
神秘模型MotuBrain斩获双榜世界第一 具身智能领域引发关注






本文来自微信公众号:机器之心,编辑:杨文、陈陈,作者:关注AI的
近期,世界模型赛道异常活跃。
李飞飞创立的空间智能独角兽World Labs推出「Spark 2.0」,阿里紧接着上线世界模型「快乐生蚝」。
几乎同时,Physical Intelligence发布新模型π0.7,强调其对未知任务的初步组合泛化能力与跨机器人平台迁移特性。
这些动态释放出行业信号:竞争焦点已从单点动作实现转向「预测世界」与「驱动行动」的模型统一。
在此节点,一款名为MotuBrain的神秘世界模型悄然登上两个国际基准测试榜首,未标注任何公司署名。
若仅单榜第一或许不足为奇,但它同时拿下的是行业「两极」榜单:衡量世界模型对现实世界理解与预测能力的WorldArena,以及评估机器人任务执行与泛化能力的RoboTwin2.0。前者侧重世界预测,后者侧重任务执行,二者结合正是行业当前力求攻克的统一命题。
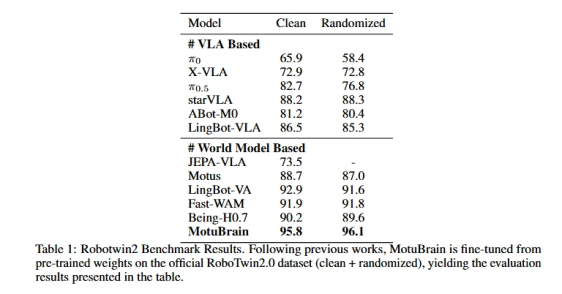
在WorldArena中,MotuBrain以63.77的总体EWM Score位居第一,表现超越高德ABot、极佳GigaWorld-1等模型,在Motion Quality、Flow Score、Motion Smoothness等关键运动维度全面领先。
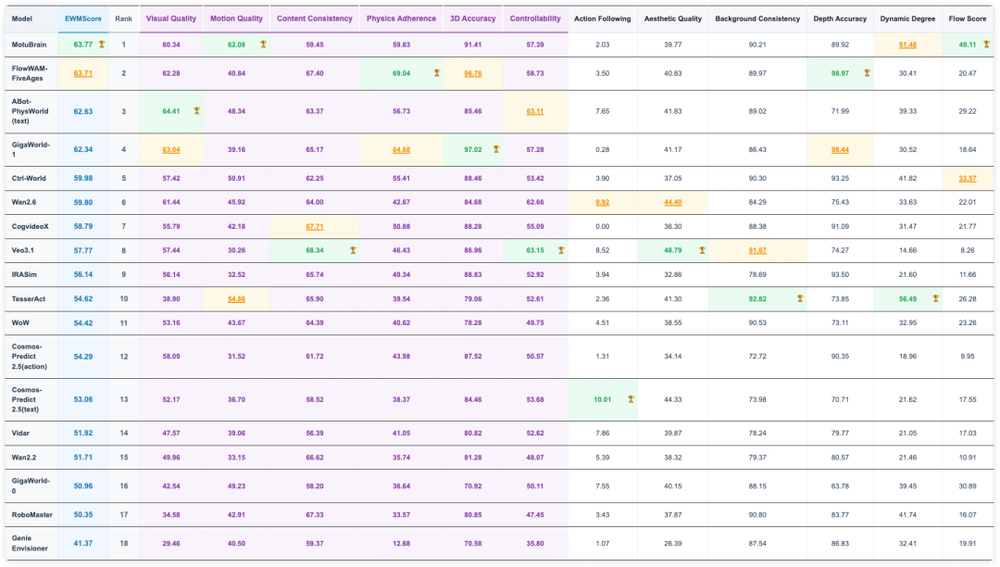
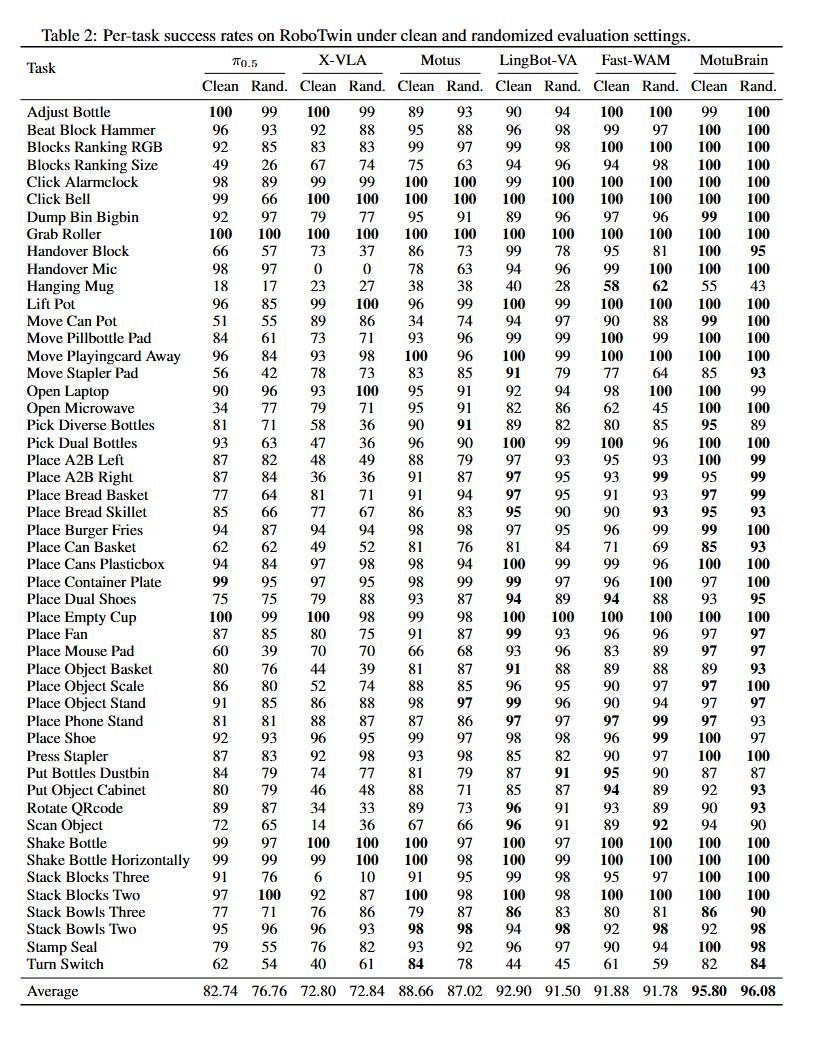
在RoboTwin2.0中,MotuBrain在Clean和Randomized场景下分别取得95.8和96.1的成绩,同样排名第一,是榜单中唯一在随机环境下平均分超95的模型,多数具体任务得分达100或接近100。相比高德ABot、蚂蚁灵波LingBot、JEPA-VLA、pi0.5等模型,MotuBrain在该基准测试中表现出统治级优势。
正是这种「双料第一」,让这款来历不明的模型受到关注。
经简单搜索,目前网上暂无MotuBrain相关信息,但发现了一个本月刚注册的X账号。
这让人联想到前段时间被阿里认领的「欢乐马」(后续也开通了X账号)。
这个神秘世界模型,难道也是国内大厂的作品?
MotuBrain的成绩为何值得关注?
WorldArena和RoboTwin并非同类测试,它们衡量的是不同能力。
WorldArena考察world model维度,包括模型对运动规律的理解、对时间序列物理变化的准确推演与预测,以及对环境状态变化的认知能力,这是预测世界的能力。
RoboTwin则偏向action model或policy model维度,比如模型在多任务、多环境下稳定执行动作的能力,对未知场景的泛化能力,以及持续完成复杂操作的能力,这些是在世界中行动的能力。
打个比方,人类司机能在复杂路况安全驾驶,不仅靠肌肉记忆,更依赖对下一秒情况的持续预判,如前车是否急刹、行人是否横穿。这种预测与行动的同步,是人类智能的底层逻辑。
现有多数机器人系统恰恰缺少这一层。它们要么擅长认知世界却不知如何行动,要么能执行固定动作却对环境变化毫无预判。这种「两张皮」的结果,导致机器人离开训练场景就容易失控。
过去几年,这两个方向各自发展但往往割裂。做视频生成和世界模型的团队关注模型能否真实模拟物理世界;做机器人策略和VLA的团队关注模型在具体任务上的可靠执行。真正尝试将两者统一的工作不多,成果稳定的更少。
MotuBrain能在两类基准测试中同时夺冠,至少在测试层面验证了将预测世界与驱动行动统一于同一模型的可行性。
双料第一,它的优势在哪里?
在WorldArena榜单上,MotuBrain在以下维度的领先值得关注:
Motion Quality第一,意味着模型生成的动作更真实,而非停留在视觉上的动效层面。
Flow Score第一,说明模型对连贯动作和运动轨迹理解更深,能稳定预测大幅度动作变化,实现前后时刻的丝滑衔接,而非逐帧拼凑。
Motion Smoothness第一,代表生成的动作更符合真实物理规律,不会出现不自然的突然加速、抖动或方向跳变。
这三个维度都与运动直接相关,对于服务机器人的世界模型而言,是最关键的能力。
在更侧重任务执行的RoboTwin中,这种优势进一步放大。面对50个任务、两种环境设置,MotuBrain平均得分达96.0,显著高于第二名的92.3,领先幅度几乎相当于第二名到第五名的差距。
更关键的是稳定性。一半任务成功率达100%,九成任务超过90%。这不仅意味着能完成任务,更意味着在多任务和随机扰动环境下仍能稳定复现结果。
这些成绩综合来看,体现出更接近通用机器人大脑的特征:既能保持动作的连续与一致,又具备跨任务的泛化能力。
背后团队与技术路线是什么?
目前MotuBrain的公开信息极少,但从双榜成绩结构推测,其背后大概率不是传统视频模型,也不是单纯的VLA或policy model。
过去一年,行业围绕world model和action model的探索形成了几条代表性路线:
有的强调统一世界模型,通过视觉、语言、视频与动作的联合建模,融合视频模型、VLA、世界模型等路线,实现对真实环境的感知、规划、预测、执行和跨任务泛化,典型代表是去年12月发布的Motus。
有的偏向「先想象、再行动」路径,如今年1月底发布的Lingbot-VA,先用视频模型预测未来视频,再反向指导机器人动作决策,二者融合于同一模型。
还有一些采用「同步推演未来状态+生成动作」的World Action Model,边推演边行动,比如英伟达二月初发布的DreamZero。
从MotuBrain的表现来看,它可能走了World Action Model路线,兼具world model对环境和未来状态的推演能力,以及action model在真实任务中的执行能力。
这也解释了它为何能同时在「世界建模」和「动作执行」两类基准测试中登顶。
结语
若将机器人拆解,「手脚」是硬件,「大脑」是软件。
过去几年,机器人硬件迭代迅速,运动控制更精准,传感器更丰富,成本更低。但制约机器人大规模落地的,是指挥任务的「大脑」。
当前机器人本质上仍是「为特定任务训练的专用系统」,换场景、物体或指令就可能失效,这很大程度上源于智能问题。
具身智能的目标是构建统一模型,既能理解物理世界、预测状态变化,又能生成可靠动作,适配任意任务与场景。
资本已用实际行动给出判断。
观察近期大额融资可发现,资金正密集流向打造机器人「大脑」的公司。表面是投机器人,实则抢占下一代「机器人操作系统」或「通用物理大脑」的入口。
由此可见,以MotuBrain为代表的world+action统一架构,正处于这场卡位战的核心位置。
至于MotuBrain背后的团队及后续动态,这个疑问或许很快就能解开。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com