
DeepSeek再夺榜首:创新「因果流」视觉推理技术,性能超越Gemini






【导读】DeepSeek推出开源模型DeepSeek-OCR2,其核心亮点是引入了全新的DeepEncoder V2视觉编码器。该架构突破了传统模型固定从左上到右下扫描图像的局限,转而模仿人类视觉的「因果流(Causal Flow)」逻辑进行信息处理。
DeepSeek又带来了新动态!
此次是DeepSeek-OCR模型的重大升级版本:DeepSeek-OCR2。

大家是否还记得上一代DeepSeek-OCR?就是那个以视觉方式实现极致压缩的模型。
这一次,DeepSeek更进一步,对视觉编码器进行了优化,提出了全新的DeepEncoder V2架构,推动视觉编码实现从「固定扫描」到「语义推理」的范式革新!
DeepSeek-OCR2不仅能像人类一样按照逻辑顺序阅读复杂文档,还在多项基准测试中刷新了SOTA成绩。
按照DeepSeek的一贯风格,相关的论文、代码和模型已全部开源!
项目地址:https://github.com/deepseek-ai/DeepSeek-OCR-2
模型下载:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文地址:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
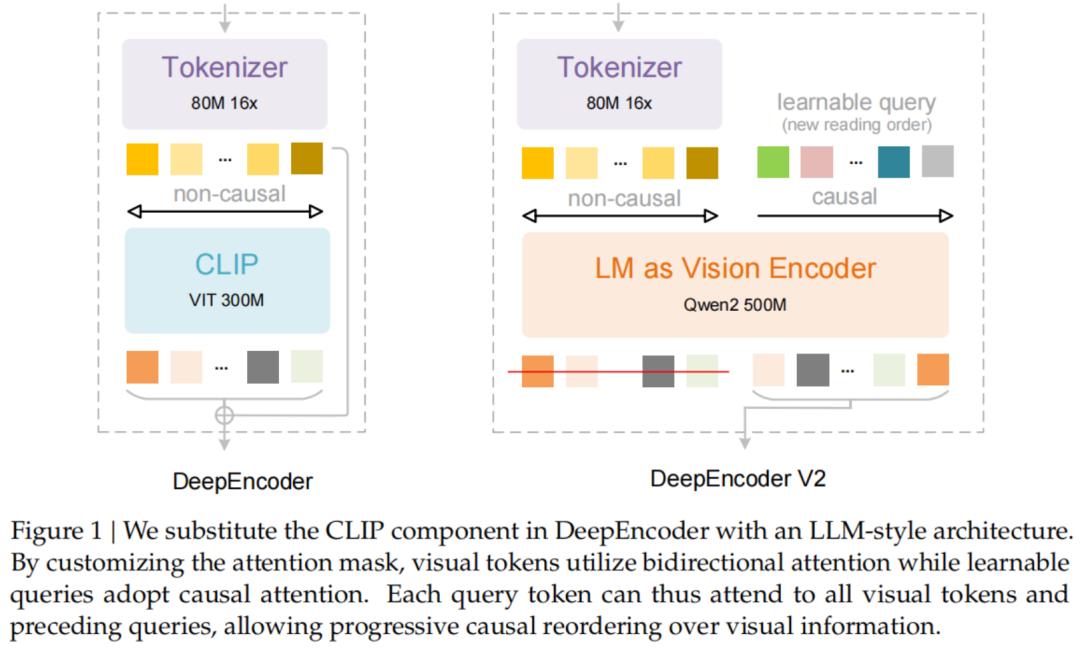
DeepSeek-OCR2的核心创新点在于,通过DeepEncoder V2为模型赋予了因果推理能力(Causal Reasoning)。
这相当于给机器植入了「人类的阅读逻辑」,让AI不再机械地从左上到右下扫描图像,而是能够根据内容语义灵活调整阅读顺序。
DeepSeek-OCR2:开启视觉因果流时代
DeepSeek在论文中提到,传统的视觉语言模型(VLM)通常采用光栅扫描(Raster-Scan)顺序处理图像,也就是固定地从左到右、从上到下进行扫描。
这种方式会强行将二维图像压缩成一维序列,从而忽略了图像内部的语义结构。
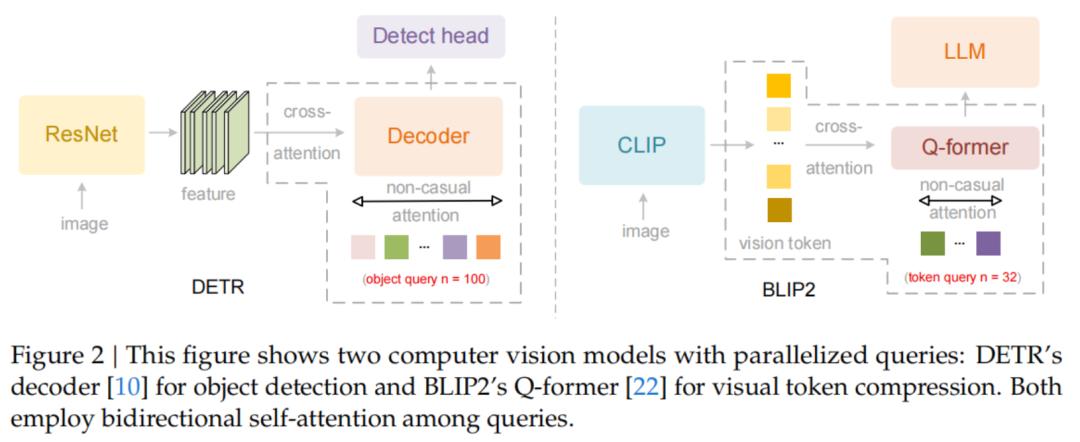
这显然与人类的视觉习惯不符。
人类在查看图片或阅读文档时,目光会随着逻辑流动:先看标题,再看正文,遇到表格会按列或按行扫视,遇到分栏会自动跳跃阅读。
为解决这一问题,DeepSeek-OCR2引入了DeepEncoder V2。
它最显著的特点是用轻量级大语言模型Qwen2-0.5B替代了原本的CLIP编码器,并设计了独特的「因果流查询」(Causal Flow Query)机制。
DeepEncoder V2架构解析
DeepEncoder V2主要由两部分构成:
1. 视觉分词器(Vision Tokenizer)
延续了SAM-base(80M参数)搭配卷积层的设计,可将图像转换为视觉Token。
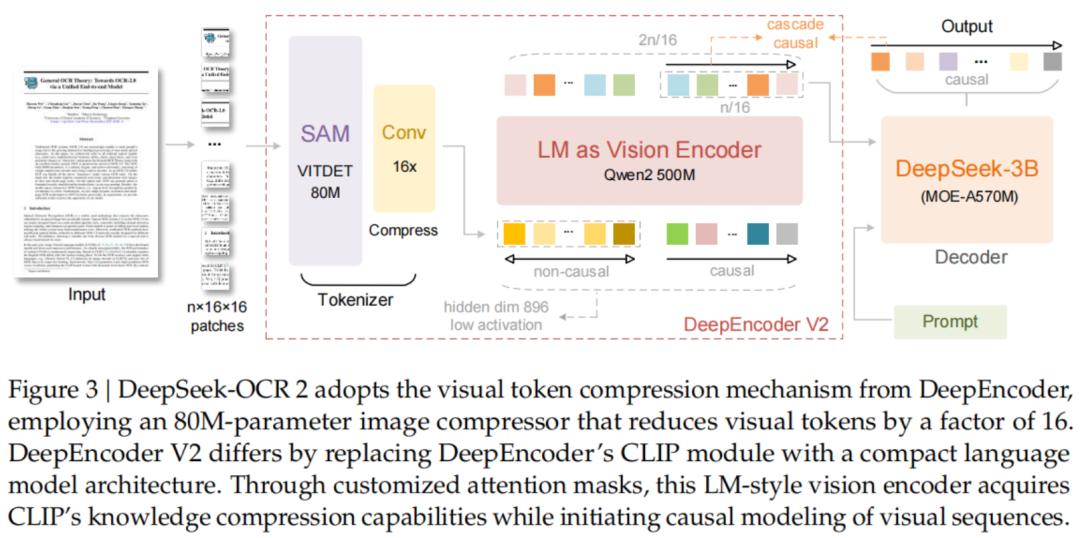
2. 作为视觉编码器的LLM
这里DeepSeek采用了Qwen2-0.5B模型。
该模型不仅能处理视觉Token,还引入了一组可学习的「查询Token」(Query Tokens)。

关键的创新之处在于注意力掩码(Attention Mask)的设计:
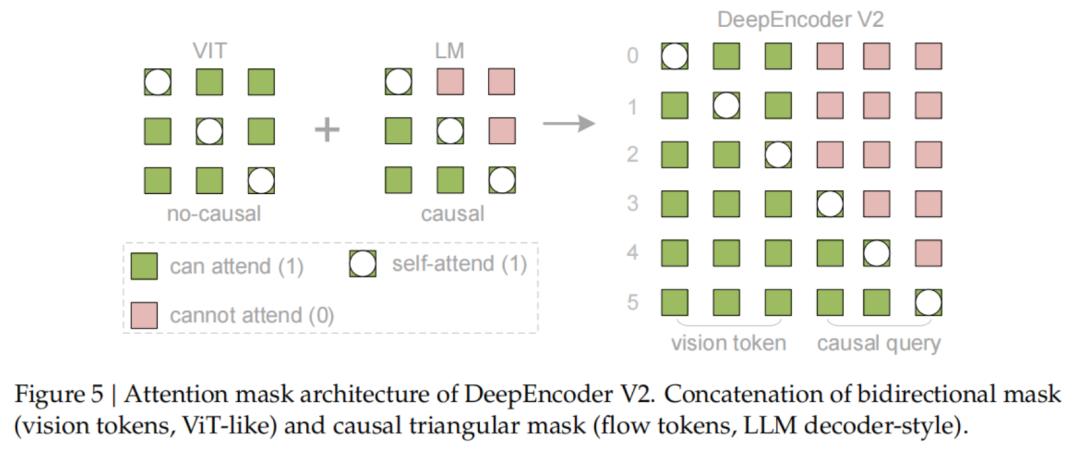
视觉Token之间采用双向注意力(Bidirectional Attention),保留了全局感知能力,与ViT类似。
而查询Token则采用因果注意力(Causal Attention),每个查询Token只能关注到它之前的Token。
通过这样的设计,DeepEncoder V2实现了两级级联的因果推理:
编码器借助可学习的查询对视觉Token进行语义重排,之后的LLM解码器在这个有序序列上进行自回归推理。
这意味着DeepSeek-OCR2在编码阶段就已经将图像中的信息「梳理通顺」,而非直接一股脑地传递给解码器。
Token数量减少,识别精度提升
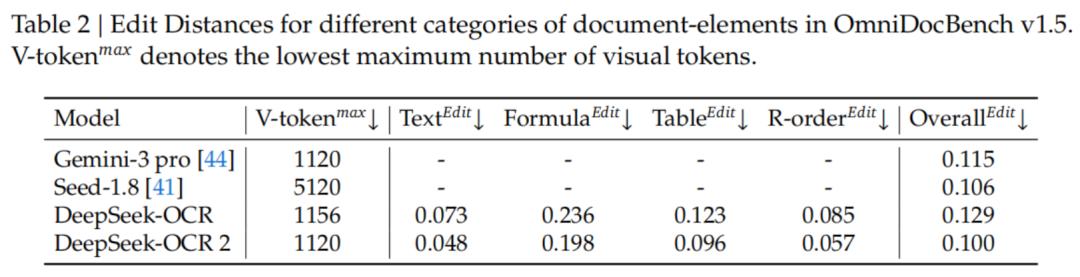
实验数据表明,DeepSeek-OCR2在保持高压缩率的同时,性能得到了显著提升。
在OmniDocBench v1.5基准测试中,DeepSeek-OCR2使用最少的视觉Token(仅256-1120个),综合得分达到91.09%,相比上一代提升了3.73%。
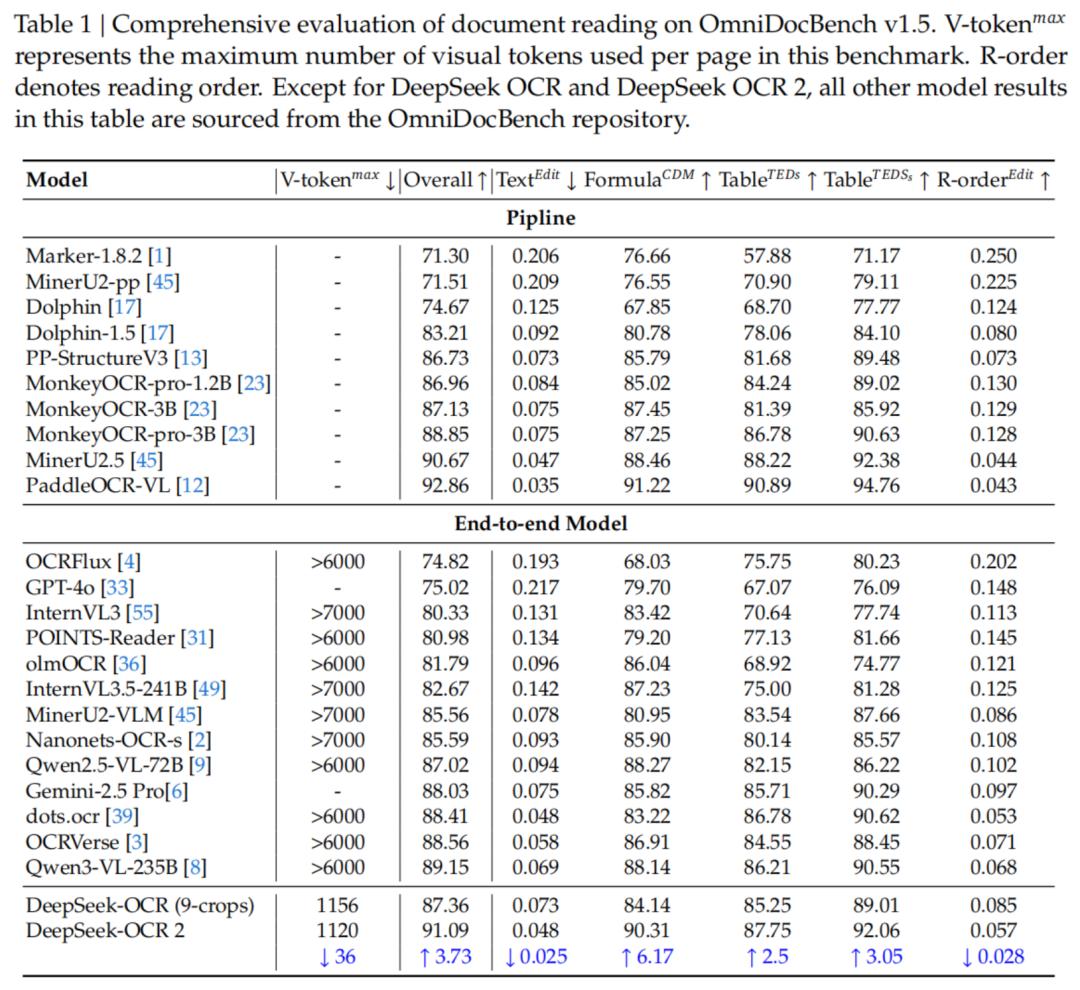
值得注意的是,在阅读顺序(R-order)的编辑距离(Edit Distance)指标上,DeepSeek-OCR2从上一代的0.085大幅降至0.057。
这直接证明了新模型在处理复杂版面时逻辑性更强,更能理解「阅读顺序」。
与Gemini-3 Pro等闭源强模型对比时,DeepSeek-OCR2也表现出色。
在均使用约1120个视觉Token的情况下,DeepSeek-OCR2的文档解析编辑距离(0.100)优于Gemini-3 Pro(0.115)。
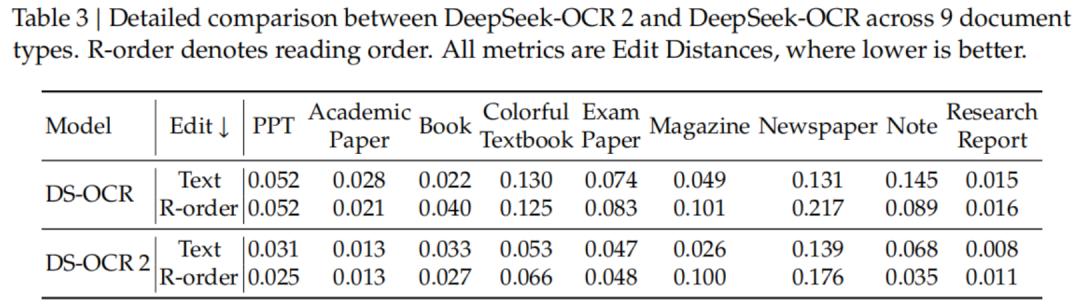
DeepSeek-OCR2不仅在测试中表现优异,在实际生产环境中也具备很强的实用性。
DeepSeek透露,在处理在线用户日志图像时,OCR结果的重复率从6.25%降至4.17%;在PDF数据生产场景中,重复率从3.69%降至2.88%。

这表明模型生成的文本更加精准、整洁,对于LLM训练数据的清洗流水线具有重要价值。
向真正的多模态统一迈进
DeepSeek在论文结尾提到,DeepSeek-OCR2通过DeepEncoder V2验证了「LLM作为视觉编码器」的可行性。
这不仅是OCR模型的一次升级,更是迈向原生多模态(Native Multimodality)的关键一步。
未来,同一编码器只需配备不同的模态查询嵌入(Query Embeddings),就能处理文本、图片、音频等多种模态数据,真正实现万物皆可Token、万物皆可因果推理。
DeepSeek表示,尽管目前光学文本识别(OCR)是LLM时代最实用的视觉任务之一,但这只是视觉理解领域的一小部分。
DeepSeek将继续探索,朝着更通用的多模态智能方向发展。
参考资料:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
本文来自微信公众号“新智元”,编辑:定慧 好困,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com