
为什么用错了奖励,模型也可以得分?新研究:模型学习的不是新知识,而是思维。






在最近的一篇论文中,来自NPC和腾讯的研究人员的研究表明,语言模型对于加强学习的奖励噪音是鲁棒的,即使相当一部分奖励是旋转的(例如,正确答案是 0 分数,错误答案得到 1 分数),也不会显著影响下游任务的表现。
研究人员解释说,加强学习提高下游任务的关键不仅在于奖励的准确性,还在于模型能否产生高质量的思维过程。语言模型只能通过奖励模型导出关键思维词的出现频率,而不是基于答案的准确性,在下游任务中仍然可以获得非常高的峰值表现。由此可见,加强学习对下游任务的提高,更多的是因为让模型学会选择合适的思维方式来接近正确答案。而且相关的答题基本能力,模型已经在预训练阶段获得。所以,提高预训练阶段的技能还是很重要的。
研究人员还展示了基于思维模式的简单奖励如何有效校正奖励模式,然后开放 NLP 加强语言模型在任务中的表现,使较小的模型也能通过加强学习成功地获得思考能力。

论文地址:https://huggingface.co/papers/2505.22653
代码链接:https://github.com/trestad/Noisy-Rewards-in-Learning-to-Reason
论文概览
首先,作者讨论了数学任务中奖励噪声对语言模型的影响。由于数学任务使用简单的规则进行验证,并根据答案的准确性进行奖励,因此人工控制奖励噪声变得非常简单(例如,奖励函数的结果是基于答案的准确性。 p% 翻转,正确答案得到 0 分数,错误答案得到 1 分),然后便于研究。在练习 Qwen-2.5-7B 在模型中,实验发现,即使是 p 价值非常高,模型在下游任务中的表现基本没有下降。只有在 p 值达到 在50%(即完全随机奖励)的情况下,训练效果开始崩溃。这种现象引起了一个重要的问题:为什么即使模型给出了错误的答案并得到了奖励,训练效果仍然一致?
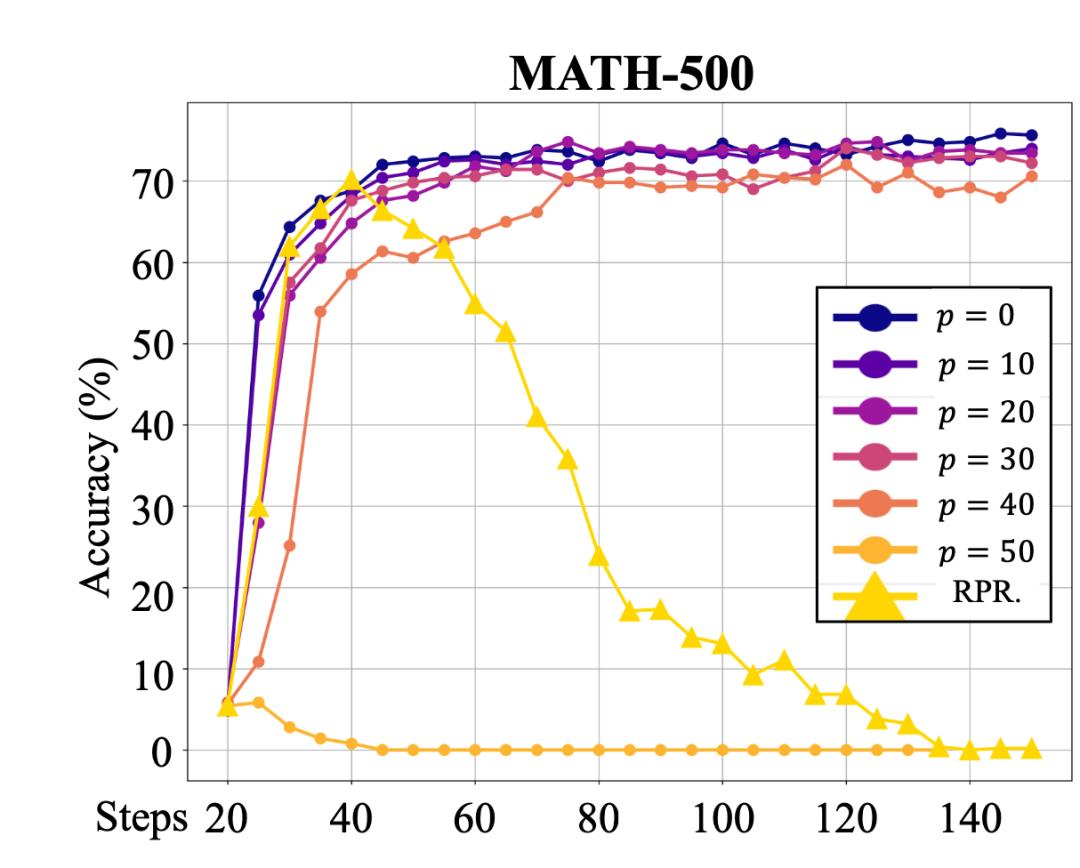
图 1:反转后使用不同程度的奖励 Qwen-2.5-7B 在 MATH-500 改变数据的准确性,横轴为训练计步。
针对这一现象,作者提出了一个可能的解释:尽管答案是错误的,但是导出中的一些信息仍然为模型导出提供了奖励。研究人员认为,这些有用的信息体现在模型思维过程中。例如,模型生成「First, I need to」,「second, I will」,「given these factors」,「finally」等待思考模式时,无论最终答案是否正确,这个思考过程本身是值得奖励的。
为验证这一假设,作者统计了没有噪声奖励训练(即 p=在0)的情况下,Qwen-2.5-7B 高频思考关键字在数学任务中导出,并且设计了一个特别简单的奖励系统。 ——Reasoning Pattern Reward(RPR)。每次模型导出包含这些高频思考关键字时,都会根据出现频率给予相应的奖励,频率越高,奖励越大。
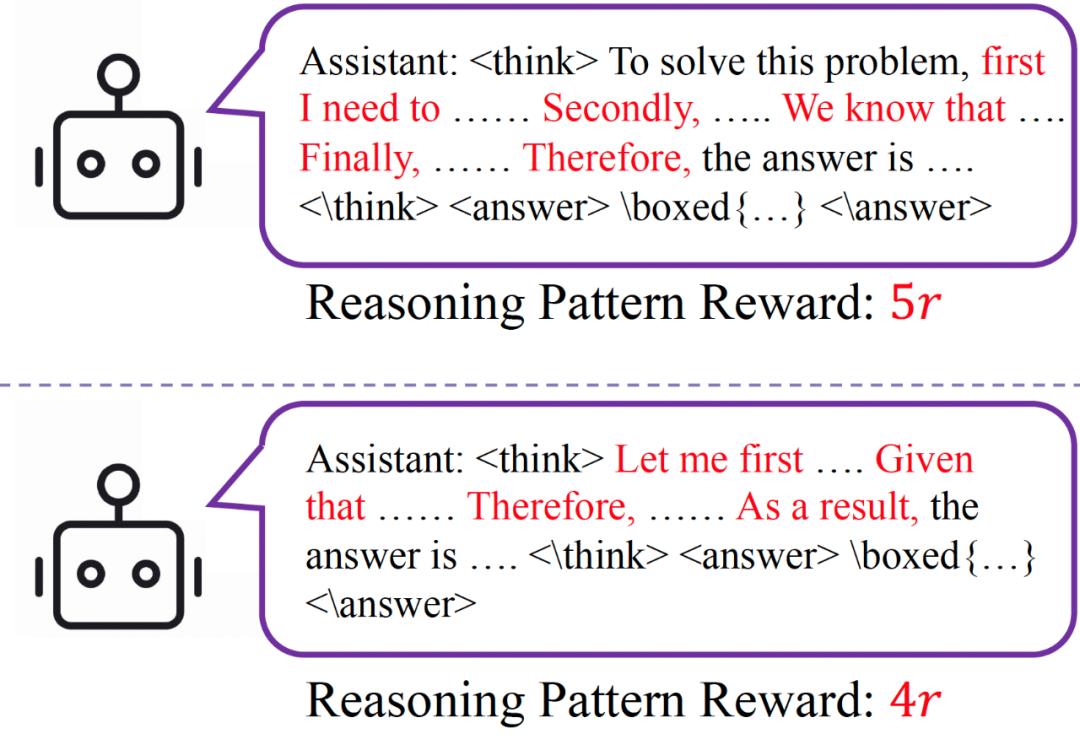
图 2: RPR 示意
仅使用 RPR 机制,完全不考虑答案的准确性,Qwen-2.5-7B 依然能够在 MATH-500 从数据上获得准确性 5% 提升至 70% 以上。尽管后期训练的准确性明显下降,但作者通过案例研究指出,这种下降是由于 RPR 在得到正确答案之后,促使模型「过度思考」,导致导出时间较长,无法提取正确答案。作者承认,只使用 RPR 如果不使用其它答案进行校验奖励,可能会被模型奖励。「hack」并且有问题,但是他们强调,这个实验的目的是证明思维模式在技能提升方面的重要性,而不是为了得到最好的结果。
这个实验表明,在强化学习中,语言模型的改进主要来自于输出格式的转变,而不是获得新的知识:模型 RL 在此期间取样到具有较强思维方式的输出,而这种思维方式可以逐步改进模型。 token 接近正确答案的可能性。
上述基于奖励函数的实验结论让作者意识到,这一发现可能是基于奖励模型的。(reward model)强化学习后训练具有重要启发性:由于奖励模式一般不完美,导出通常包括噪音。如果语言模型在开放任务中能够保持奖励模型导出噪音的鲁棒性,那么我们可能不需要过分追求极其准确的奖励模型,以确保它们。「足够好」即可。
为了验证这一点,作者正在 Nvidia-3teerHelpSteer 资料(多个领域) AI 协助回复生成任务)在试验中进行。通过调整训练步骤,对不同精度的奖励模型进行训练,并使用这些模型进行训练。 Qwen-2.5-7B。作者认为,奖励模型的准确性与其提供的奖励噪声呈负相关,即奖励模型的准确性越高,奖励噪声越小。人类对模型在测试集中导出的反应 GPT-4o 协助、信息、综合质量的判断。
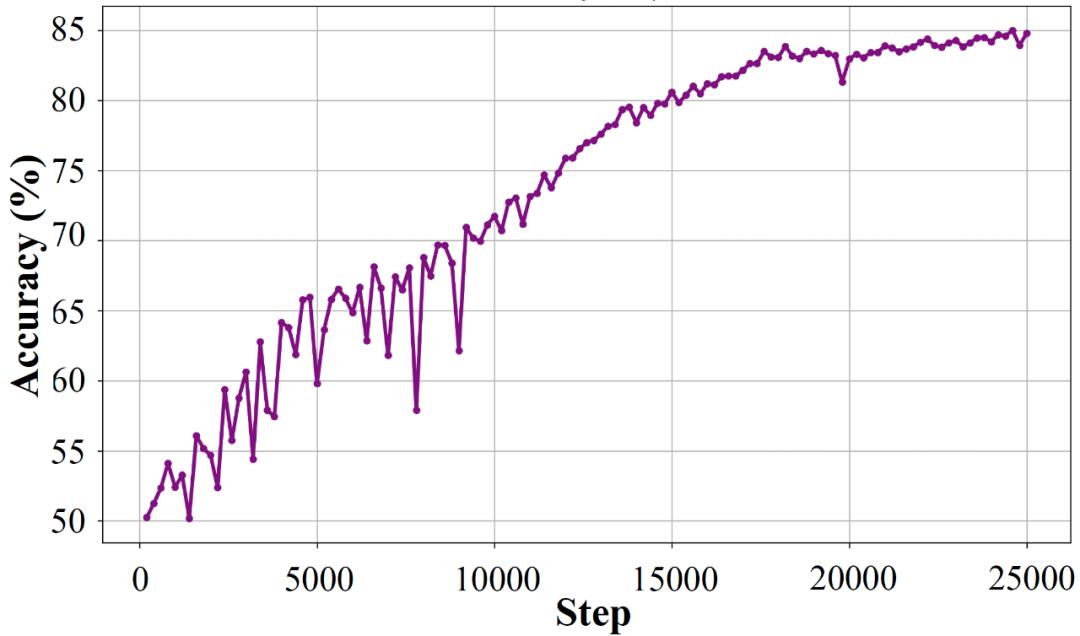
图 3: 奖赏模型在 3teerHelpSteer 在训练过程中,作者在验证集中选择了不同训练步骤的准确性 checkpoint 训练是一种奖励模式。
测试数据显示,当奖励模型的准确性超过 75% 在下游任务中,不同奖励模型训练得到的语言模型的主观评价得分相似。这种现象与数学任务中的观察一致,表明语言模型能够在一定程度上容忍奖励噪音。但是,当奖励模型的准确度低于 75% 当时,训练效果明显下降;当准确度降低到 65% 在这种情况下,模型表现不如使用高精度奖励模型训练得出的结论。或许已经指出来了 Qwen-2.5-7B 噪声耐受性限制在该任务中。
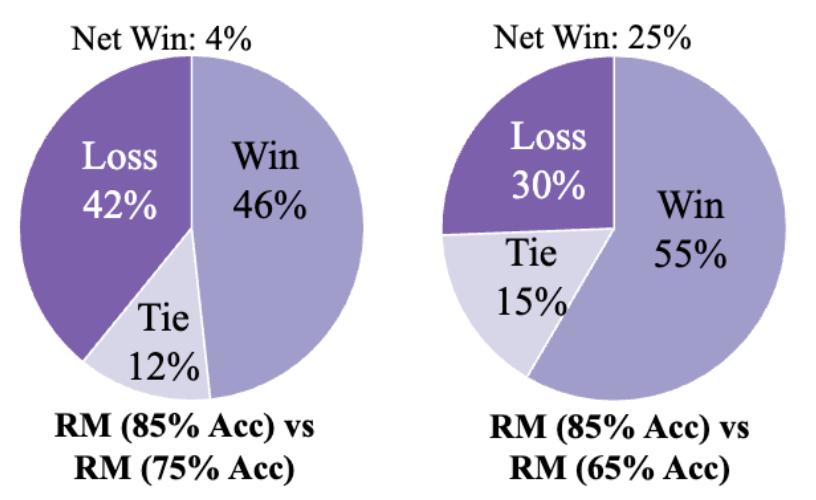
图 4: 通过不同的奖励模型训练获得的语言模型 3teerHelpSteer 主观评价任务中的表现
这个发现对许多研究人员来说可能是一种安慰:在很多应用场景中,我们不必过分追求奖励模型的高精度。在超过一定的临界点后,奖励模型的精度将进一步提高,这将限制任务性能的提高。。
作者进一步思考,如果真的得不到,「足够好」奖励模式,如何加强当前的奖励模式,提高下游任务的表现?
所以,作者提出通过 RPR 校准奖励模型:如果某一导出被奖励模型评为低分,但其思维模式较好(即 RPR 如果分数较高),那么这个低分可能是假阴性,需要通过其思维模式进行思维。 RPR 该机制补偿了奖励模型的导出。这样,作者就是这样。 3teerHelpSteer 即使奖励模型的准确率是验证的, 65%,经过 RPR 校正后,模型表现接近原来的表现。 85% 精确度的奖励模型训练效果。同时,85% 精确度奖励模型经过校正后,模型在下游任务中的表现进一步提高,突破了作者对奖励模型质量的限制。
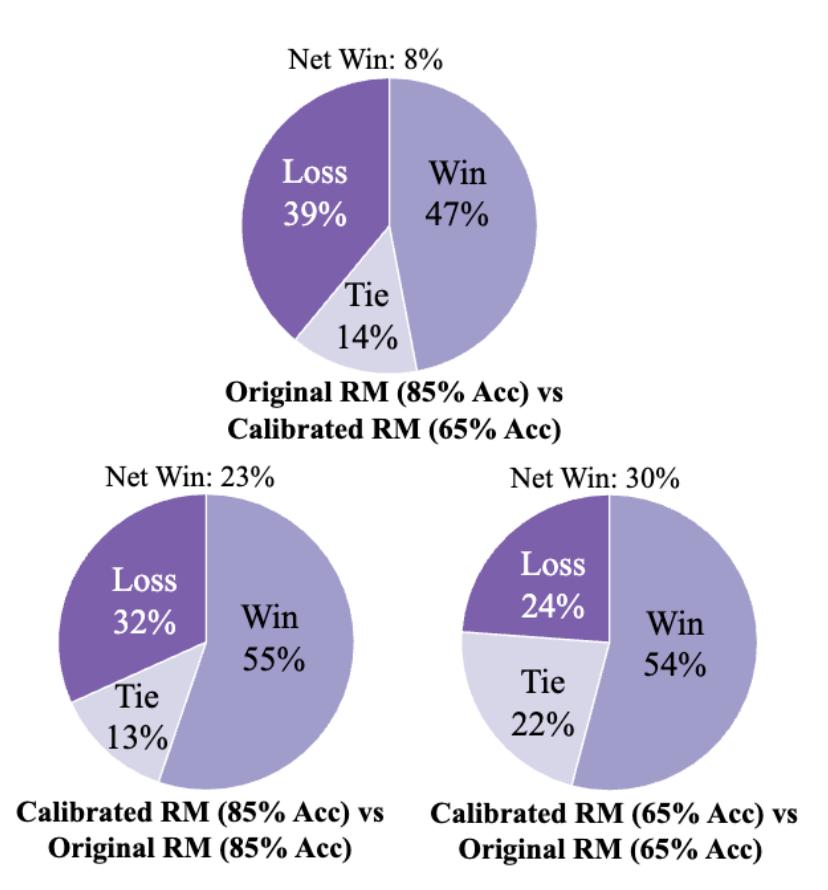
图 5: 经过 RPR 校正之后,所有奖励模型训练的语言模型质量都有所提高。
作者的另一个重要发现是,即使使用作者拥有的最准确的奖励模型(准确性) 85%),Qwen-2.5-3B 在 3teerHelpSteer 训练崩溃发生在任务中,表现为导出长度急剧下降,只剩下几十个。 token。但经过 RPR 校正后,3B 模型成功地完成了训练,避免了崩溃,取得了良好的效果,而且在很多复杂的开放任务中,比如按照指令进行。 PPT,表现出良好的解题思路。
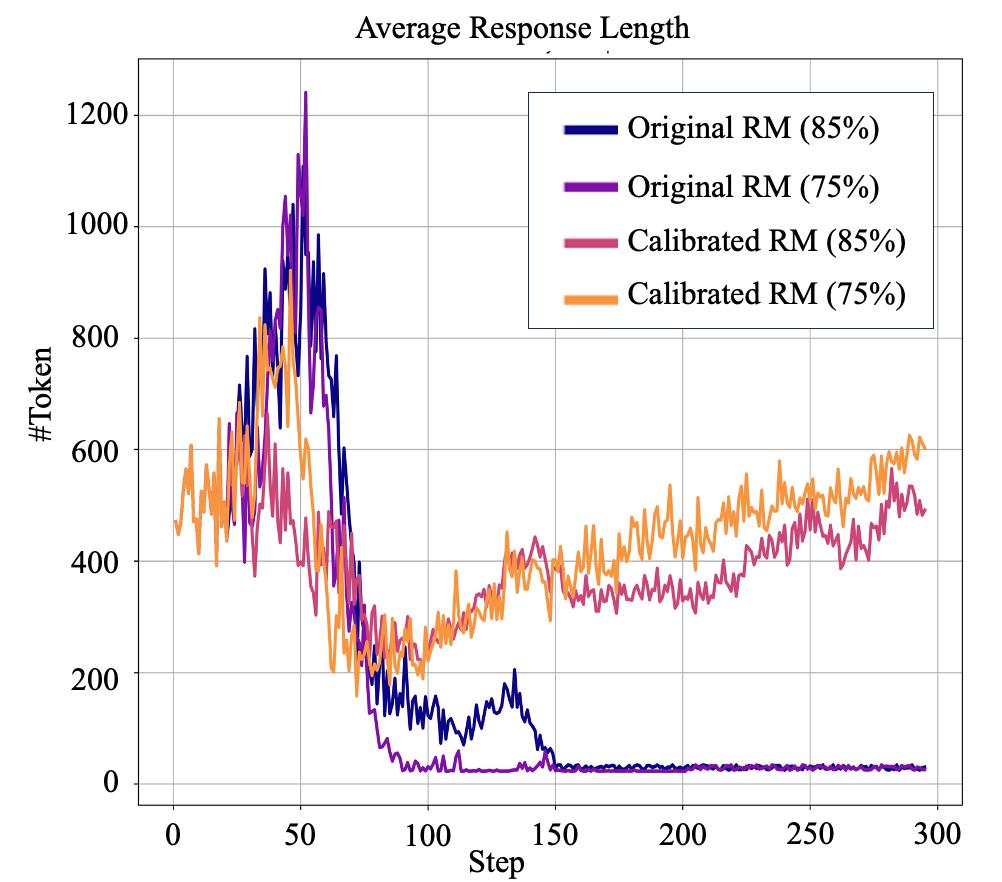
图 6: 经过 RPR 3B奖励模型校正后, 模型也可以存在 HelpSteer 成功的任务训练;并且采用了未校正的奖励模式,RL 发生了崩溃。
研究人员希望通过展示语言模型来奖励基于结果的噪音的鲁棒性,并单独使用 RPR 得到下游任务改进的结果,强调加强学习对语言模型的影响,不是教授新知识,而是改变其导出风格,建立良好的思维模式。。
此外,在使用奖励模型进行训练的开放任务时,验证了思维模式的重要性,也为加强学习后训练算法的改进提供了新的思路。
作者指出,模型预训练技术的提升仍然值得持续投资,因为如果强化学习只关注思维模式的培养,语言模型预训练阶段的能力仍然会给下游任务带来瓶颈(例如,正确的文本 Llama3 实验表明,因为 Llama3 预训练模型很难生成更高质量的思维路径,导致其在各项任务中的表现和抗噪声能力远不如 Qwen 模型)。
*这篇文章的主要作者是吕昂和谢若冰。中国人民大学博士生吕昂的研究方向是调整语言模型结构,导师是严睿教授;腾讯高级研究员谢若冰的研究方向是大语言模型和推荐系统。
本文来自微信微信官方账号“机器之心”(ID:作者:机器之心,36氪经授权发布,almosthuman2014)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com