
智谱从 DeepSeek家乡杭州融资了一大笔钱。





3月3日,智谱公布了最新一轮融资:本轮战略融资金额超过10亿元,参与者包括杭州城投产业基金、上城资本等。智谱表示:此次融资旨在推动智谱国产基地GLM模型的技术创新和生态发展。
这是 DeepSeek 太平洋两岸的浪潮席卷太平洋两岸 在AI领域,硅谷和中国所有的大型明星创业公司似乎都保守秘密。当投资领域重新评估大语言模型标的的价值时,这是一个罕见而具有标杆意义的融资行动。
最有趣的是:在DeepSeek蒸蒸日上的时候,智谱在悄悄地 DeepSeek老家杭州,融资很多。
1 为什么杭州要“抢”智谱?
据公告,智谱已在杭州成立浙江智谱新篇科技有限公司,将服务浙江省、长三角地区的经济实体和人工智能产业转型升级。
此前,2024年12月17日,智谱完成了一轮30亿元的融资,投资者包括多家战争投资和国有资产。9月,中关村科学城公司投资前200亿元领先智谱。 。
2023年,智谱还完成了多轮融资。投资机构包括美团、蚂蚁、阿里、腾讯、小米等。,从社保基金中关村自主创新基金,到互联网厂商,以及头部VC红杉和高淳。
智谱的融资动作一直都有风向标的意思,而这次让杭州去北京“抢人”,也出现在一个微妙的节点。
目前,中国科技创新高地最热门的话题之一是DeepSeek与杭州的关系。它甚至让各地反思“为什么DeepSeek不在我们这里”。反思的声音没有停止,杭州的下一个城市已经成为智谱的战略投资者。
这反映了DeepSeek的冲击波之后,AI 行业对DeepSeek带来的机遇和挑战有了更加成熟和客观的认识。
如今,越来越多的人开始认为DeepSeek更像AI。 实验室公司,DeepSeek在追求AGI技术架构的原则上,从它发布的开源模型到技术论文,再到最近发布的基础设施核心代码的开源周,都没有对面向企业和政府服务的商业化情况和C端用户表现出太大的兴趣。面临着C端流量汹涌澎湃、政企客户纷纷接入的诉求,深知有点无力。
然而,DeepSeek现象加速了中国各行各业全面加快AI基础设施建设的信心。对于过去两年已经全面启动的大型商业化市场的头部玩家来说,DeepSeek并不打算满足或满足所有人的需求,这确实是一个扩张的机会。

从接近智谱的人群中,硅星人了解到,2025年春节后,智谱MaaS平台API的付费收入增长了30%。
另外,在DeepSeek最近引发的开源讨论中,根据他们提供的计算效率,有人计算出要满足全球AI计算消费需求(每天为世界上每个人生成10k token),事实上,GPU的计算率只有24万张。但是今天的问题是,这些需求在哪里?一家具有较强模型技术能力的商业运营公司,有实力深入场景打捞捕捉需求,反而变得更加重要。
GLM底座模型拥有者和最早全方位布局各行各业商业化的中国AI头部企业作为全链路国内自主研发的中国大型模型公司,智谱可能是最了解行业需求的企业之一。
这次融资也很“智谱”——再次获得另一个地方政府的产业资金下注。这也让人们再次关注了今天智谱“国家队”身份的意义。
去年年底,智谱成为第一家被美国商务部列入实体名单的中国大型公司。如今,在讨论AI竞争时,地缘政治不可避免地被推到了最前沿。
特别是美国特朗普的新内阁也在这一背景下推出了“星际之门”(StarGate),利用国家意志推动商业公司AI投资 在基础设施的情况下,没有人能否认:政府背景下的资金注定要在这场资金集中竞争中发挥关键作用。
它不是补贴,而是长期投资。智谱发布的融资信息特别强调了智谱GLM系列在金融、医疗、教育等多个行业的实际应用。
在DeepSeek解决的时候,每个人都有10k 可以使用token的理论问题,怎样解决这些token? 真正运用到最需要的场景中,并运用到位,就要看地方国有资产和智谱等公司如何共同努力。
2 各系列全新大模型即将发布和开源。
在“DeepSeek飓风”席卷后,智谱首次明确回应了超过10亿元人民币的融资。但是根据硅星人从很多接近智谱的人那里了解到,智谱内部对DeepSeek给技术和行业带来的变化,已经做出了自己的判断和很多应对调整。
在技术路线上,智谱明确了继续加大力度、训练底座模型、提高模型能力特性的目标。同时,智谱认为R1所体现的方向与下一阶段发展方向的分析是一致的。

智谱创始人唐杰在最近的巴黎AI安全会议上分享了他对AI发展方向的探索。他提到,下一个关键点将是“思维模式”,即拥有类似的Deep。 像Research这样的能力模型。“这种有自学能力的 AI 能够独立处理开放域问题,即使是从未见过的问题,他们也能像人类一样,通过不断的尝试和探索来解决。
硅星人独家了解到,智谱正在训练他们的下一代“思考”模式,公司将2025年定义为开源年,未来各系列全新的开源模式将很快发布和发布。
如果你仔细研究智谱的历史,你会发现这些行动更像是对原路线的再确认,而不是“转化”。事实上,DeepSeek的各种行动客观上刺激了这个行业每一个链接中的公司重新思考自己的初衷。
对于智谱来说,这是2021年中国最早研究大模型的机构。 2008年,智谱提出了自己的模型算法 GLM,同年训练了 MOE 体系结构的第一个国产万亿模型启示。根据当时参与项目的研究人员之前对硅星人的描述,这种模式从第一天决定训练就选择了“用手搓国产芯片算法”的路线,这是最困难但长期意义重大的事情,定义了这家公司的本色。
今日回放非常有趣的地方是:智谱之前的GLM底座模型,以及基于GLM-4-Plus、AutoGLM、GLM-Zero-Preview等,在计算率规模上也不如 OpenAI 在十分之一条件下开发的同等级模型。而且GLM也是当时罕见的一种不同于GPT路线的结构,最初都是通过开源得到了全球技术社区的认可。
利用少量的计算资源办理AGI大事,走开源线,其实也是智谱的背景。
这使得智谱实际上成为今天最全面的模型公司之一——智谱开发基本模型GLM-4-Plus,GLM-4V多模态理解模型 ,探讨复杂的推理模式 GLM-Zero ,CogVideoX视频生成模型,AutoGLMM也有创新实验。、 GLM-PC等。
与其它公司相比,智谱这是AGI列出路线图最明确的公司。
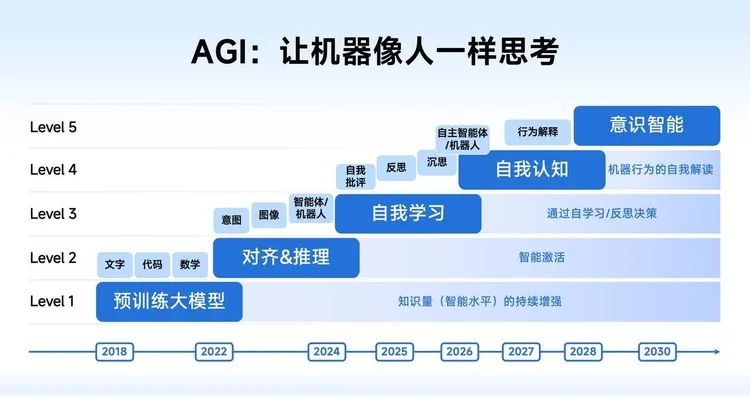
按照唐杰的分享,他将AGI分为五个阶段,L1展示了世界知识和推理能力;L2 时间多模态对齐后有更深层次的推理能力; L3 层次,原生多模态模型可以实现人类般的感觉和联觉。(Synesthesia),以及物理世界与虚拟环境的融合,以及L3 自学阶段,AI 自我学习可以通过自我分析、反思甚至思考来实现;L4 当时,机器开始实现自主学习;L5 观念智能是 AGI 最后一个层次,即 AI 将来的某一天,会有一些想法,能像人一样突破现在的天花板,去探索、研究、寻找新的科学边界。
在巴黎AI峰会上,唐杰表示:我们现在正处于L2与L3的交界处。
可以看出,这个过程是各种技术拼图最后拼在一起的过程。所以,当整个行业转向模型的结合时,谁能把推理模型和多模式模型结合到底座模型之上,成为一个新的模型和更强的模型,谁就能找到下一个大的范式创新,前提是先有这些需要的拼图。
AI已经出现了这种趋势 在Agent的方向上进行预演。AI Agent是一个结合多种模型技术的概念。Agent反映了智谱对整个路线各个环节的全面追求。
最早开始研究Agentic是智谱。 与今年1月推出的智能体系相比,LLM的公司之一 Operator和Deep ResearchOpenAI,在此之前,智谱还发布了Agent、AutoGLM和GLM的智能手机,-PC,并且使用Agentic 三星手机上放置了GLM。
“2025 2008年,具有代理能力的自主大型语言模型(Agentic LLMs)唐杰在巴黎AI峰会上说,这将是日常生活和工作的一部分。
DeepSeek对OpenAI的“超车”表明,AGI的实现过程仍然是一场马拉松,在整个漫长的道路上,领导者将会更换,最终成为一个群体接力实现最终目标的过程。
在这场人群接力赛中,有DeepSeek、智谱和其他中国球员。
本文来自微信公众号“硅星人Pro”,作者:王兆洋,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com