
阿里开源三大模型,多模态大模型再突破







阿里在多模态大模型领域持续发力。智东西9月23日消息,深夜,阿里通义大模型团队接连放出三个大招,分别是开源原生全模态大模型Qwen3 - Omni、语音生成模型Qwen3 - TTS、图像编辑模型Qwen - Image - Edit - 2509更新。
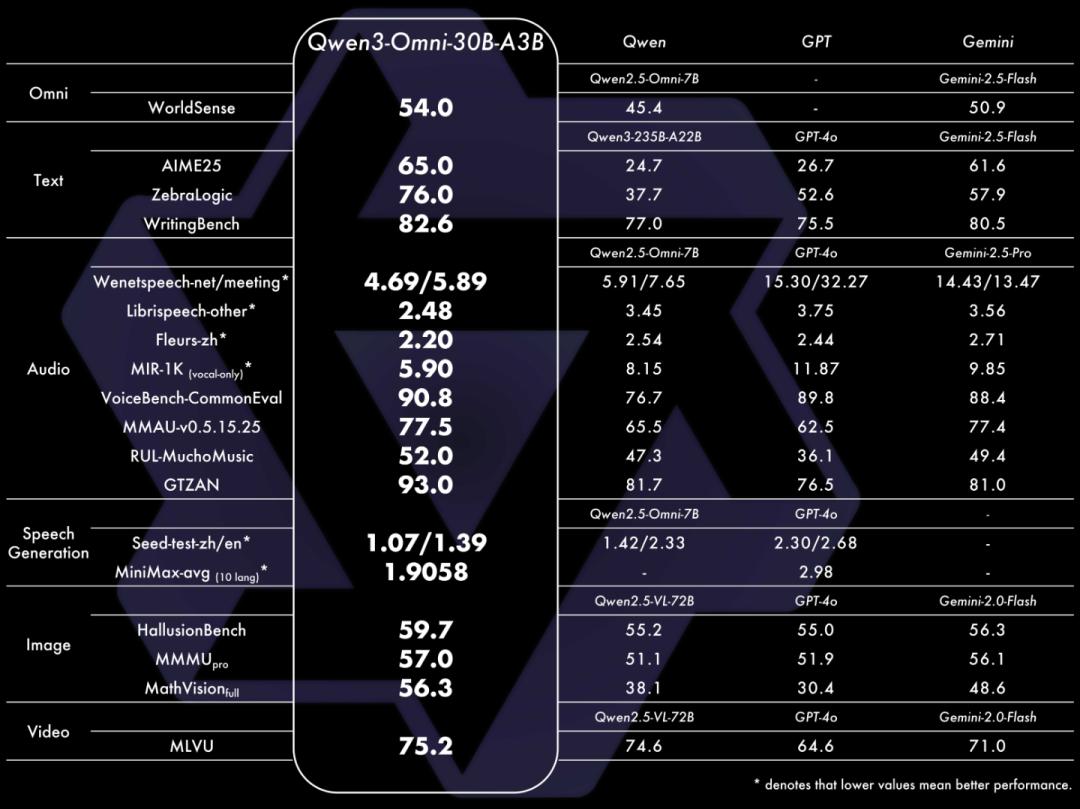
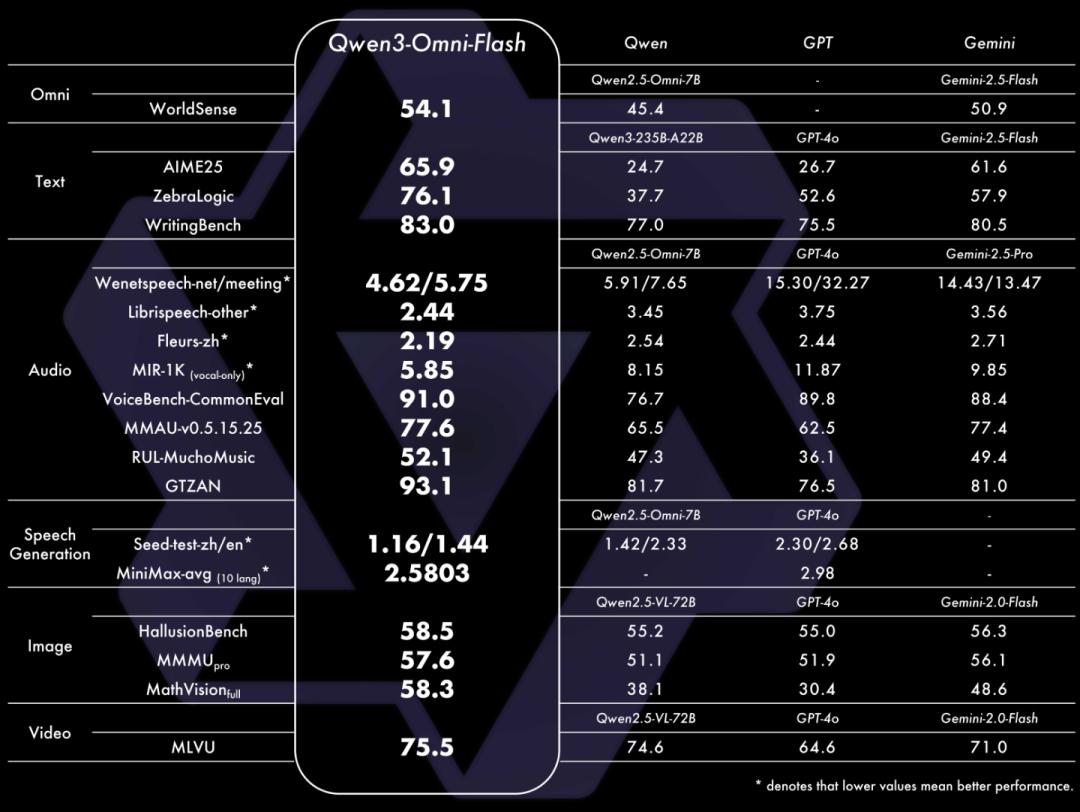
Qwen3 - Omni能够无缝处理文本、图像、音频和视频等多种输入形式,还能通过实时流式响应同时生成文本与自然语音输出。它在36项音频及音视频基准测试中斩获32项开源SOTA与22项总体SOTA,超越了Gemini - 2.5 - Pro、Seed - ASR、GPT - 4o - Transcribe等闭源强模型,其图像和文本性能在同尺寸模型中也达到SOTA水平。
Qwen3 - TTS支持17种音色与10种语言,在语音稳定性与音色相似度评估中超越了SeedTTS、GPT - 4o - Audio - Preview等主流产品。
Qwen - Image - Edit - 2509的主要更新是支持多图编辑,可以对不同图片中的人物 + 人物、人物 + 物体等进行拼接。
阿里开源了Qwen3 - Omni - 30B - A3B - Instruct(指令跟随)、Qwen3 - Omni - 30B - A3B - Thinking(推理)和通用音频字幕器Qwen3 - Omni - 30B - A3B - Captioner。
Hugging Face开源地址:https://huggingface.co/Qwen
GitHub开源地址:https://github.com/QwenLM/Qwen3 - Omni
01.支持119种语言交互,能随意定制、修改人设
在通义千问国际版网站上,点击输入框右下角可唤起视频通话功能,此功能目前处于Beta测试阶段。实际测试中,网页端视频交互体验不稳定,使用通义千问国际版App,Qwen - Omni - Flash的视频响应延迟较低,接近真人面对面交流的流畅度。
Qwen - Omni - Flash具备良好的世界知识储备,通过识别啤酒品牌、植物等画面测试,模型能准确回答。官方博客称,Qwen3 - Omni支持119种文本语言交互、19种语音理解语言与10种语音生成语言,纯模型端到端音频对话延迟低至211ms,视频对话延迟低至507ms,还能支持30分钟音频理解。但实际使用中,模型输出英语、西班牙语等外语时,发音带有明显普通话语调特征,不够自然地道;在粤语交互场景下,会夹杂普通话词汇,影响对话沉浸感。
官方演示Demo展示了西班牙语、法语、日语的交互效果。该模型能分析意大利餐厅菜单,用法语为朋友推荐意大利面;还能查看网站内容,总结是巴塞罗那毕加索博物馆的官方网站并介绍相关信息;在日语交流场景中,可分析视频中人物所处环境及交流内容。
Qwen3 - Omni支持system prompt随意定制,可以修改回复风格、人设等。演示中,模型扮演广东幼儿园老师,为小朋友讲解Qwen3 - Omni。在多人交互场景中,Qwen3 - Omni能分析人物的性别、说话语气和内容等。此外,它还支持分析音乐风格、元素,以及对视频画面进行推理。
02.22项测试达SOTA,预训练不降智
Qwen3 - Omni在全方位性能评估中,单模态任务表现与参数规模相当的Qwen系列单模态模型持平,音频任务表现更优。在36项音视频基准测试中,32项取得开源领域最佳性能,22项达到SOTA水平,超越了Gemini - 2.5 - Pro等闭源模型,在语音识别与指令跟随任务中达到Gemini - 2.5 - Pro相同水平。
Qwen3 - Omni采用Thinker - Talker架构,Thinker负责文本生成、Talker专注于流式语音Token生成,直接接收来自Thinker的高层语义表征。为实现超低延迟流式生成,Talker通过自回归方式预测多码本序列。其创新架构设计要点包括,音频编码器采用基于2000万小时音频数据训练的AuT模型,Thinker与Talker均采用MoE架构。研究人员在文本预训练早期混合单模态与跨模态数据,使各模态混训性能不下降,同时增强跨模态能力。AuT、Thinker、Talker + Code2wav采用全流程全流式,支持首帧Token直接流式解码为音频输出。此外,Qwen3 - Omni支持function call,可实现与外部工具/服务的高效集成。
03.发布文本转语音模型,多项基准测试达SOTA
阿里通义发布了文本转语音模型Qwen3 - TTS - Flash。其特点如下:
- 中英稳定性:在seed - tts - eval test set上,Qwen3 - TTS - Flash的中英稳定性达到SOTA,超越SeedTTS等产品。
- 多语言稳定性和音色相似度:在MiniMax TTS multilingual test set上,中文、英文、意大利语、法语的WER达到SOTA,英文、意大利语、法语的说话人相似度超越MiniMax等模型。
- 高表现力:具备高表现力的拟人音色,能稳定输出遵循输入文本的音频。
- 丰富的音色和语种:提供17种音色选择,每种音色支持10种语言。
- 多方言支持:支持普通话、闽南语等多种方言生成。
- 语气适应:能根据输入文本自动调节语气。
- 高鲁棒性:能自动处理复杂文本,抽取关键信息。
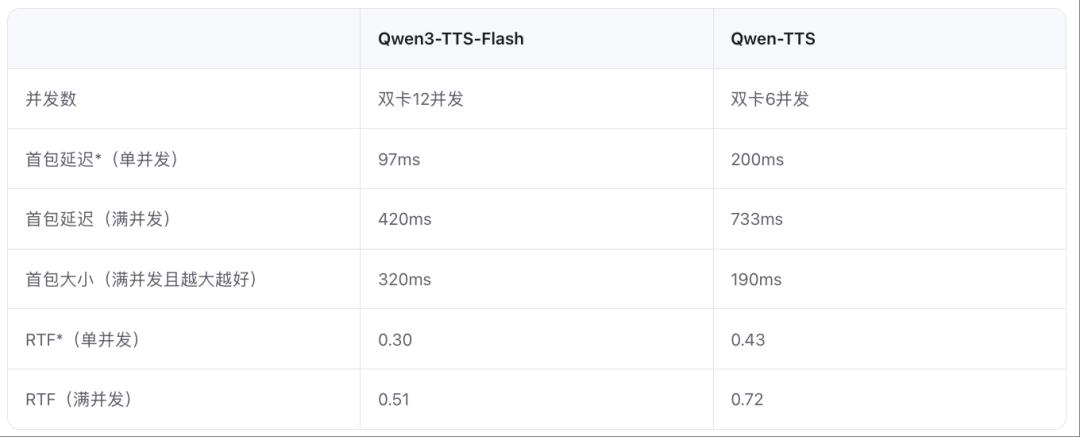
- 快速生成:单并发首包模型延迟低至97ms。
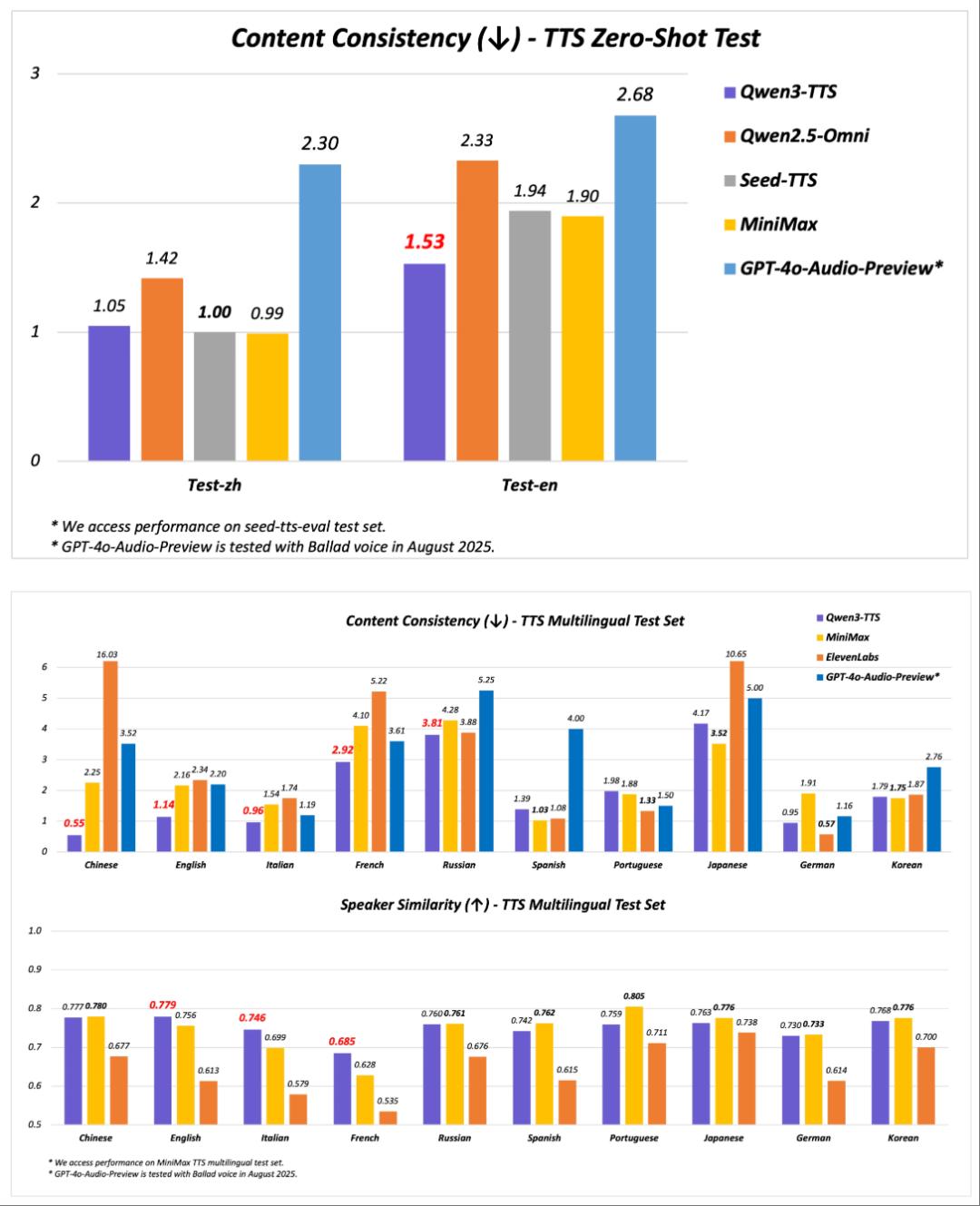
研究人员引入架构升级和加速策略,使模型首包延迟更低、生成速度更快。
04.图像编辑模型更新,支持多图编辑
阿里推出图像编辑模型Qwen - Image - Edit - 2509的月度迭代版本。与8月发布的Qwen - Image - Edit相比,主要特性有:
- 多图编辑支持:基于Qwen - Image - Edit结构,通过拼接方式训练,提供“人物 + 人物”等多种玩法。
- 单图一致性增强:提高了人物、商品、文字编辑的一致性。
- 原生支持ControlNet:包括深度图、边缘图、关键点图等。


05.结语:多模态赛道发力,阿里通义家族模型加速扩员
此次三大模型的新进展强化了通义在多模态生成领域的竞争力。Qwen3 - TTS - Flash在多方面实现性能突破,与Qwen3 - Omni结合更新了大模型语音表现。阿里通义大模型团队表示,未来将沿多个技术方向推进Qwen3 - Omni模型升级。阿里在多模态大模型领域持续发力,部分性能超越竞品,未来有望在更多实际应用场景落地。
本文来自微信公众号“智东西”(ID:zhidxcom),作者:程茜 陈骏达,编辑:云鹏,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com