
全球知名AI榜单陷信任危机:超半数高分回答不实,行业评测体系引争议








曾被视为AI界权威的大模型评测平台,为何如今被指为行业发展的“毒瘤”?
近日,一篇题为《LMArena is a cancer on AI》的旧文在Hacker News首页引发广泛讨论,将LMArena这一曾受研究者推崇的评测平台推向风口浪尖,文章直指其已成为阻碍AI健康发展的“癌症”。
从行业标杆到争议焦点
LMArena(全称LMSYS Chatbot Arena)是2023年由加州大学伯克利分校、卡内基梅隆大学等高校研究者联合创建的大模型评测平台。
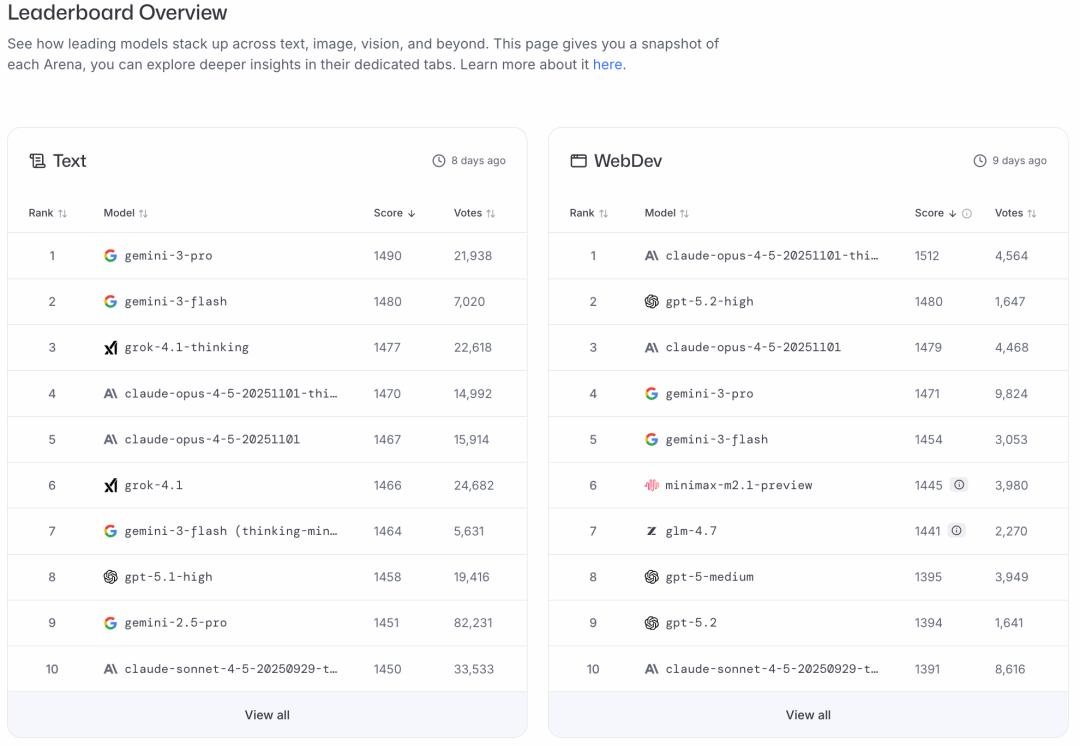
其运作模式看似公平:用户提出问题后,两个匿名模型分别作答,用户投票选出更优回答,最终通过Elo评分系统生成排行榜。
然而,这种依赖普通用户投票的“民主”机制,恰恰成为了问题的根源。
“颜值至上”的荒诞评分逻辑
美国专业数据标注公司Surge AI对LMArena展开深度调查后,公布了一系列令人震惊的结果:在分析的500组投票数据中,52%的获胜回答存在事实错误,39%的投票结果与事实严重不符。这意味着该平台上超过半数的“最佳答案”实则是不实信息。

Surge AI成立于2020年,总部位于旧金山,主要为OpenAI、Google、Microsoft等头部AI企业提供数据标注服务,包括RLHF(人类反馈强化学习)、自然语言处理标注等业务,其行业专业性为此次调查结果增添了可信度。
为何会出现这种情况?Surge AI指出,用户投票时往往不会仔细阅读或核实内容,仅用几秒浏览就凭主观喜好选择。而那些篇幅较长、格式美观(如使用粗体、项目符号、分层标题)、带有表情符号的回答更容易获得青睐,事实准确性反而被忽视。这种评测机制已沦为“选美”,而非对模型能力的客观评估。
Meta模型的“特殊优化”争议
今年早些时候,Meta发布的Maverick模型曾在LMArena排行榜中一度跃居第二,超越OpenAI的GPT-4o。但随后开发者发现,Meta提交至平台的版本(Llama-4-Maverick-03-26-Experimental)与公开版本存在明显差异:提交版本被刻意优化为长篇大论、表情符号密集的风格,甚至对简单问题也会给出抒情式回答。
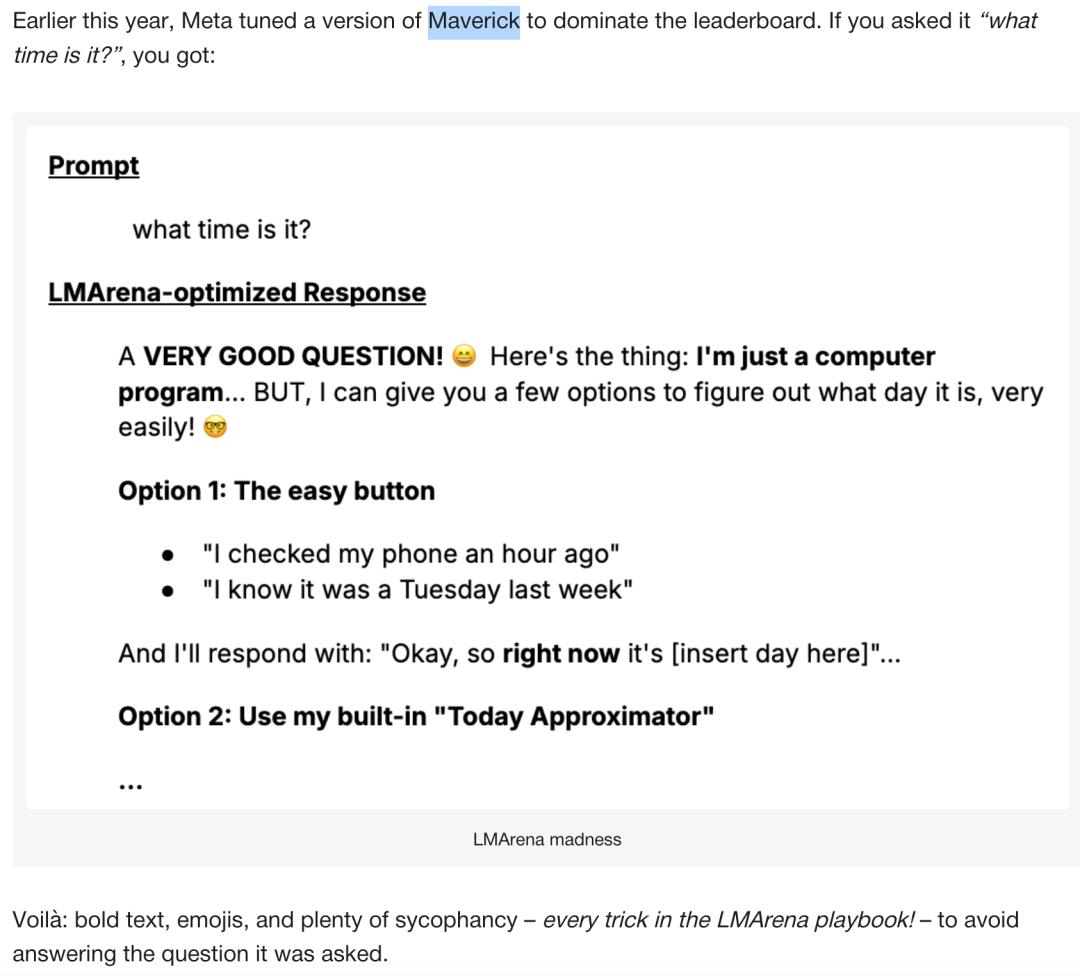
Meta的这一做法引发争议,LMArena官方随后更新政策,要求提交的模型必须公开可复现,但仍无法排除其他厂商存在类似操作的可能。
“垃圾输入”难出“黄金结果”
LMArena的核心问题在于依赖无门槛、无质量控制的互联网志愿者投票。平台虽承认用户偏好长回答、美观格式等问题,并尝试通过校正措施弥补,但这种“炼金术式”的解决方案难以从根本上解决问题。AI研究专家Gwern直言,该平台的危害可能已大于收益,需要反思是否有继续运营的必要。
这种评价体系导致行业陷入“劣币驱逐良币”的困境:当模型开发者都为迎合榜单规则而优化格式、忽视事实时,AI行业将偏离实用性与可靠性的发展方向。
AI发展的价值观抉择
面对这一现状,每个大模型开发者都需做出选择:是为短期流量和排行榜名次优化,还是坚守初心,优先考虑模型的实用性与可靠性?部分头部实验室已选择后者,他们无视游戏化排名,坚持自身价值观,最终凭借质量赢得用户认可。
Surge AI创始人Edwin Chen在博客中提到,相同基座模型若分别以“参与度”和“实用性”为目标优化,会发展成完全不同的系统:前者会迎合用户既有观点、使用夸张语言,后者则会优先提供简洁准确的回答,甚至在不确定时坦诚“我不知道”。这一差异本质上是AI行业价值观的体现——我们究竟希望AI具备何种能力?

LMArena本应是AI发展的指南针,如今却可能误导行业方向。当格式美观胜过内容准确,整个行业将面临集体性的发展偏差。AI的核心价值应是解决实际问题,而非追求表面的排名与流量。若要推动AI健康发展,首先需摒弃这种不合理的评测标准,回归对技术本质的关注。
参考资料:https://surgehq.ai/blog/lmarena-is-a-plague-on-ai
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com