
Gemini助力谷歌AI重回巅峰,百度阿里能否复制其成功路径?








若仅回顾过去一个月,很难将当下的谷歌与2023年因Bard失误遭全球科技圈群嘲的那家公司联系起来。
上周(11月18日),谷歌发布新一代大模型Gemini 3,凭借强劲性能超越同类大模型,基于Gemini 3 Pro的Nano Banana Pro延续了谷歌在AI图像生成领域的领先地位,也让OpenAI倍感压力。
不仅如此,Gemini 3彻底打破了“谷歌掉队”的说法,自研TPU芯片被视为挑战英伟达算力霸权的重要力量。有消息称Meta正评估大规模采购TPU,直接导致英伟达股价下跌近7%。随后英伟达在X(原Twitter)发文回应:
“我们为谷歌取得的成就感到欣喜——他们在AI领域实现了重大突破,我们也将继续为谷歌云提供产品支持。”

与此同时,Anthropic(Claude)上月刚宣布订购百万级谷歌TPU,OpenAI联合创始人、前首席科学家Ilya Sutskever新创立的SSI也在年初选择谷歌TPU作为算力支撑。
事实上,这一切不仅源于从Gemini 2.5到Gemini 3的“模型胜利”,更得益于谷歌的另一种优势——体系化能力的成功。曾经被认为“节奏慢”“架构重”的Gemini、TPU、谷歌云、Android、谷歌搜索组合策略,如今展现出强大的竞争力。
行业态度的转变十分显著。
今年之前,外界普遍认为谷歌“老态尽显”“官僚化严重”;如今则一致看好其“节奏稳健”“产品线协同”“技术底座开始释放潜力”。甚至有分析师称谷歌为“觉醒的巨人”,暗示其可能重新定义整个行业的技术路线。
不过,真正戏剧性的并非当下的赞誉,而是与过去的巨大反差。两年前,谷歌还因Bard失误公开道歉,被当作大模型时代失败的典型案例;如今却成为行业追捧的对象。
从被群嘲到受追捧,谷歌究竟如何实现这一转变?
ChatGPT敲响警钟,但核心路线未变
2022年底ChatGPT的横空出世,给作为Transformer架构设计者、当时如日中天的谷歌带来了强烈冲击。
基于Transformer架构和扩展法则,GPT-3.5让全球首次意识到通用大模型的潜力。谷歌内部反应比外界预想的更为激烈:搜索团队紧急成立“Code Red”应急小组,DeepMind与Google Brain反复研讨技术路线,管理层连续数周加班开会,内部邮件中甚至弥漫着焦虑情绪:
“若再不加快步伐,我们将被历史淘汰。”
在此背景下,Bard仓促上线,问题频发,甚至因一条错误回答导致谷歌市值蒸发千亿美元,社交媒体和科技圈纷纷质疑谷歌“是否还能跟上时代”。当时更关键的是行业判断:
谷歌失去了发展节奏,躺在过往成就上,被OpenAI打了个措手不及。
这便是“谷歌掉队论”的开端。但真正的转折点在于,谷歌在最受质疑的时期并未改变核心路线。自2016年提出“AI优先”战略后,谷歌持续投入业内最全面、最系统的“全栈式AI”路线:
作为全球第三大云计算厂商运营全球数据中心,自研AI芯片(TPU),自主训练大模型,还开发了Nano Banana、NotebookLM等AI应用。

更不用说谷歌拥有全球最大规模的搜索场景、Google Photos、YouTube等平台的海量多模态训练数据。这些看似“不亮眼”“非爆发式”的长期工程,在ChatGPT的冲击下并未被放弃。
所谓“掉队”并非方向错误,而是路线周期较长。既然方向正确,就不应更换,而是加大投入。因此,在经历ChatGPT冲击和Bard失败后,谷歌也迎来了最剧烈的调整期。
“谷歌式全栈”:十年布局,一朝见效
首先是曾经被认为“不可能”的整合实现了:2023年4月,Google Brain与DeepMind合并为统一团队,这两支全球顶尖研究力量被整合在一起,由主导开发AlphaGo的DeepMind创始人Demis Hassabis(杰米斯·哈萨比)统一指挥路线与节奏。

对外宣称是“整合资源”,但业内皆知,这实则打破了谷歌内部长期存在的路线分歧与组织壁垒。“AI优先”战略喊了多年,直到此次重组,才真正实现“力出一孔”。
与此同时,谷歌过去十年搭建的技术底座开始显现价值。TPU原本是为谷歌自身服务的芯片,最初用于搜索和广告的推理加速,随后逐步支撑内部模型训练。大模型时代到来后,这一优势成为行业变量,也是谷歌与其他大模型厂商的核心差异之一。
特别是ChatGPT出现后,TPU v5、v6、v7(Ironwood)的迭代节奏明显加快、规模扩大。从Anthropic开始,谷歌也将自研芯片推向外部商用,从本地训练、云部署到专线算力、TPU@Premises等方案,逐步提升谷歌云的竞争力。

而从Bard到Gemini的升级,本质上也是一次“架构统一工程”:从运行在Pixel和Chrome上的Gemini Nano,到侧重吞吐与延迟的Gemini Flash,再到性能最强的Gemini Pro,背后共享同一套架构、训练方法和评测体系。
这套统一体系让Gemini 2.5在推理和多模态能力上重返第一梯队,也让Gemini 3在视觉、语音、文本和代码理解上实现全面进化。谷歌过去被诟病的“慢”,实则是为统一路线铺路,并非缺乏方向。
体系成型后,最终需落地到产品上才能体现价值。Bard失败后,谷歌意识到模型的核心价值及盲目AI化的问题,选择了差异化优先级路线。
最激进的突破在搜索领域:不仅支持AI预览,还正式上线AI模式。Pixel手机是谷歌AI化改造的另一重点,云端与设备端不同尺寸、不同设计目标的Gemini模型,在影像、翻译、信息处理及语音助手体验上带来质的提升,Magic Cue智能信息提示更是手机AI化的关键方向之一。
与现有产品的AI化改造不同,NotebookLM和Nano Banana作为原生AI应用代表,探索了谷歌在AI时代的新路径:一个重构学习与知识管理,一个将视觉生成推向更轻量、快速、自由的方向。
可以说,过去十年谷歌将芯片、模型、云基础设施、搜索规模、移动端生态、视频图像数据整合成一套体系。这套体系看似笨重缓慢,但当模型能力、算力底座与产品矩阵在同一路线上协同时,便形成了难以复制的整体优势。
百度、阿里能否复制谷歌式“反转”?
若将国内近两年的大模型竞争放在同一维度,豆包的领先已不是“速度优势”,而是彻底拉开与追赶者的差距。
QuestMobile数据显示,今年第三季度豆包App月活达1.59亿,超越DeepSeek,遥遥领先其他AI应用;火山引擎公有云大模型调用量份额逼近一半,日均token调用量突破30万亿。
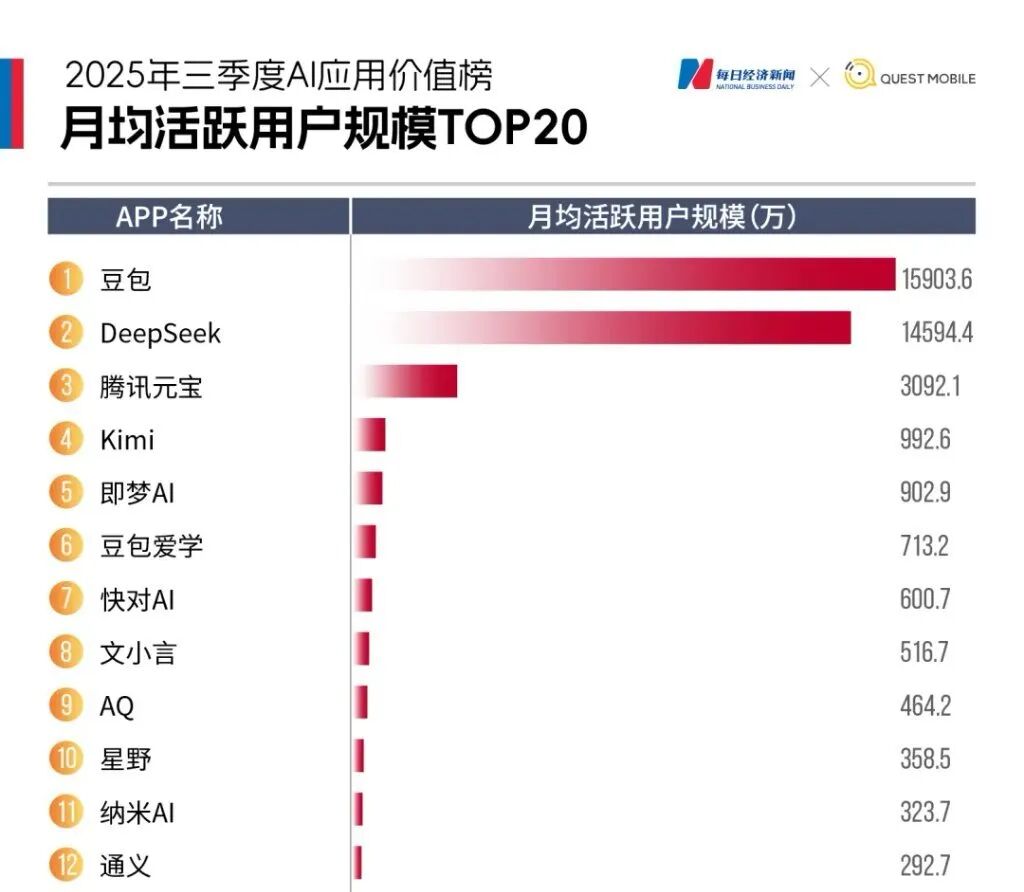
规模效应带来的滚雪球效应,让豆包在用户侧、应用生态和模型调用上形成“越用越强”的正循环。
但从更高维度看,豆包的领先并不意味着竞争已尘埃落定。谷歌的案例表明,决定胜负的从来不是单次爆发,而是体系化能力。阿里近两年在模型、算力、开源和应用层的布局,使其成为国内最有可能实现“谷歌式反转”的玩家。
千问App的爆发只是表层信号。真正支撑它的是阿里过去两年在全球开源社区建立的Qwen模型影响力,以及大规模基础设施投入带来的底层优势。
从Qwen2.5到Qwen3-Max的路线,将模型推理、多模态和代码能力提升至国际一线水平;Qwen在Hugging Face、GitHub的累计下载量位居全球前列,多次登上全球开源榜。
阿里今年明确以千问取代通义,将底层能力压缩为C端入口,让技术体系首次具备向大众规模化输出的可能。

某种程度上,千问当前状态类似谷歌此前阶段——模型强劲、生态深厚、入口初成,真正的考验才刚刚开始。
百度虽在产品节奏,尤其是C端产品上稍慢,但技术底座依然扎实。文心5.0原生全模态架构、万亿参数规模与昆仑芯的深度绑定,使其在技术完整性上保持独特地位;AI云、城市级业务、自动驾驶体系则让其在To B/To G领域拥有难以复制的纵深。
不过,体系化投入不会自动转化为C端用户规模,中间仍需突破诸多环节。
对比国内三家企业,更能理解谷歌的启示意义:豆包证明“规模本身就是能力”,是最直接的增长飞轮;阿里证明开源、全栈和生态深耕可在关键时刻形成反转势能;百度则证明技术底座的完整性永不过时,只是需等待足够大的应用窗口将体系推向台前。
国内竞争远未结束,真正决定未来的或许不是谁跑得最快,而是谁能将模型、算力与应用整合成完整路径。
本文来自微信公众号“智能Pro”,作者:冬日果酱,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com