
怎样做机器人泛化?银河通用,灵初智能,星海图给出三条路径








最近,黄仁勋出现了 CES Cosmos在世界基础模型开发平台上发布,可以大规模生成基于物理世界的合成数据,为机器人提供接近现实世界的虚拟训练场,有利于提高机器人的泛化能力。
提高机器人泛化能力的关键之一在于数据的丰富性和准确性。英伟达不仅探索了这一目标,而且清华和北京大学的研究团队最近也密集发布了研究成果,探索如何通过低成本实现丰富的数据训练。他们主要利用模拟数据和真实数据的差异组合,目前的尝试集中在以下三种方式:
首先,以生成模拟数据为主,如银河通用。建立于银河通用 2023 年初,这背后是北京大学助理教授王鹤,包括前如布科技联创尹方鸣和姚腾洲。银河通用是低成本模拟路线的支持者。经过两年的努力,公司最近推出了商品 GraspVLA。
它的想法与之相似 RoboCasa 和 RoboGen,机器人训练数据是在大量生成的模拟环境中生成的。GraspVLA致力于抓取任务,通过在模拟中安排预训练。 AnyGrasp 模型采集数据,用来训练一个 VLA。另外,在模拟环境中加入了大量的随机设计,进一步提高了VLA模型的泛化能力。



(AnyGrasp、GraspVLA、OpenVLA 视频对比demo)
二是结合模拟数据和真机信息进行联合训练,灵初智能是这个角度的代表公司之一。该公司成立于2024年9月,由前京东机器人总裁王启斌、机器人算法负责人柴晓杰和李飞飞的学生陈源培联合成立。科学家团队包括北京大学助理教授杨耀东和梁一韬。

(上面是Psi demo视频R0)
灵初智能的技术路线类似于银河通用,模型也在模拟环境中进行大规模的预训练。其特点是在模仿学习中引入强化学习技术,结合真实机器数据进行微调训练。这种方法促使不同技能的顺畅衔接和操作,即使只使用少量的模拟和真实机器数据,也能完成高度泛化的复杂任务。
灵初智能于2024年12月底发布。 Psi R0 模型,该模型成功完成了双手合作的长程泛化包装任务,显示出实现商业化的潜力。此前,灵初智能还发布了完成长程灵巧手任务等其他有代表性的成果 Lego 装配,突破传统强力抓取能力的边界,完成更加灵活的抓取和高精度的动作。
据公开资料显示,灵初智能计划于2025年3月发布自研本身及更泛化的具身大模型。
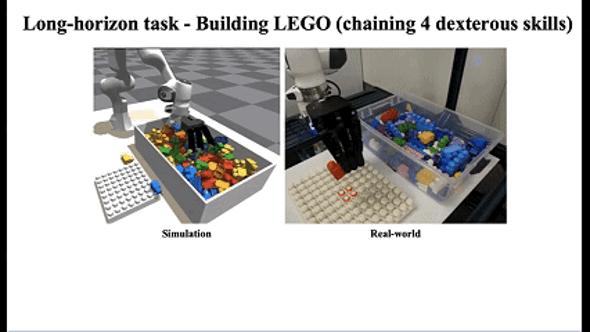
(上述是Lego组装视频)
三是以真机数据为主的训练方法,星海图是这个方向的典型代表。公司成立于2023年9月,由清华系背景团队成立。星海图的CEO是前Momenta执行董事高继扬,科学家团队包括清华助理教授赵行和许华哲。

(上述星海图real2sim2real视频demo)
星海图在数据策略上采取了与其他公司完全不同的观点,认为数据价值排名如下:真机数据 > 互联网数据 > 模拟数据。他们计划在2024年发布100万台真机数据,并在2025年扩展到1000万台。这些信息将成为星海图构建大型模型的关键,而不是依靠灵初智能和银河通用的大型模拟数据预训练。
但是,大型真机数据也存在一些问题,例如数据的多样化。(diversity)缺点,模型泛化能力可能受到限制。为了解决这个问题,星海图提出了这个问题 Real2Sim2Real 实践策略。具体而言,他们利用真实数据,通过模拟环境中的随机扩展,将数据规模扩展到原来的1000倍。这类仿真数据仅作为后训练的强化剂,旨在提高模型的成功率和实际应用效果,从而达到更有效的落地能力。
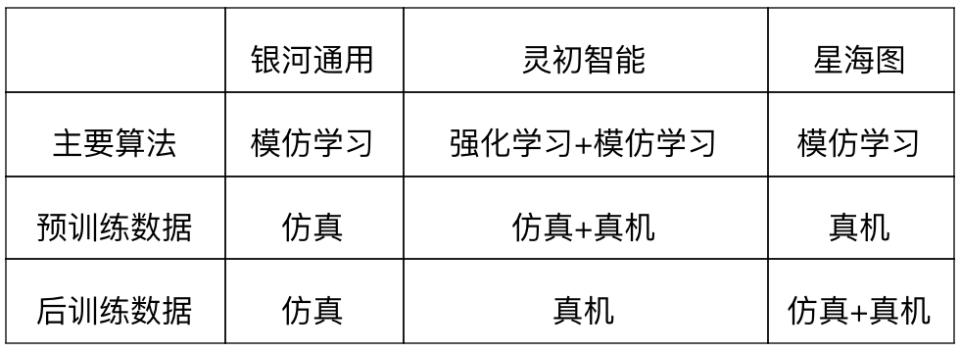
这三个清北团队在算法和数据策略上表现出不同的侧重点:灵初智能在算法上突出了加强学习的应用,银河通用侧重于模拟数据的优势,而星海图则更注重真实数据的核心价值。然而,他们都采用了模拟数据与真实数据相结合的方法,但数据比例的侧重点在预训练和后训练阶段是不同的。
另外,清华北大最近还有许多值得关注的结果。比如清华星动时代ERA-42、RoboMindDind,北大和国地共创智能中心。、OmniManip北大和智元、Data和清华千寻智能CoPa Scaling Law等。
本文来源于“腾讯科技”,作者:周小燕,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com