
压力性Llama,开源困境






DeepSeek R1-V3、GPT-4o、Claude-在3.7的强势围攻下,Meta并不平静。Llama曾经是开源之光,在一年的竞争中不断失败,没有开发和转让公众的亮眼功能。创始人扎克伯格下达了死亡命令,必须在今年4月更新。
于是我们迎来了它仓促的答卷——Llama4,一款在实际测量中令人惊讶的眼镜模型,号称10ma4。 token的前后文长度经常出错,第一代球检很难,9.11>9.9的比例错误...这个本该引人注目的样子从期待变成了嘲讽。上线几天,高管离职、检测作弊等丑闻被内部人士爆料证实。
Llama系列作为开源生态的标杆,曾经使用Llama系列 2辉煌的成就——7000多个组合的衍化,3亿多个下载,定义了商业开源大模式的黄金时代。短短两年时间,Meta主导的开源运动逐渐失去了研发内卷的初衷,进入了一个缺乏创新的恶性内卷。
此外,开源模型不依靠C端会员制支付实现,短期利润没有希望。在这种情况下,为什么Llama渴望更新?国内外开源模型还在滚动什么?
仓促的Llama4答卷
Llamama最新发布的Meta 4系列包含Scout(前后文窗口1000万Token)、Maverick(与DeepSeek相比,编码和推理 V3和尚未发布的Behemoth(2880亿活跃参数),官方声称它是历史上最强的多模式模型。
然而,24h被打脸了。
在发布的第二天,内部人士透露,Llama4的基准测试存在重大欺诈,模型远远达不到开源sota标准,但是为了赶在4月底之前发布,领导们在post-training的过程中混合了各种benchmark的测试集,并产生了一个“看起来可以”的结果。
技术兑水的后果不言而喻是关键特性的严重缺陷。Llama4的许多任务在社交媒体X和Reddit的用户实际测量中明显落后于上一代产品和同量级模型,公众并没有为这种噱头买单。
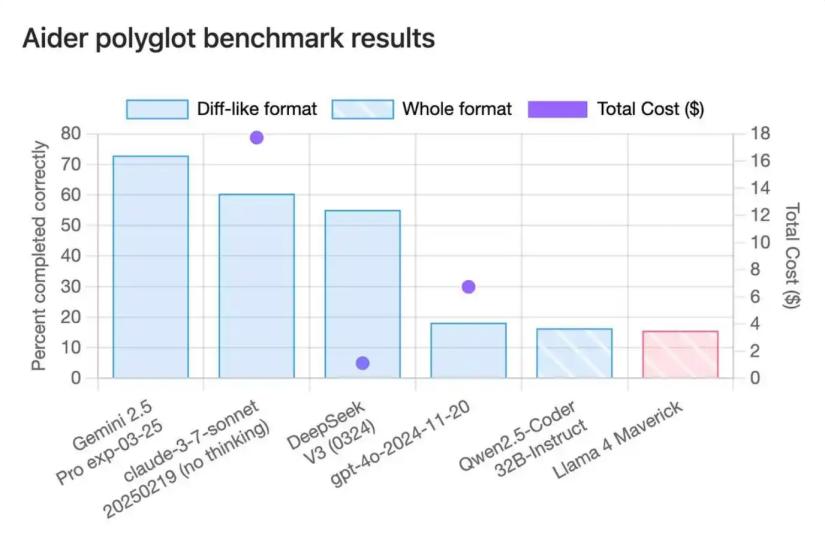
代码能力差,令人满意。Maverick版本在Polyglot编程测试中的正确率仅为15.6%~16%,几乎垫底,与Meta声称的“编码能力超过DeepSeek”严重不符。它的402B参数值规模并没有带来优势,而是被Qwen-QwQ等32B参数模型超越,基准测试结果严重失真。
多模态产品卖点能力没有达到预期,客户实际测量发现其图像理解能力甚至不如去年谷歌开源的Gemma 而且在长前后的任务中表现不稳定,随着token长度的增加,性能明显下降。

Llama4的出现不仅没有什么亮点,还面临着刷分造榜、烧钱走下坡路等污点。既然完全没有训练好,为什么Meta赶着给自己找麻烦呢?
这太焦虑了,焦虑到即使只是一个无法登上台面的瑕疵,也要黔驴技穷地端上桌。
一方面,GPT-4o、Claude3.7等头闭源模型在多模态、代码能力等方面的领先地位,使得Meta在海外市场苦不堪言;DeepSeek V3等后起之秀的出现,让它成为开源社区的领头羊的光环讳莫如深。
在内外攻击下,扎克伯格不得不在4月份设立ddl,迫使R&D部门拿出自己的作品,试图挽回公众的信心,但这样高压的前线却功亏一篑。没有时间创新的技术部门不得不在模型达不到预期的前提下,压缩测试周期,强制上线。
竞争与管理的双重高压使得团队在内卷中失去了技术标准的初衷。传统技术DPO虽然简化了RLHF流程,但在数学、代码等复杂任务上并不稳定。与GPT-4o的多模态结构相比,Llama 4的改进更像是依靠Scaling。 law的小修小补,疯狂堆叠参数,忽略了对底层结构的探索。
Meta急功近利,既没有耐心打磨技术,也没有遵循行业伦理,陷入了恶性内卷的开源困境。
开源≠免费,落后就要挨打
从2023年开始,1月1日更新头部模型军备赛,使模型竞争陷入恶性内卷。相似的训练数据和趋同的结构使得许多商品高度同质化。GPT-4o、强大的闭源模型,如Claude,将会脱颖而出。
令人困惑的是,为什么选择开源路径Llama也要焦虑?它不依靠会员订阅来盈利,更新是否似乎不能带来更多实质性的利润。
实际上,开源并不意味着放弃商业化,开源和闭源会有不同的盈利逻辑。闭源就是直接销售产品,通过订阅付费赚钱,开源就是通过定制服务打造坚实的生态堡垒来占领未来市场。
开源如何赚钱?通俗地说,开源就等于是美食店的品尝,商家为了让顾客买到更多的甜品,每天生产100份免费甜品。模具厂开放免费token的使用次数就像美食店一样,吸引有实力的企业和开发商购买定制服务。
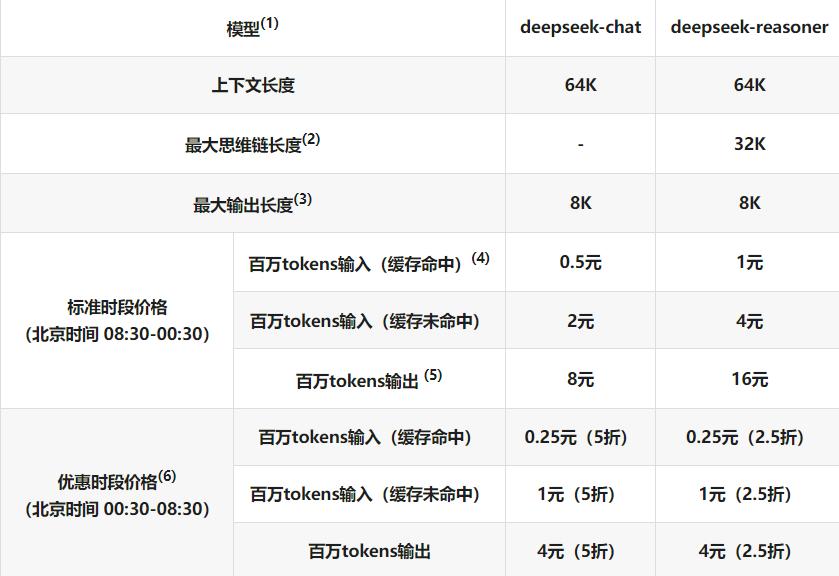
开源模型的第一个业务是销售高性能API。虽然基本服务是免费的,但是企业可以根据调用量提供高性能的API服务。DeepSeek-API定价为每百万输入Token。 1元,每百万导出tokens。 16元。如果免费token额度用完或者基本API无法满足需求,客户将专注于使用付费版本来维持工作流程的稳定性。
另外,强大的政企客户是大型商业化的主力军。出于高保密性和定制性的需要,很多企业会购买模厂的私有部署服务。制造商收取技术费用,并根据需要提供定制的模型培训、微调和后续的系统维护和升级服务。据悉,大型私有化基础的建设基本上是百万打底。根据某模厂的销售情况,他们公司最新的模式至少有2000万,可以理解为五星级餐厅的私人宴会和满汉全席。
第二,一些厂家选择了开源和闭源并行的双轨路线。开源基础版满足通用需求,闭源高级版服务支付市场。相当于先给你一道开胃菜,你可以选择是否吃晚饭。2023年的智谱就是一个典型的模型。企业开源ChatGLM-6B模型建立生态,同时推出1000亿元的闭源参数模型GLM-130B,向B端收费。

最后,开源实际上是一座商业桥梁,旨在通过降低门槛、提高粘性、分层实现开发者生态社区的建设。举例来说,餐馆提供试吃小菜,建立了自己的吃货群,但同时还销售餐具、调味品、店内游乐设施等体验服务。
大模型也是如此。大量被开源吸引的开发者是他的生态。他们可以植入广告,收取广告费,销售云服务,销售配套的AI产品。
实际上,开源就是为了抢生态。顾客越多,未来的盈利渠道就越丰富,但是一旦性能被超越,开发者就会流失,造成连锁反应。
因此,Meta如此着急地发布Llama4,因为他害怕如果他不努力工作,开发者将成为更好的模型,如DeepSeek。前期苦心经营的AI生态一旦松动,看不到用户基数的云计算合作伙伴(如微软Azure)也会离开,导致间接盈利渠道萎缩,商业变现受阻。
更重要的是,早期的AI模型主要是口碑效应。一旦落后,市场竞争力就会下降,失去用户和合作伙伴的Llama逐渐失去了行业内的认可度。这意味着说到开源模型,讨论Llama的次数会越来越少。
落后的压力,迫使Meta在很短的时间内推出Llamama。 即使牺牲了模型的质量。
告别内卷,迈向创新
世界上没有免费的午餐,也没有免费的生意。
Meta对开源的热情,隐含着扎克伯格对大型市场生态的渴望,这也体现在国内众多公司中。
在DeepSeek等公司的带动下,国内大型公司纷纷加入开源浪潮。比如曾经坚持走闭源路线的百度,也宣布将于2025年6月全面开源文心4.5系列。
然而,Llama4的失败也告诉我们,模型开源不能陷入恶性内卷,基础模型厂找到多样化的线路非常重要。
一是要坚持创新带来的性能提升。DeepSeek的全栈开源可以在短时间内打破B端和G端市场。关键是它的MoE底层结构大大降低了成本,提高了效率。而Llama 迷信scaling迷信 law,智能路面已经不能通过积累参数出现,未来破局的关键在于突破多模态、小样本的前沿领域。
另外,基准测试并不等于真实体验,不要盲目追求sota,而忽略了实际场景中的应用体验。与Llama 不同的是,DeepSeek在早期并没有给自己贴上登顶sota的光环,在国内外客户的实际测量中更有说服力。
另外,战略是关键,做好商业化关系到开源模型的生死存亡。

举例来说,阿里Qwen系列通过全模式开源吸引开发者使用云计算等基础设施,形成情景闭环。它们的模型在早期只是一个引子,明码标价的商品实际上是云服务。然而,专注于AI的智谱声明没有其他东西可以出售。它选择了开源闭源双轨并行的策略,开源吸引了开发者的生态,并为B端和G端提供了付费定制解决方案。由此可见,企业必须结合自身的基因思维实现策略,把握市场定位,想清楚客户期望什么样的服务。
除销售模型人外,使用模型人还应注意,开源模型并非万全之策,存在隐性限制。
第一,部分开源模型将在许可证中明确禁止商业应用,仅限学术研究。,如Meta llama2限定月活超过7亿公司使用,削弱开源自由;其次,很多开源模型只公开架构,不公开数据库和代码集,开发者只能根据目前的模型进行微调;当然,部署也有一定的门槛。,模型微调需要英伟达显卡等昂贵的计算资源,一般开发者难以承受。
AI开发商和软件ISV服务提供商在实际选择开源模型时,必须仔细阅读各种附加条款和协议,以防止许可限制和法律风险;除开源模型外,开发商还可以跟随闭源模厂开发商业版,降低后期风险。
总而言之,Llama暂时的失败告诉我们:开源生态没有技术巩固,最终是一盘散沙。为了吸引众多开发者来培养用户粘性,开源模型厂商必须保持性能领先,告别无效内卷,迈向技术创新。
本文来自微信微信官方账号 “脑极体”(ID:作者:珊瑚,36氪经授权发布,unity007)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com