
微软发布3nm自研AI芯片Maia 200,算力超10PFLOPS,性能领先行业






芯东西1月27日报道,今日,微软宣布推出自研AI推理芯片Maia 200,称其为“目前所有超大规模数据中心中性能最高的自研芯片”,旨在大幅提升AI token生成的经济效益。
Maia 200采用台积电3nm工艺制造,晶体管数量超1400亿颗,配备原生FP8/FP4张量核心,内存子系统经过重新设计,包含216GB HBM3e(读写速度高达7TB/s)和272MB片上SRAM,还具备能保障海量模型快速高效运行的数据传输引擎。
这款芯片专为采用低精度计算的最新模型打造,在FP4精度下每块芯片性能超10PFLOPS,FP8精度下超5PFLOPS,且SoC TDP控制在750W范围内。
其FP4性能是亚马逊自研AI芯片AWS Trainium3的3倍多,FP8性能超过谷歌TPU v7。
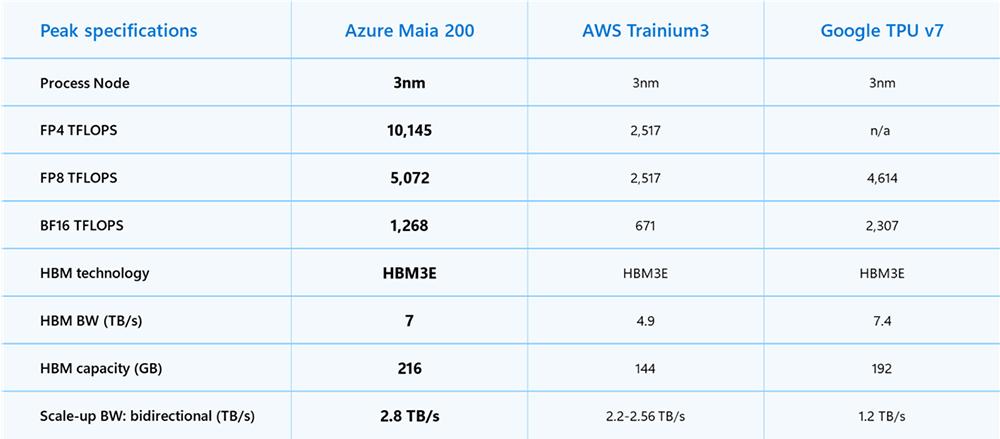
▲Azure Maia 200、AWS Trainium3、谷歌TPU v7的峰值规格对比
Maia 200的内存子系统以窄精度数据类型、专用DMA引擎、片上SRAM和高带宽数据传输专用片上网络(NoC)架构为核心,以此提升token吞吐量。
互连方面,Maia 200提供2.8TB/s双向专用扩展带宽,高于AWS Trainium3的2.56TB/s和谷歌TPU v7的1.2TB/s。
它也是微软目前部署的最高效推理系统,每美元性能比微软现有最新一代硬件提升30%。
01.
可运行当前最大模型,
将支持GPT-5.2
据微软博客文章,Maia 200能轻松运行当今最大的模型,还为未来更大模型预留了充足性能空间。
作为微软异构AI基础设施的一部分,Maia 200将支持多种模型,包括OpenAI最新的GPT-5.2模型,为Microsoft Foundry和Microsoft 365 Copilot带来更高性价比。

▲Maia 200芯片
Maia 200与微软Azure无缝集成。微软正在预览Maia软件开发工具包(SDK),其中包含一套完整工具,用于构建和优化Maia 200模型。
该SDK具备全套功能,包括PyTorch集成、Triton编译器、优化的内核库,以及对Maia底层编程语言的访问权限。这让开发者在需要时能进行细粒度控制,同时实现跨异构硬件加速器的轻松模型移植。
微软超级智能团队将利用Maia 200开展合成数据生成和强化学习,以改进下一代内部模型。
在合成数据管道用例中,Maia 200的独特设计有助于加快高质量、特定领域数据的生成和筛选速度,为下游训练提供更新、更具针对性的信号。
Maia 200已部署在微软位于爱荷华州得梅因附近的美国中部数据中心区域,接下来将部署到亚利桑那州凤凰城附近的美国西部3数据中心区域,未来还会部署更多区域。
02.
支持2.8TB/s双向带宽、
6144块芯片互连
系统层面,Maia 200引入了基于标准以太网的新型双层可扩展网络设计。定制传输层和紧密集成的网卡无需依赖专有架构,就能实现卓越性能、高可靠性和显著成本优势。
每块芯片提供2.8TB/s双向专用扩展带宽,还能在多达6144块芯片的集群上实现可预测的高性能集体操作。

▲Maia 200刀片服务器的俯视图
每个托架内,4块Maia芯片通过直接非交换链路完全连接,实现高带宽本地通信,以获取最佳推理效率。
机架内和机架间联网均采用相同通信协议——Maia AI传输协议,能以最小网络跳数实现跨节点、机架和加速器集群的无缝扩展。
这种统一架构简化了编程,提高了工作负载灵活性,减少了闲置容量,同时在云规模下保持一致的性能和成本效益。
该架构可为密集推理集群提供可扩展性能,同时降低Azure全球集群的功耗和总拥有成本。
03.
芯片部署时间缩短一半,
提升每美元和每瓦性能
Maia 200芯片首批封装件到货后数日内,AI模型就能在其上运行,从首批芯片到首个数据中心机架部署的时间可缩短至同类AI基础设施项目的一半以上。
这种从芯片到软件再到数据中心的端到端解决方案,直接转化为更高的资源利用率、更快的生产交付速度,以及云规模下持续提升的每美元和每瓦性能。

▲Maia 200机架和HXU冷却单元的视图
这得益于微软芯片开发计划的核心原则:在最终芯片上市前,尽可能多地验证端到端系统。
从架构早期阶段开始,一套精密的芯片前开发环境就指导着Maia 200的开发,它能高保真模拟大语言模型的计算和通信模式。
这种早期协同开发环境让微软能在首块芯片问世前,将芯片、网络和系统软件作为一个整体进行优化。
微软从设计之初就将Maia 200定位为数据中心内快速、无缝的可用性解决方案,并对包括后端网络和第二代闭环液冷热交换器单元在内的一些最复杂系统组件进行了早期验证。
与Azure控制平面的原生集成,可在芯片和机架级别提供安全、遥测、诊断和管理功能,最大限度提高生产关键型AI工作负载的可靠性和正常运行时间。
04.
结语:全球基础设施部署,
为未来AI系统筑基
大规模AI时代才刚开启,基础设施将决定其发展可能性。
随着微软在全球基础设施中部署Maia 200,微软已在为未来几代AI系统进行设计,期望每一代系统都能不断树立新标杆,为重要AI工作负载带来更出色的性能和效率。
微软诚邀开发者、AI创企和学术界人士使用全新Maia 200 SDK,开始探索早期模型和工作负载优化。
该SDK包含Triton编译器、PyTorch支持、NPL底层编程以及Maia模拟器和成本计算器,可在代码生命周期早期阶段优化效率。
本文来自微信公众号“芯东西”,作者:ZeR0,编辑:漠影,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com