
小米打响Token价格战:降幅最高99%,国产大模型赛道生变






本文来自微信公众号:APPSO,作者:发现明日产品的
此前看涨2026年Token价格的行业观察者,短短一周内接连迎来两次出乎意料的行业变动。
5月22日,DeepSeek率先宣布DeepSeek V4 Pro永久降价;就在5月27日凌晨,小米跟进推出MiMo-V2.5系列大模型降价调整,最高降幅达到了99%。
除了直接下调API定价,小米还同步优化了Token Plan计费体系,在保持原有月费定价不变的前提下,将可用Token额度提升到原来的5到8倍。

消息放出后,海外Reddit、X平台以及全球各大开发者社区里,关于小米MiMo模型降价的讨论热度迅速上涨,很快成为AI圈的热门话题。

如今全行业都在感叹大模型Token成本高企,小米为什么偏偏选择在这个时候逆势降价?这一波价格操作,又会给国内AI大模型行业带来怎样的变化?
最高降幅九成九,定价规则贴合真实生产场景
根据小米官方公告,此次旗下AI大模型MiMo-V2.5系列的API调整为永久降价,最高降幅达99%,并且新定价不再区分上下文长度,新价格已经在北京时间5月27日0点面向全球同步生效。
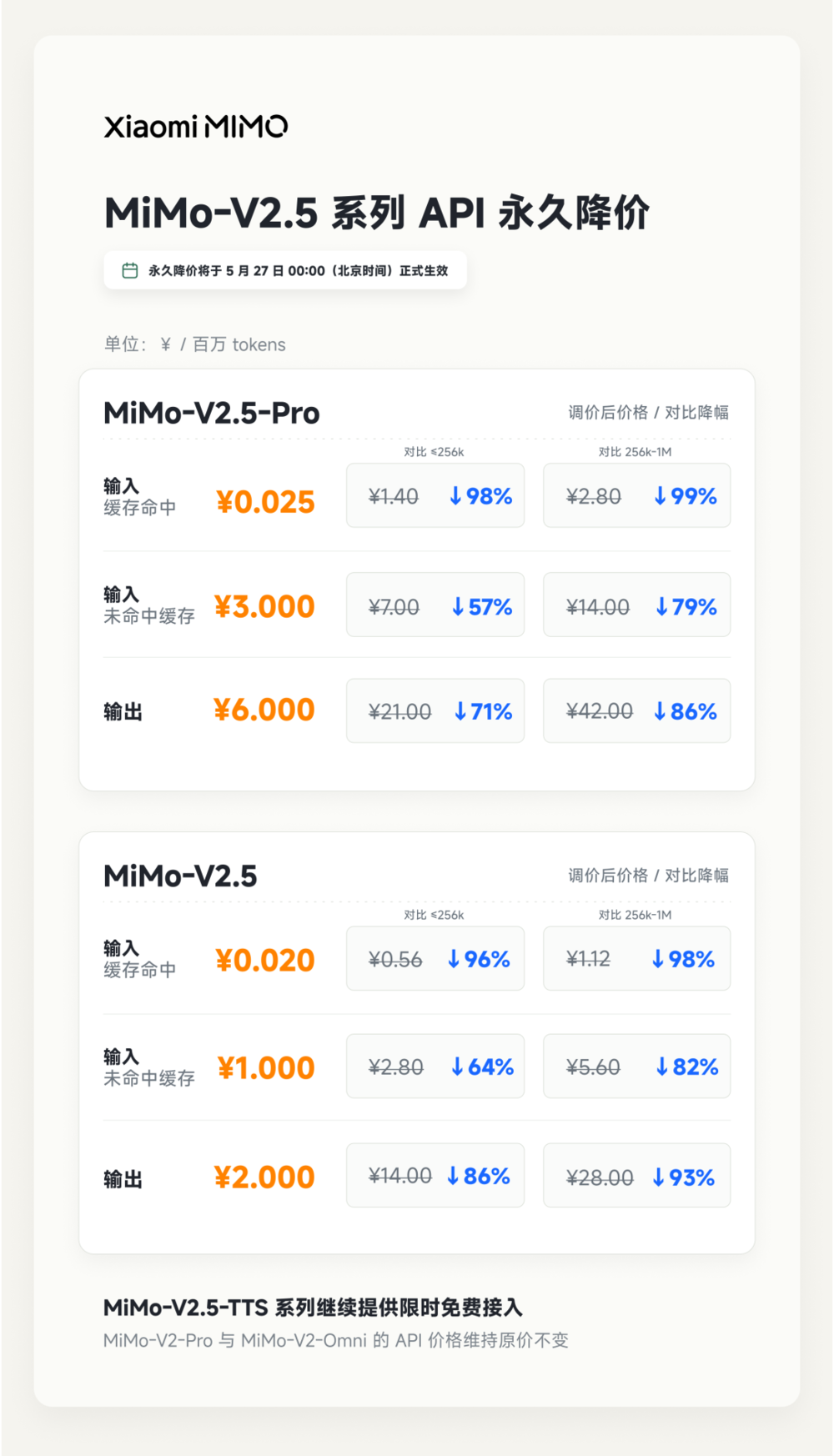
需要说明的是,99%的最高降幅并非所有调用都按最低价计费,价格差异的核心在于输入缓存是否命中。
以MiMo-V2.5-Pro为例,如果请求命中缓存,输入价格可以低至每百万Tokens约0.025元;如果输入缓存没有命中,输入价格则维持在每百万Tokens 3元,输出价格为每百万Tokens 6元。
也就是说,这个极低价格成立的前提,是请求能大量命中缓存。
对于高重复上下文场景、高频Agent应用、多轮代码开发任务以及批量推理任务来说,这个定价的吸引力极强;但如果应用场景的缓存命中率本身很低,实际使用的成本自然不会降到最低点。
升级后的Token Plan也遵循了类似的定价逻辑。
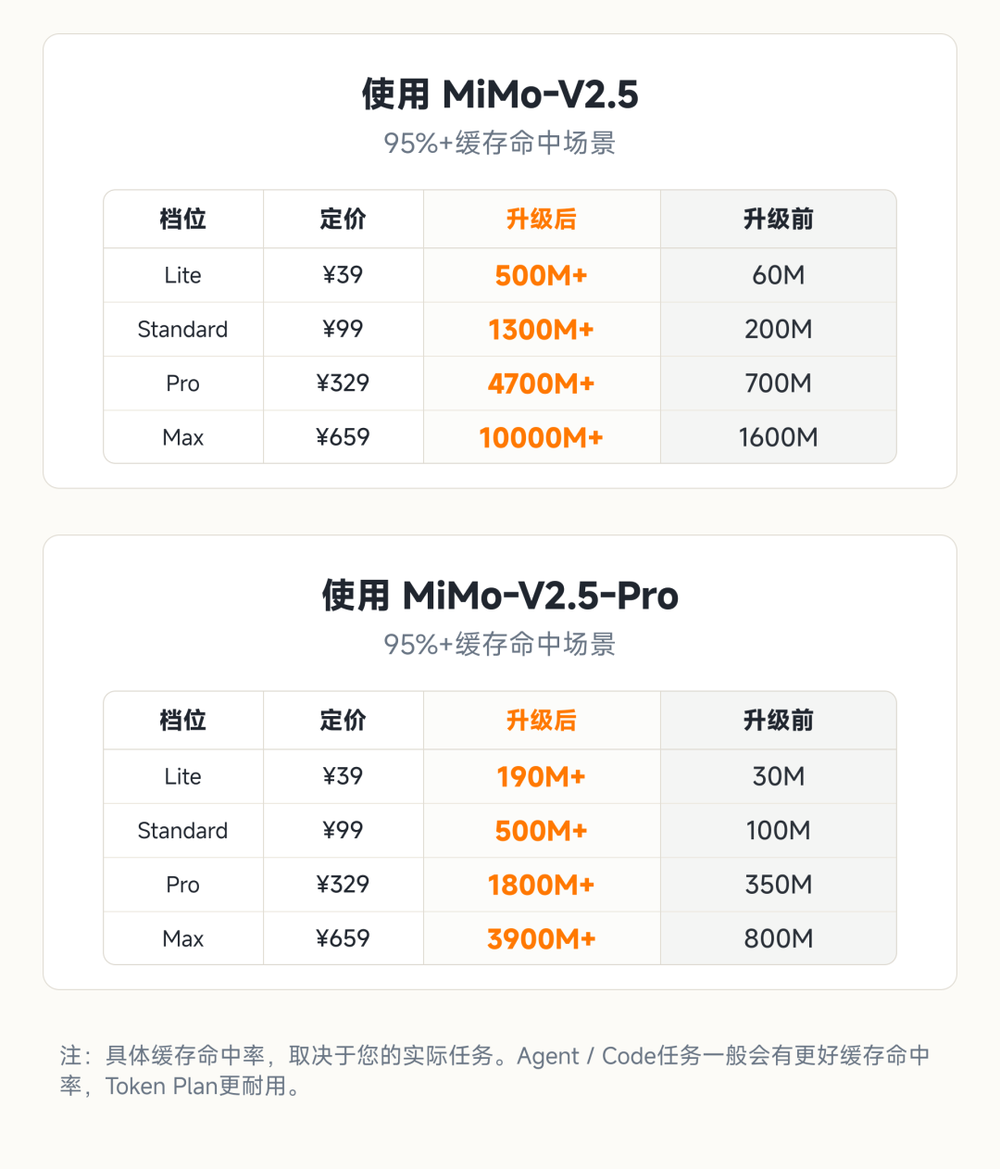
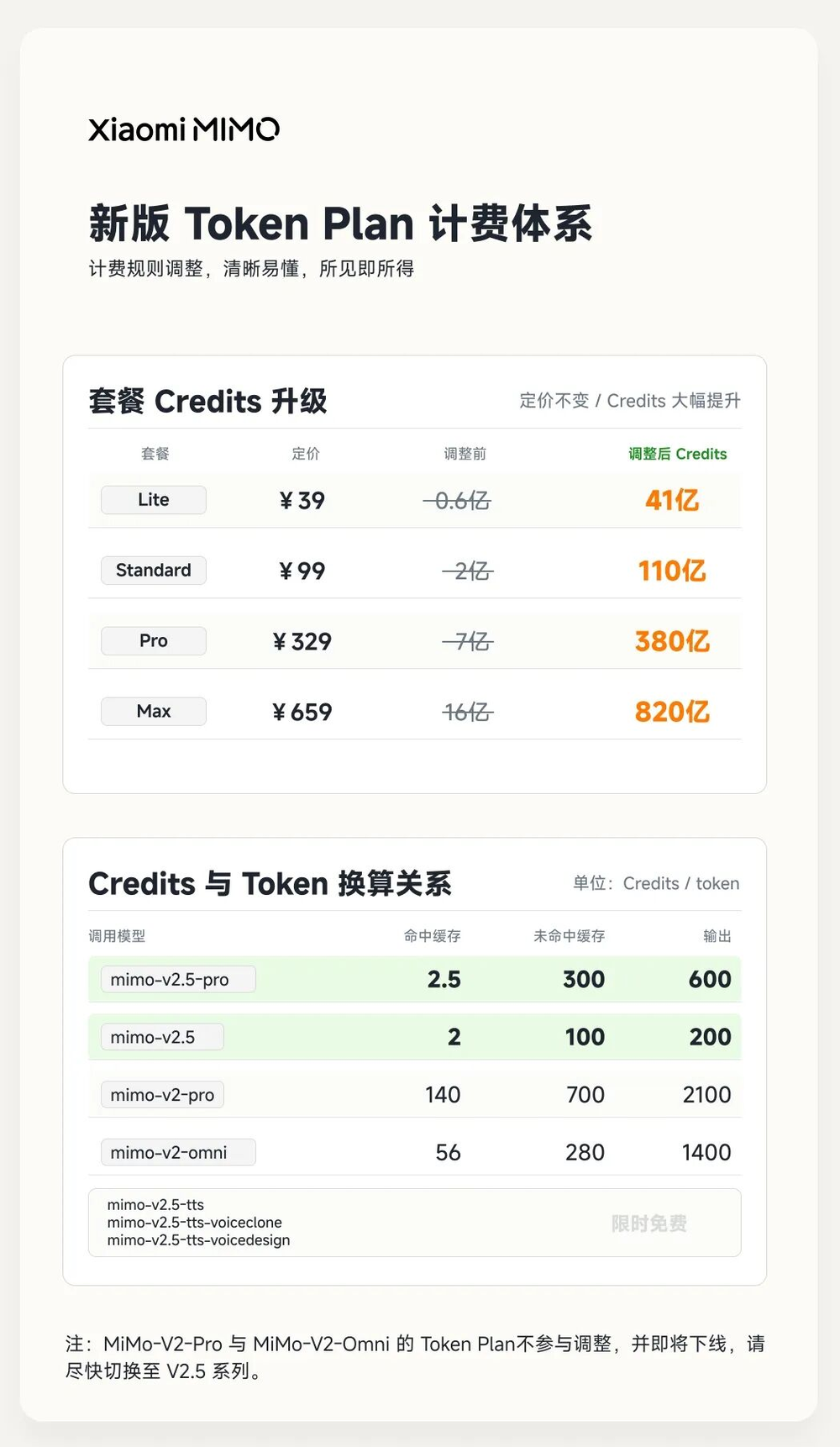
小米保持原有四档月费定价不变:Lite、Standard、Pro、Max四个档位的月费依然是39元、99元、329元和659元,但可使用的Credits额度,已经从原来的0.6亿、2亿、7亿、16亿,分别提升到了41亿、110亿、380亿、820亿。
按照新的Credits换算规则,MiMo-V2.5-Pro缓存命中仅需要2.5 Credits每token,未命中缓存需要300 Credits每token,输出则为600 Credits每token。
小米这次的打法,和此前DeepSeek的操作思路高度一致。我们可以简单梳理时间线:4月24日DeepSeek发布V4预览版;次日V4-Pro就开启2.5折优惠;4月26日缓存命中价格进一步降到首发价的十分之一;到5月22日,临时折扣直接转为永久降价,V4-Pro最终降到了原价的四分之一。
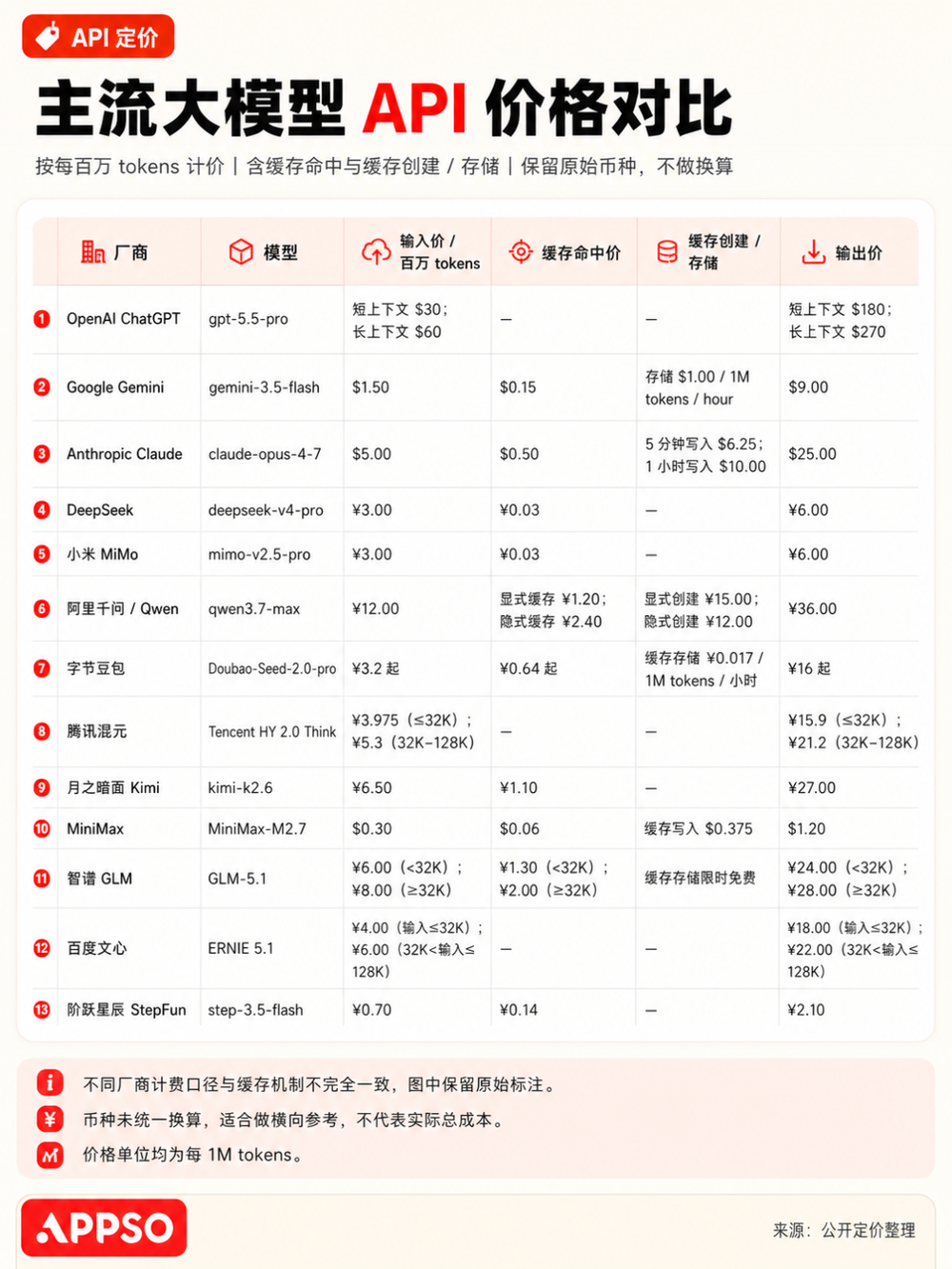
经过这一轮调整,DeepSeek-V4-Pro的缓存命中输入价格已经从0.1元降到0.025元。而小米MiMo-V2.5-Pro的火速跟进,直接把国产大模型的缓存命中输入价格稳定在了0.025元这个低位基准线。
DeepSeek和小米都选择把最低价放在缓存命中场景,原因其实很清晰:当前大模型已经从单纯的聊天对话,转向落地实际生产任务,而Agent才是Token消耗真正大幅增长的领域。
在普通聊天场景里,用户提问一次,模型回答一次,Token成本相对容易控制和估算。
但在Agent场景中,一个完整任务往往包含长上下文处理、多轮推理、代码生成、工具调用、内容读取、文件分析和结果校验多个环节。用户最终只看到一次输出,后台却已经完成了多次请求,重复读取了大量上下文内容。
这就是缓存命中定价的核心意义所在。
Agent应用、代码助手、长上下文工具都有一个共同特点:很多内容会被重复调用,比如系统提示词、项目代码、API文档、工具说明、历史对话、依赖文件等等。这些内容如果每次请求都重新计算,成本会非常高;但如果可以缓存,下次使用时只按缓存价格计费,推理成本就能大幅降低。
换句话说,缓存命中定价越低,就越适合高频、多轮、长上下文的真实生产场景。DeepSeek和小米打出低价,本质上是希望吸引开发者和高频应用迁移到自己的模型平台,让更多Agent、代码助手、办公自动化应用选择部署在自己的生态中。
实际上小米此前就已经通过MiMo Orbit、百万亿Token创造者激励计划等活动,吸引用户体验MiMo模型、解决真实问题。这个百万亿Token激励计划从4月28日上线,到5月26日16:08,100T Tokens就已经全部提前发放完毕,可见开发者的参与热度非常高。
从平台的角度来看,低价Token和免费额度换来的是海量真实调用数据。这些真实调用会产生复杂任务、失败样本、用户反馈、Agent工作流、代码场景和长上下文数据,反过来又能帮助模型和推理系统完成技术迭代。
开发者社区里所谓的“养虾党”现象,也符合这个逻辑:用户在最大化使用免费额度的同时,其实也在帮助平台测试负载、暴露系统问题、积累真实调用数据。
所以算这笔账不能只看单次推理的短期毛利,压低短期收入,换来的是开发者迁移、调用规模增长和真实产品反馈,对于想要抢占Agent生态位置的模型厂商来说,这是一笔性价比极高的平台投入。
低价背后是技术支撑,行业筛选加速到来
不过小米这次降价,最有意思的一点在于,它和小米MiMo大模型负责人罗福莉此前的公开表态形成了有趣的反差。
一个月前,罗福莉还公开反对Token价格战,她当时的判断是:无底线的低价Token加上开放第三方Agent框架,很容易让平台陷入成本失控的困境。
她当时提到,第三方Agent框架往往对上下文管理比较粗放,单次用户查询就可能触发多轮低价值工具调用,每次请求还要携带超过10万token的超长上下文。如果平台没办法约束这类无效消耗,真实的API成本可能会达到订阅价格的数十倍。
她还认为,当前全球算力供给已经跟不上Agent带来的Token需求增长,大模型企业在没有厘清编程和Agent场景成本结构之前,盲目打价格战最终会导致限流、降配、稳定性下降,反而会损害用户体验。
而小米这次降价,其实并没有推翻此前的判断,只是改变了价格战能够成立的前提:罗福莉此前反对的是没有成本结构支撑的亏本低价,但现在小米已经拿出了能够支撑低价的工程技术方案。
根据小米官方披露,其技术团队基于SGLang HiCache完整支持了SWA也就是滑动窗口注意力机制,将KV缓存在GPU显存、CPU内存、SSD等多级存储之间的数据搬运量,降低到优化前的近七分之一,同时把可缓存的Token数量提升到优化前的近五倍。
除此之外,小米还优化了专家并行方案和输入长度分桶策略,提升了集群的输入吞吐能力。如果没有这样的工程技术能力,低价很容易变成不可持续的补贴;只有拥有足够强的底层基础设施能力,低价才能转化为长期的市场优势。
价格战考验的不只是工程技术,还要考验企业的后方支撑厚度。
和纯AI模型创业公司不同,小米本身拥有手机、汽车、IoT以及消费电子等成熟主业,这些业务能给大模型业务提供更长的投入周期,也让小米拥有更大的战略耐心,可以把大模型服务当作AI生态的入口来布局,不用陷入只盯着短期API收入计算盈亏的困局。
这种降价对于中小模型厂商来说并不友好:没有主业输血、没有过硬的底层基础设施能力、也没有足够调用规模摊薄成本的玩家,根本没办法长期跟进这样的低价。
DeepSeek的降价已经直接冲击了不少海内外模型的市场定位,而小米MiMo跟进降价之后,更多有一定规模的厂商都会被迫调整定价,或者重新定位自身产品价值;规模更小的模型服务商,大概率会被挤压到更细分垂直的窄赛道中。
从这个角度看,这一轮降价其实是效率导向的模型厂商对行业的一次筛选:拥有工程能力、算力调度能力和生态入口的企业,才能承受更低价格带来的压力;只有模型能力、但推理成本没办法降下来的企业,会越来越被动。
而且随着Token价格下探的空间越来越小,价格越接近物理成本,单纯降价带来的竞争价值就越有限,下一阶段,大模型行业会在模型质量、Agent适配、开发者工具、生态绑定、服务稳定性和企业交付能力等多个维度展开新一轮竞争。
模型能力决定了AI发展的上限,而推理成本决定了AI普及的规模。当足够便宜的Token真正普及到应用层,我们才能真正看清,AI的下一个爆发时代究竟是什么样子。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com