
大模型时代结束了?老板们都预测,AI模型可能需要先缩小规模,然后才能再次扩大规模。





小型强势袭击,「大模型时代」或将落幕?
「小模型周」过去了 ,最新的小模型战场刚刚开启。
GPT-4o上周 mini和Mistral NeMo二连发,「苍蝇再小,五脏俱全」小模型已经成为业界领袖高度关注的新方向。

所以,大模型是否会失宠呢? Scaling Law会失效吗?
Andrej之前的OpenAI和特斯拉AI研究员 刚刚进入AI教育的Karpathy,「K老师」最近发表文章引导行业迷津,揭示了科技巨头纷纷转向小模型研发背后的新趋势:AI大模型的竞争将会逆转。
他预测,未来的模型将会更小,但仍将变得更加智能。
与其他同行相比,人工智能巨头和一些新的独角兽最近发布了更紧凑、更强大、更实惠的人工智能模型。最新的例子是OpenAI的GPT-4o。 mini。
Karpathy预测这种趋势将会持续下去。他写道,「我敢打赌,我们会看到很多有效可靠的思维模式,而且体积特别小。」
小型:站在巨人的肩膀上
在LLM发展的早期阶段,吞吐更多的数据,使模型变大是必然趋势。这主要是基于以下原因:
第一,需要数据驱动。
生活在数据爆炸的时代,大量丰富多样的数据需要更强大的模型来处理和理解。
通过大规模的数据训练,大型模型具有容纳和处理海量数据的能力,可以探索出深层次的方法和规律。
第二,计算能力的提高。
随着硬件技术的不断发展,GPU等高性能计算设备的发展,为大型模型的实践提供了强大的计算率支持。有可能训练大型复杂的模型。
第二,追求更高的性能和精度。
一般来说,大型模型可以在语言逻辑、生成、图像识别等诸多领域表现出优异的性能。你知道的越多,你产生的结果就会越准确。
最后,泛化能力很强。
大模型可以更好地处理从未见过的新问题和新任务,可以根据之前学过的知识进行合理的推断和回答,具有更强的泛化能力。
再加上AI领域的激烈竞争,所有的研究机构和巨头都致力于开发更大更强的模型,展示自己的技术水平和领先水平,卷模的大小自然成为LLM的一大发展方向。
Karpathy还将目前最强大的模型规模归因于训练数据的复杂性,并补充说大语言模型在记忆上表现出色,超越了人类的记忆能力。
相比之下,如果你想在期末周接受闭卷考试,考试要根据之前的单词背诵课本上的某一段。
这就是今天大模型的预训练目标。Karpathy说,现在的大模型就像一条贪婪的蛇,只想把所有可用的数据都吞进肚子里。
他们不但可以背诵常用数字的SHA系列哈算法,而且可以记住各个领域的大小知识。
但是,这种学习方法就像你为了考试,把整个图书馆和网络上的内容都背下来一样。
不可否认,能够实现这种记忆的是天才,但考试结果只用了一页!
对这类天才学生-LLM想要做得更好之所以难,是因为在训练数据的过程中,思维演示和知识「纠缠」在一起。
而且,从实际应用的角度来看,大型模型在部署和运行过程中面临着高昂的成本和能源消耗,包括计算资源、存储资源和能源消耗。
在各种设备和场景下,小型模型更容易部署,满足使用方便、功耗低的需要。
另一方面,从技术成熟的角度来看,这些知识和模式可以在小模型设计和优化中提炼和应用,当问题的本质和规律通过大模型得到充分的探索和理解。
在保证大模型同等性能甚至更好性能的前提下,促使小模型降低规模和成本。
虽然大模型的发展遇到了瓶颈,小模型逐渐成为一种新的趋势,但Karpathy强调,大模型仍然是必要的,即使它们没有得到很好的训练,小模型也是从大模型中浓缩出来的。
Karpathy估计,每一个模型都会不断完善,为下一个模型生成训练数据,直到出现。「完美训练集」。
即使像GPT-2这样的模型有15亿个参数,当你用这个完美的训练集训练GPT-2时,它也可能成为一个非常强大和智能的模型,按照今天的标准。
这种经过完美训练训练的GPT-2可能在大规模多任务语言逻辑中进行训练(MMLU)测试分数会略低。MMLU测试包括初等数学、美国历史、计算机科学、法律等57项任务。用于评估大模型的基本知识覆盖面和理解能力。
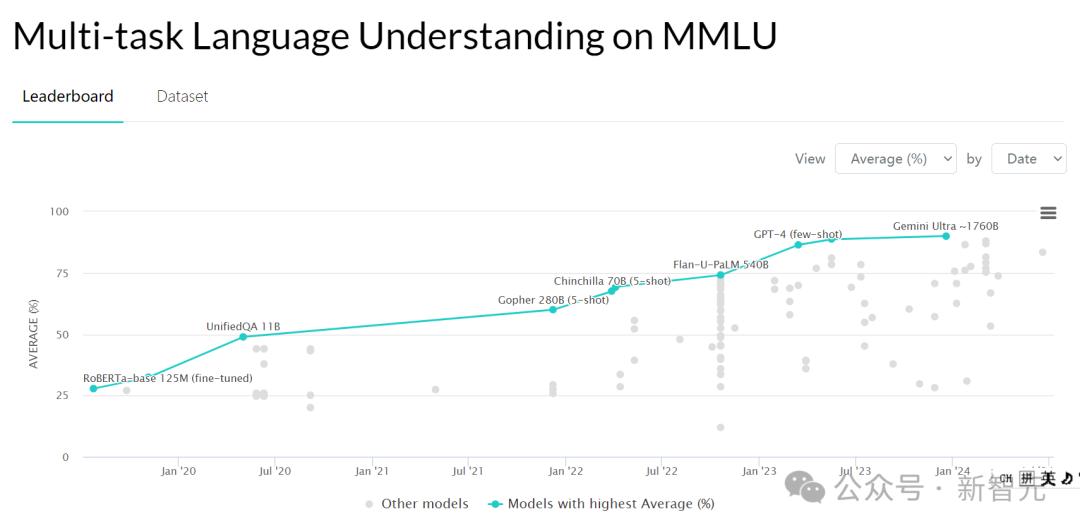
但是未来更加智能化的人工智能模型并没有走量取胜,它可以更加可靠地检索信息,验证事实。
正如一位学霸做开卷考试一样,虽然并非所有的知识都烂熟于心,但能准确地定位正确答案。
根据报道,OpenAI的Strawberry项目专注于解决这一问题。
「虚胖」大模型的「瘦身」
正如Karpathy所说,大多数经过大量数据训练的超大型模型(如GPT-4)实际上是用来记住大量无关紧要的细节,即死记硬背数据。
这与模型预训练的目的有关。在预训练阶段,模型被要求尽可能准确地重复下一个内容,这相当于背诵课文。记忆越准确,分数越高。
虽然模型可以学习里面反复出现的知识,但是数据有时候会出现错误和偏见,模型在微调之前要记住所有的知识。
Karpathy认为,如果有更高质量的训练数据集,完全可以训练出一个规模更小、能力更强、推理能力更强的模型。
在超大型模型的帮助下,一键生成,清理出更高质量的训练数据集。
类似于GPT-4o mini,就是用GPT-4清洗出来的数据进行训练。
先把模型做大,然后在此基础上,「瘦身」,这种趋势可能是模型发展的新趋势。
做一个生动的比喻,就像目前的大模型有太多的数据和肥胖问题一样。经过数据清洗和大量训练,它已经变成了一个肌肉细腻的小模型。

这个过程就像一个循序渐进的进化,每一代模型都会帮助生成下一代的训练数据,直到我们最终得到一个「完美训练集」。
OpenAICEOSam Altman也发表了类似的言论,大型AI模型模型早在2023年4月公布。「时代结束」。
无论是真实数据还是生成数据,数据质量都是AI训练的关键成功因素也越来越成为共识。
奥特曼认为,关键问题是人工智能系统如何从较少的数据中学习更多的物品。
在开发Phi模型时,微软研究人员也做出了同样的判断,Hugging Face AI研究人员也同意追求高质量的数据集,并发布了高质量的培训数据集。
这意味着盲目扩张不再是科技巨头的唯一技术目标,即使是小而优质的模型也能从更多、更多样化、更优质的数据中受益。
回到更小、更有效的模型可以看作是下一个整合阶段的目标,OpenAI模型的发布将明确说明未来的发展方向。
评论区:正确的,中肯的,一阵见血的。
Karpathy还提到了类似于特斯拉在自动驾驶网络上的做法。
特斯拉有个名字「离线追踪器」运行前的弱模型,可以生成更干净的训练数据。
马斯克一听说特斯拉技术被cue领先于时代,就迅速赶往评论区:
评论区的网友们对Karpathy的真知灼见也纷纷表示,臣附议!
对未来的通用人工智能而言,更小、更有效的人工智能模型可能会在人工智能中重新定义「智能」,挑战「越高越好」的假设。
作者SebastiannPython机器学习 Raschka认为,这就像知识蒸馏,从27B的大模型中蒸馏出Gemma-2这样的小模型。
同时,他也警告我们,MMLU这种多选题测试,可以测试知识,但不能完全体现实际能力。
还有一些网友脑洞大开,如果小模型表现良好,那么术有专攻,为什么不需要更多的小模型来产生一个一个的答案?
聚集10个AI助手,然后让最聪明的那个做最后的总结,简直就是AI版的智囊团。
所以,AGI究竟是一种全方位的大型模型,还是来自许多小型模型的合作?
参考资料
https://the-decoder.com/ai-models-might-need-to-scale-down-to-scale-up-again/
https://x.com/karpathy/status/1814038096218083497
本文来自微信微信官方账号“新智元”,作者:耳朵,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com