
ICLR 2026 现 SAM 3:让模型理解「概念」,迈向分割新高度





Meta 的「分割一切」技术有了新进展?SAM 3 能根据你说出的概念,精准描绘出所有出现位置的边界。
9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登上 ICLR 2026,引发网友广泛关注。

- 论文标题:SAM 3: Segment Anything with Concepts
- 论文地址:https://openreview.net/forum?id=r35clVtGzw
大家普遍猜测这篇论文出自 Meta,因为其文风和 Meta 以前发布的论文很相似。而且 SAM 与 SAM 2 都是 Meta 推出的,所以外界基本确定,SAM 3 是 Meta「Segment Anything」系列的正式续作。

从时间节点来看,这篇论文的出现也契合 Meta 的节奏。2023 年 4 月,SAM 1 发表,获得当年 ICCV 最佳论文提名,其(零样本)分割一切的概念让研究者惊叹,被誉为 CV 领域的「GPT - 3 时刻」。2024 年 7 月,SAM 2 发表,它在前作基础上,将图像和视频分割功能统一到一个强大的系统中,能为静态图像和动态视频内容提供实时、可提示的对象分割。如今,一年过去,SAM 3 的登场正当时。
那么,SAM 3 有什么新进展呢?它被定义为更高级的「可提示概念分割(Promptable Concept Segmentation, PCS)」任务。该任务将文本和/或图像范例作为输入,为每个与概念匹配的对象预测实例掩码和语义掩码,同时保持视频帧之间对象身份的一致性。其重点是识别原子视觉概念,所以输入文本被限制为简单的名词短语,如「红苹果」或「条纹猫」,只要描述想要的东西,它就能在图像或视频中找到并分割出每个对应实例。这意味着分割技术学会了理解语言,能根据概念精确描绘出边界。
有人会问,SAM 1 也有文本功能,这次有什么不同?论文指出,SAM 1 中文本提示功能「未完全开发」,SAM 1 和 SAM 2 实际重点在于「视觉提示」(如点、框、掩码),它们无法解决找到并分割输入内容中某一概念所有实例的更广泛任务。简单说,SAM 3 让用户从「手动一个个点出来」升级到「告诉模型一个概念,它帮你全部找出来」。


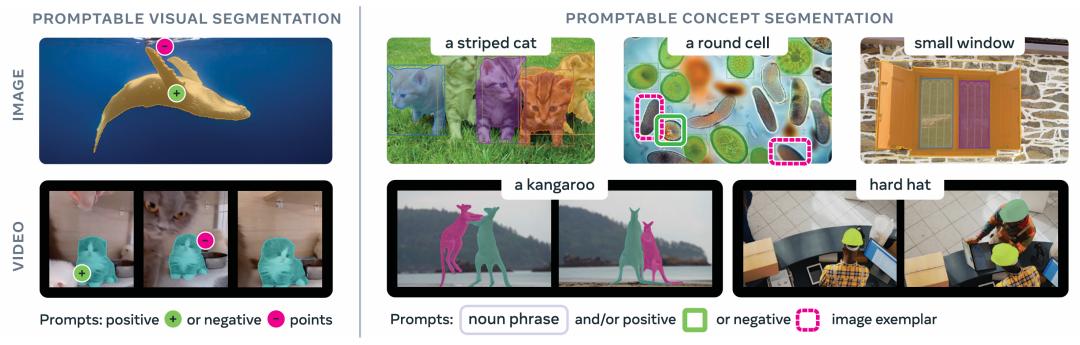
SAM 3 在两方面取得进步。在通过点击进行可提示视觉分割方面,性能优于 SAM 2;在可提示概念分割方面也有进展,用户可通过简短名词短语、图像范例或两者组合指定视觉概念并分割出所有实例。在论文提出的新基准 SA - Co 上,SAM 3 的性能比之前系统提升至少 2 倍,在多个公开基准测试上取得 SOTA 成绩。例如,在 LVIS 数据集上,其零样本掩码平均精度达到 47.0,而之前最佳纪录是 38.5。同时,模型在单个 H200 GPU 上处理一张有超 100 个物体的图像仅需 30 毫秒。
不过,评论区也有质疑声。有人指出,根据文本描述分割物体的想法不新鲜,学术界早有「指代分割」的研究,认为这项工作只是「重新命名」和包装旧概念。还有评论认为,Meta 是在「追赶」开源社区步伐,因为社区早已通过组合不同模型实现类似功能。

方法介绍
文中提到,SAM 3 是对 SAM 2 的扩展,在图像与视频的可提示分割上有重大突破。与 SAM 2 相比,SAM 3 在可提示视觉分割(Promptable Visual Segmentation,PVS)上表现更优,还为可提示概念分割(Promptable Concept Segmentation,PCS)设定了新标准。
简单来说,SAM 3 接收概念提示(如简单名词短语、图像示例)或视觉提示(如点、框、掩码)来定义需进行时空分割的对象。本文重点是识别原子级视觉概念,用户可通过简短名词短语、图像示例或二者组合,分割指定视觉概念的所有实例。
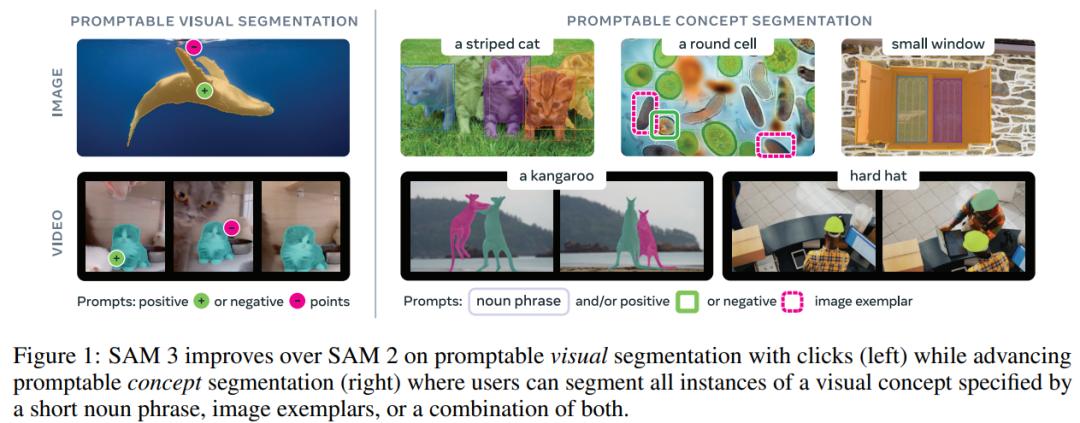
但 PCS 存在固有模糊性,很多概念有多重释义,如「小窗户」就很主观且边界模糊。针对此问题,Meta 在数据收集、指标设计和模型训练等阶段进行了系统化处理。和前代 SAM 版本一样,SAM 3 保持完全交互性,允许用户添加优化提示消除歧义,引导模型生成预期输出。
在模型架构上,SAM 3 采用双编码器 - 解码器 Transformer 架构,这是一个有图像级识别能力的检测器,结合跟踪器和内存模块可应用于视频领域。检测器和跟踪器通过对齐的感知编码器(PE)主干网络接收视觉 - 语言输入。
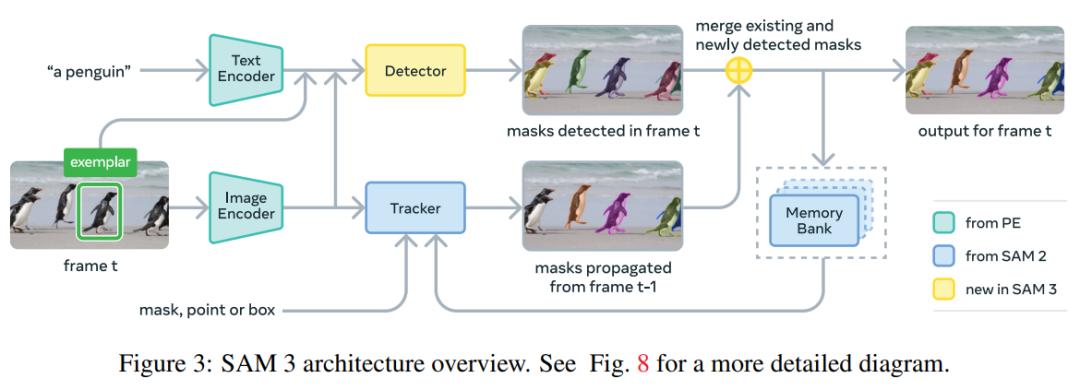
此外,该研究构建了可扩展的人机协同数据引擎,用于标注大规模多样化训练数据集。基于此系统,成功标注了包含 400 万独特短语和 5200 万掩码的高质量训练数据,以及包含 3800 万短语和 14 亿掩码的合成数据集。
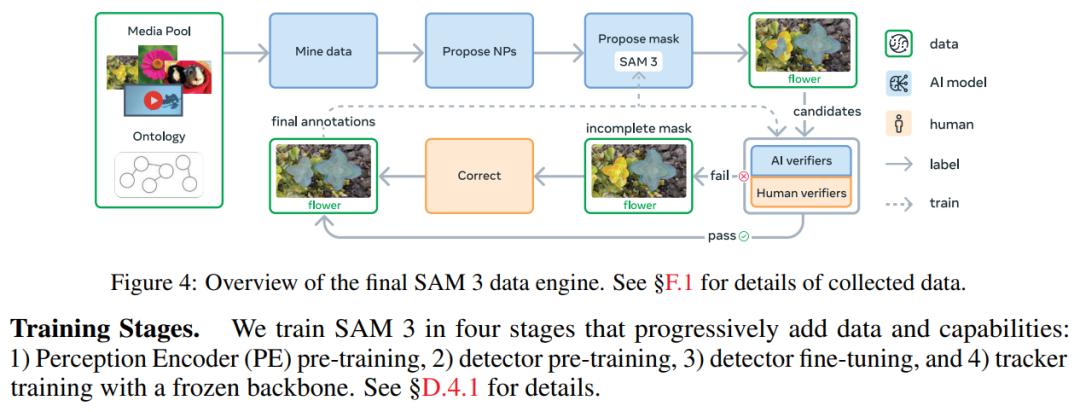
更进一步,本文创建了用于 PCS 任务的 Segment Anything with Concepts(SA - Co)基准测试,涵盖 124K 张图像和 1.7K 视频中的 214K 独特概念,概念数量超现有基准测试集 50 倍以上。

实验
实验结果显示,在零样本设置下,SAM 3 在封闭词汇数据集 COCO、COCO - O 和 LVIS 的边界框检测任务中有竞争力,在 LVIS 掩码任务上表现显著更好。在开放词汇 SA - Co/Gold 数据集上,SAM 3 的 CGF 分数是最强基线 OWLv2 的两倍,在其他 SA - Co 子集上提升更高。在 ADE - 847、PascalConcept - 59 和 Cityscapes 上的开放词汇语义分割实验中,SAM 3 表现超越强大的专家型基线 APE。
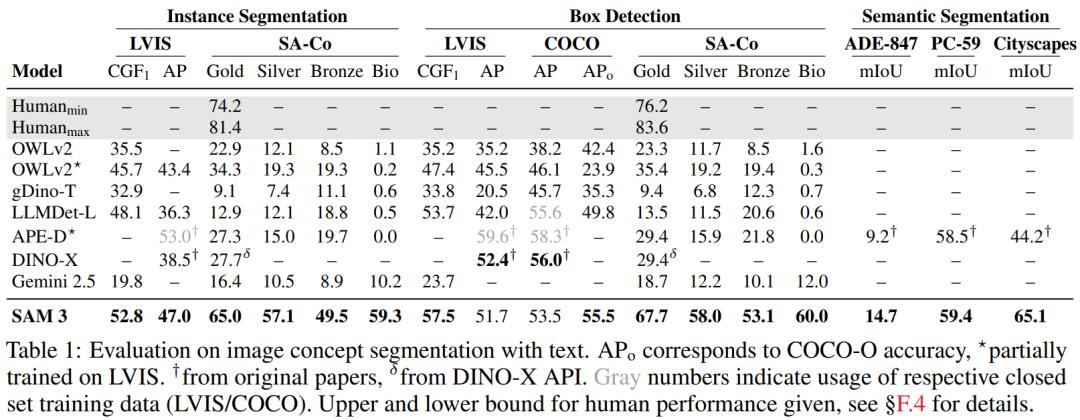
在小样本自适应方面,SAM 3 在 10 - shot 设置下实现当前最优性能,超过了 Gemini 的上下文提示以及目标检测专家模型(如 gDino)。在带有 1 个样本的 PCS 中,SAM 3 在 COCO (+17.2)、LVIS (+9.7) 和 ODinW (+20.1) 上的表现远超之前最先进的 T - Rex2。
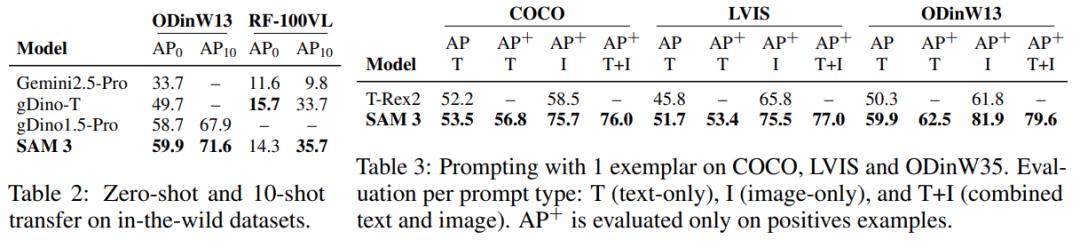
在物体计数方面,与 MLLM 相比,SAM 3 不仅有良好的物体计数准确率,还能提供大多数 MLLM 无法提供的对象分割功能。

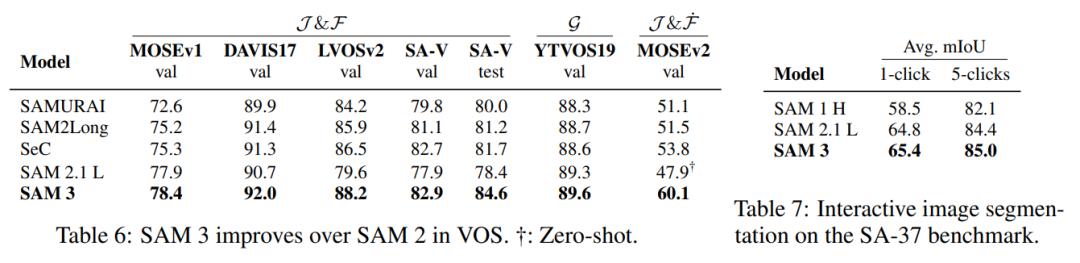
SAM 3 在文本提示下的视频分割表现远超基线,尤其是在包含大量名词短语的基准测试中。将 SAM 3 与 VOS(Video Object Segmentation)任务上的先进方法比较,SAM 3 在大多数基准测试中比 SAM 2 有显著改进。对于交互式图像分割任务,SAM 3 在平均 mIoU 方面优于 SAM 2。
本文来自微信公众号“机器之心”,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com