
DeepSeek全新OCR模型:模拟人类阅读逻辑,文档理解能力大幅提升







▲头图由AI生成
智东西1月27日消息,DeepSeek刚刚开源了针对OCR场景的专用模型DeepSeek-OCR 2,并且同步发布了技术报告。该模型是去年DeepSeek-OCR模型的升级版,其采用的新型解码器让模型看图、读取文件的顺序更贴近人类的阅读习惯,而非像机械扫描仪那样刻板。
简单来讲,以往的模型阅读方式是从左上角到右下角,对图片进行地毯式扫描,而DeepSeek-OCR 2能够理解图片的结构,按照结构逐步读取内容。这种全新的视觉理解模式,使DeepSeek-OCR 2可以更好地解读复杂的布局顺序、公式以及表格。
在文档理解基准测试OmniDocBench v1.5中,DeepSeek-OCR 2取得了91.09%的得分。在训练数据和编码器均保持不变的情况下,相比DeepSeek-OCR提升了3.73%。与其他端到端的OCR模型相比,这已是最优成绩,不过其表现略低于百度的PaddleOCR-VL(92.86%)OCR管线。
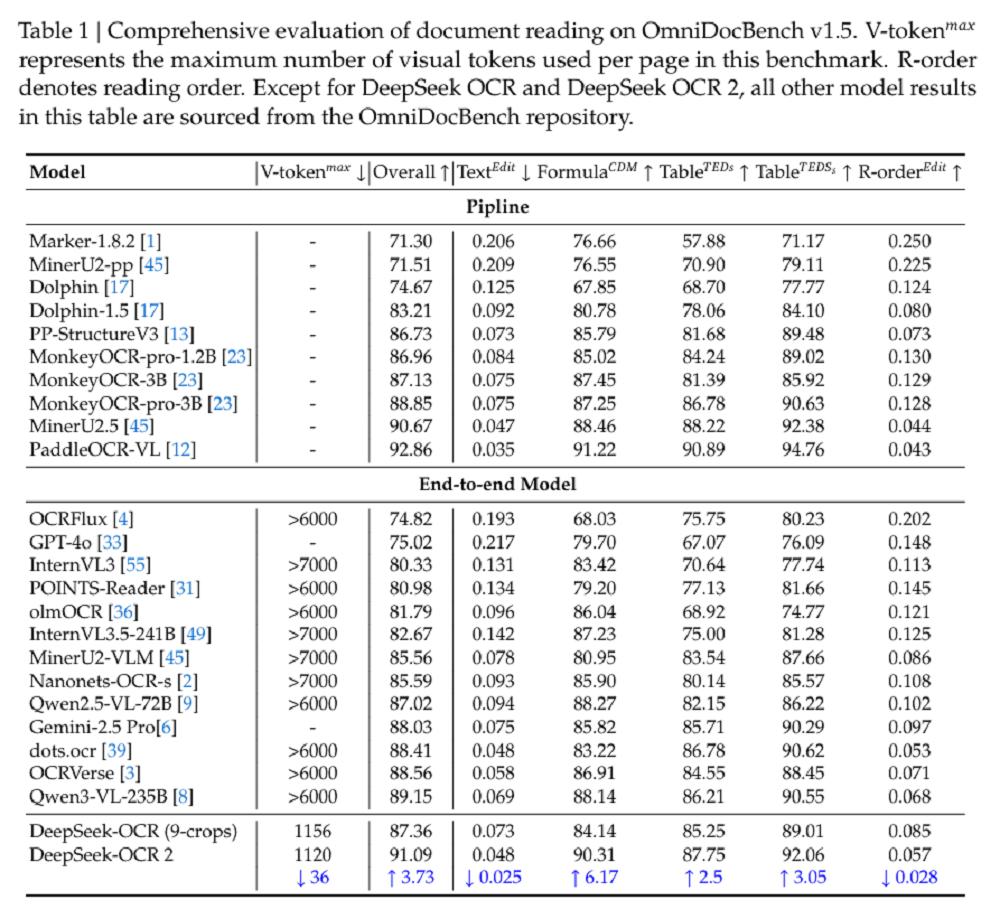
同时,在视觉token预算相近的情况下,DeepSeek-OCR 2在文档解析方面的编辑距离(将文本修改为正确内容所需的工作量)低于Gemini-3 Pro,这表明DeepSeek-OCR 2在保证出色性能的同时,还维持了视觉token的高压缩率。
DeepSeek-OCR 2具有双重价值:既可以作为新型VLM(视觉语言模型)架构开展探索性研究,也能充当生成高质量预训练数据的实用工具,为大语言模型的训练过程提供服务。
论文链接: https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
开源地址: https://github.com/deepseek-ai/DeepSeek-OCR-2?tab=readme-ov-file
01.大模型难以理解复杂文件结构?先观察全局再阅读即可解决
从架构角度来看,DeepSeek-OCR 2延续了DeepSeek-OCR的整体架构,该架构由编码器和解码器构成。编码器将图像转化为离散的视觉token,解码器则依据这些视觉token和文本提示生成输出内容。
关键的区别在于编码器:DeepSeek将之前的DeepEncoder升级为DeepEncoder V2,它保留了原有的全部功能,但把基于CLIP的编码器替换成了基于LLM的编码器,同时通过新的架构设计引入了因果推理机制。
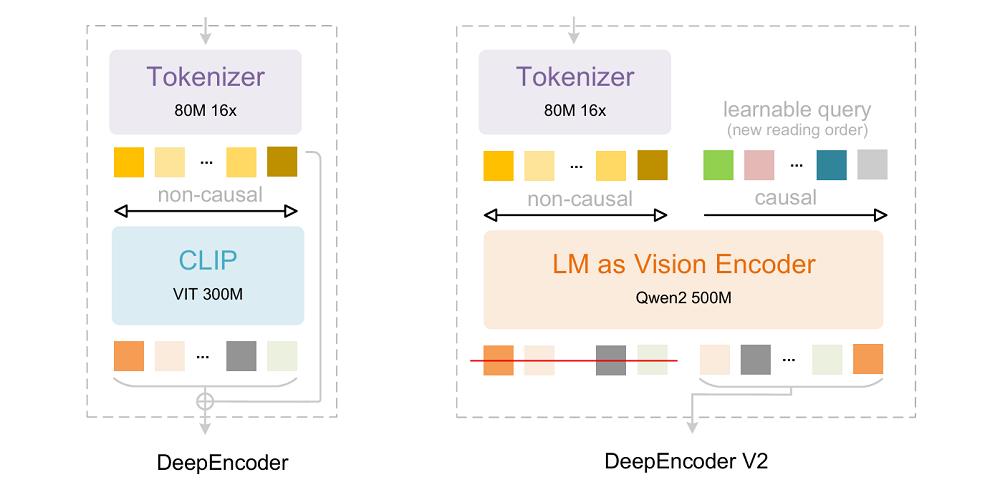
DeepEncoder V2关注的核心问题是:当二维结构被映射为一维序列并绑定线性顺序后,模型在构建空间关系时会不可避免地受到该顺序的影响。
这种情况在自然图像中或许还能接受,但在OCR、表格、表单等布局复杂的场景中,线性顺序往往与真实的语义组织方式存在很大差异,进而限制了模型对视觉结构的表达能力。
DeepEncoder V2是如何解决这一问题的呢?它首先运用视觉tokenizer对图像进行高效表示,通过窗口注意力实现约16倍的token压缩,在大幅减少后续全局注意力计算和显存开销的同时,保留了充足的局部与中尺度视觉信息。
它没有依赖位置编码来规定视觉token的语义顺序,而是引入了因果流查询(causal queries),通过内容感知的方式对视觉标记进行重新排序与提炼。这种顺序并非由空间展开规则决定,而是由模型在观察全局视觉上下文后逐步生成,从而避免了对固定一维顺序的过度依赖。
每个因果查询都可以关注所有视觉token以及先前的查询,这样在保持token数量不变的前提下,就能对视觉特征进行语义重排序和信息提炼。最终,只有因果查询的输出会被送入下游的LLM解码器。
该设计本质上形成了两级级联的因果推理过程:首先,编码器内部借助因果查询对无序的视觉标记进行语义排序;随后,LLM解码器在这个有序序列的基础上执行自回归推理。
与通过位置编码强制施加空间顺序的方法相比,因果查询所引导的顺序更符合视觉语义本身,也就是与人类正常的阅读习惯相一致。
由于DeepSeek-OCR 2主要侧重于编码器的改进,并未对解码器组件进行升级。遵循这一设计原则,DeepSeek保留了DeepSeek-OCR的解码器:一个拥有约5亿活跃参数的3B参数MoE结构。
02.OmniDocBench得分达91.09%,编辑距离低于Gemini-3 Pro
为了验证上述设计的有效性,DeepSeek开展了实验。研究团队分三个阶段对DeepSeek-OCR 2进行训练:编码器预训练、查询增强以及解码器专业化。
第一阶段让视觉tokenizer和LLM风格的编码器具备特征提取、token压缩和token重排序的基本能力。第二阶段进一步增强了编码器的token重排序能力,同时强化了视觉知识压缩。第三阶段冻结编码器参数,仅对解码器进行优化,从而在相同的FLOPs下实现更高的数据吞吐量。
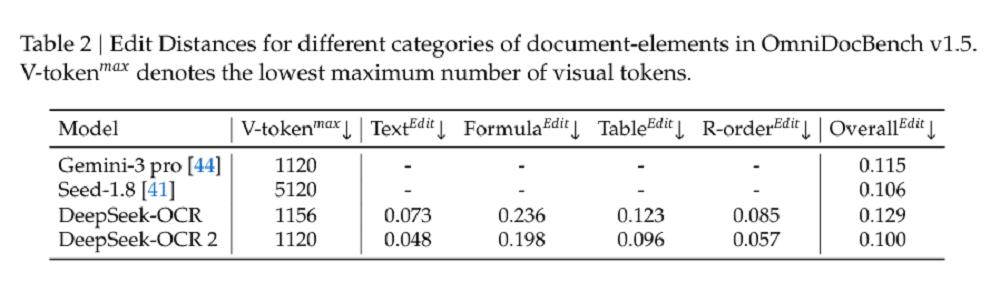
为评估模型效果,DeepSeek选择OmniDocBench v1.5作为主要的评估基准。该基准包含1355个文档页面,涵盖中英文的9个主要类别(包括杂志、学术论文、研究报告等)。
DeepSeek-OCR 2在仅使用最小视觉标记上限(V-tokenmaxmax)的情况下,就获得了91.09%的性能得分。与DeepSeek-OCR基线相比,在训练数据源相似的情况下,它的性能提升了3.73%,这验证了新架构的有效性。
除了整体性能的提升外,阅读顺序(R-order)的编辑距离(ED)也显著降低(从0.085降至0.057),这表明新的DeepEncoder V2能够根据图像信息有效地选择和排列初始视觉标记。
在视觉标记预算相近(1120)的情况下,DeepSeek-OCR 2(0.100)在文档解析方面的编辑距离低于Gemini-3 Pro(0.115),进一步证明了新模型在保证性能的同时,还维持了视觉标记的高压缩率。
不过,DeepSeek-OCR 2也并非十全十美。在文本密度极高的报纸上,DeepSeek-OCR 2的识别效果不如其他类型的文本。这一问题后续可以通过增加局部裁剪数量或者在训练过程中提供更多样本来解决。
03.结语:有望成为新型VLM架构的开端
DeepEncoder V2为LLM风格编码器在视觉任务中的可行性提供了初步验证。更重要的是,DeepSeek的研究团队认为,该架构具备演变为统一全模态编码器的潜力。这样的编码器能够在同一参数空间内压缩文本、提取语音特征并重组视觉内容。
DeepSeek表示,DeepSeek-OCR的光学压缩代表了向原生多模态的初步探索,未来,他们还将继续探索通过这种共享编码器框架整合更多模态,使其成为研究探索新型VLM架构的开端。
本文来自微信公众号 “智东西”(ID:zhidxcom),作者:陈骏达,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com