数?当阿里、智谱、DeepSeek多次登上Hugging Face开源模型排行榜前列的时候,其实已经向全球传递了一个清晰的信号:
基础大模型应该像空气一样,成为人人可用的公共基础设施。
这种开源浪潮直接打破了硅谷搭建的技术壁垒。
如果一个开发者就能在本地部署一个效果接近Claude、GPT的中国大模型,他为什么还要给硅谷企业交高额的服务费?
这种技术平权的思路,已经让美国的AI垄断变成了一件成本高昂的自我狂欢。
当然,我们也必须直面一个无法回避的问题:
模型蒸馏。

2026年,Anthropic和美国白宫已经因为这个问题破防,
他们指控中国实验室利用蒸馏技术,“工业级窃取”西方模型的技术成果。
前字节跳动研究员张驰也提出了清醒的提醒:
“如果只依赖模型蒸馏和刷排行榜提升排名,我们和真正的源头原发性创新,还有大约三年的代差。”
这是一个必须承认的现实:
中国AI实验室在工程组织效率上已经做到了极致,
但在底层科学原创想象力上,目前还处于跟随学习的阶段。

当下中国AI的繁荣,很大程度上依赖于对西方顶级模型输出数据的二次加工。这种快速追赶的路径虽然能在短期内缩小差距,但也很容易让我们陷入路径依赖的陷阱——
如果未来某一天,OpenAI彻底关闭了所有API输出通道,或者西方所有模型的训练数据都加上了无法清除的投毒标记,我们还能保持今天这样的快速进化速度吗?
工程师导向vs规则导向:AI发展的底层逻辑差异
文章的最后,我们需要回到一个更宏大的议题上:
王丹的“工程师国家”理论。
美国AI的发展方向,是由律师和公关团队定义的;而中国AI的发展方向,是由代码和产业场景定义的。
这也是最近美国精英圈热议的话题:美国的治理体系偏向规则导向,大量环节被法律流程约束,而中国更偏向工程师务实导向……
在美国,每一个新的前沿大模型发布,都要经过漫长的安全检测、法律合规审核、价值观对齐调整。
这些繁复的流程虽然保护了多元价值,却也拖慢了技术迭代的速度。
而在中国,AI被定位成支撑产业升级的核心基础设施。
美团为了优化外卖配送路径自研大模型,小米为了提升智能汽车体验搭建AI底座,AI在中国不是少数企业玩的昂贵资本玩具,而是能实实在在提升各行各业生产效率的工具。

这种扎根产业场景驱动的发展韧性,是硅谷那些在帕罗奥多咖啡馆里空谈“AI意识”的研究者很难理解的。
保持谦逊才是长期领跑的关键
Lambert在返回美国的飞机上,
一直在思考美国AI实验室未来的出路。
他在文章里写道:
“我依然希望美国能保持AI领先,但如果我们不解决明星学者内耗这个烂摊子,不学中国年轻开发者那样沉下心打磨每一个算子,那现在的领先不过是落日余晖罢了。”
而对中国AI从业者来说,
最大的对手不是外部的芯片制裁,
而是“我们已经全面超越硅谷”的盲目乐观。
真正的通用人工智能,绝对不可能只靠模型蒸馏和刷排行榜就能实现。
我们始终相信:
在这场人类历史上最伟大的技术长跑中,
谁能保持大规模组织的高效不涣散,
谁能始终给年轻研究者挑战权威的空间,
谁就能最终赢得这场比赛。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com