
光芯片技术洞察:硅光如何破解AI能耗困局








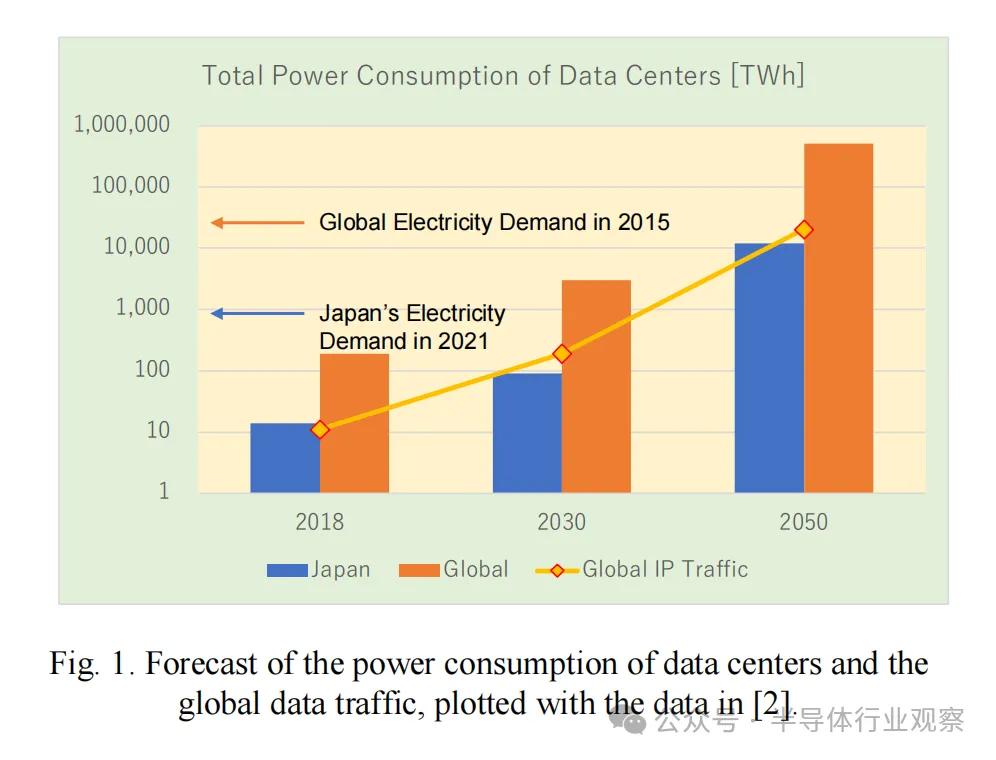
光子学技术在此展现出巨大潜力:光波的传播与干涉过程几乎不消耗能量,通过工程设计即可实现可扩展功能,且无需额外增加能耗。经过二十年发展,硅光子学已能提供近乎理想的技术平台,释放其独特优势——它可实现高效高密度互连,支撑高带宽长距离链路;能完成低能耗光路切换,且不受信号带宽限制;还可构建光子神经网络,以光速加速AI计算。
本文将回顾这些光子技术的发展趋势与进展,并论证:要让光子技术成为AI时代可持续基础设施的核心组成,硬件与软件、电子与光子技术需以互补方式协同发展。
光收发器与光交换机技术进展
A. 能耗扩展特性对比
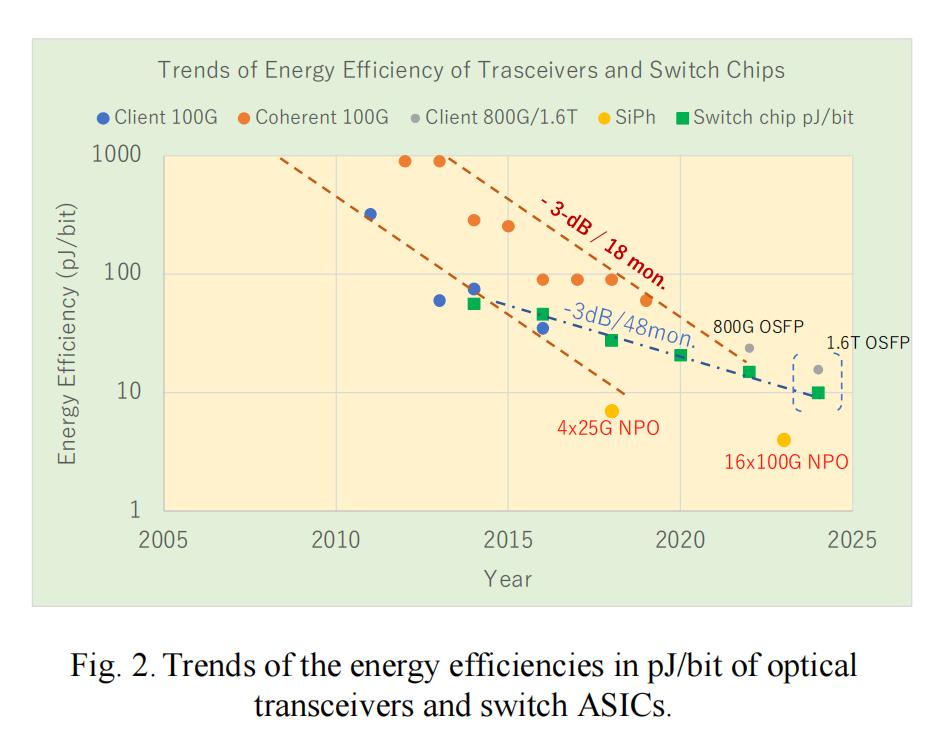
图2展示了光收发器与超大规模数据中心常用电交换机ASIC的能效(单位:pJ/bit)随时间的变化曲线。对比可见,交换机ASIC的能效扩展性远不及光收发器,这意味着系统瓶颈在于交换机而非收发器。令人意外的是,光收发器的能效提升已跟上摩尔定律节奏——基于硅光子的近封装/共封装光器件能效已突破5 pJ/bit,而交换机ASIC的能效提升则明显滞后。
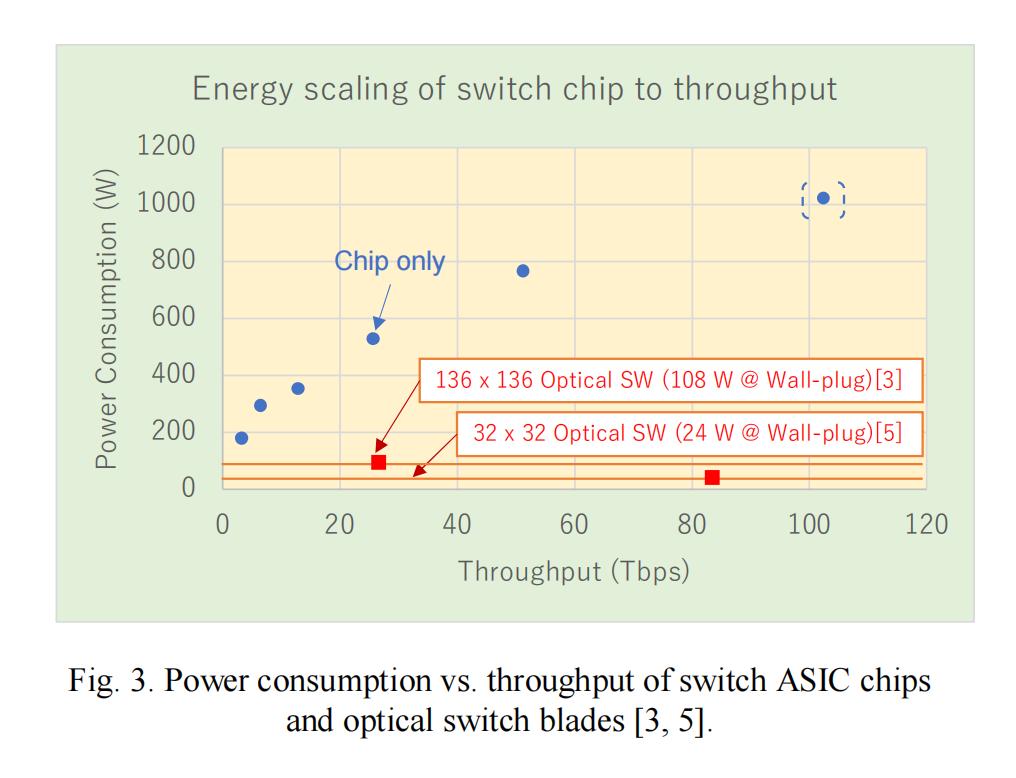
实际应用中,ASIC交换机功耗随吞吐量增长而上升,当吞吐量达到100Tbps时,单芯片功耗会超过1000W;而光交换机功耗极低,且随吞吐量增加保持稳定(见图3)。因此,用光交换机替代电交换机的比例越高,系统整体效率就越高。不过,这一替代过程需解决诸多实际问题。
B. 光交换机的系统应用实践
光交换机的核心局限在于无法处理数据包——这恰是ASIC交换机的核心功能。光交换机仅能作为“光路交换机(OCS)”运行,不能直接替代ASIC交换机。要控制OCS,需搭建独立控制平面,编排器或操作系统需实时感知OCS状态,并根据系统需求通过控制平面发送指令。这种系统与依赖ASIC的传统分组交换系统差异显著,因此使用OCS需从零开始重构整个系统,对架构进行全面优化。目前,全球仅谷歌具备这样的能力——在谷歌宣布其数据中心与AI基础设施已大规模部署OCS后,光交换机技术才开始广泛发展。
早在谷歌推出OCS系统前,日本产业技术综合研究所(AIST)已启动大规模硅光子交换机研发。图4展示了AIST开发的硅光子交换机刀片,它支持32×32严格无阻塞连接,配备数字控制接口,通过9级Clos网络配置可扩展至131072×131072连接规模。实验证明,在可组合解耦基础设施中,这类交换机可将网络功耗降低75%。

这些大规模硅光子交换机的制造,依托AIST基于标准CMOS技术的内部试验生产线,采用45纳米工艺规则,实现了足够高的均匀性与良率,可批量生产包含数千个器件(如马赫-曾德尔干涉仪MZI)的大规模光子集成电路。
光子神经网络技术探索
基于标准CMOS工艺的硅光子器件,具备高均匀性与高良率特性,这对实现光子神经网络(PNN)至关重要。PNN通过集成大量MZI形成网状拓扑,在光域直接执行矩阵-向量乘法(MVM)——MVM过程本身速度极快且无能耗,能显著提升AI计算能力,有望分担GPU等高能耗数字处理器的计算负载。不过,PNN缺乏理想的非线性激活函数,这是AI计算的关键功能之一。
为解决这一问题,研究人员提出利用电光(EO)非线性效应,让AI计算过程仅通过信号传播完成,无需中间数字处理环节。MZI器件可轻松实现这一目标:它以电信号为输入,输出调制后的光信号。电光非线性具有正弦传递函数,与ReLU、Sigmoid等传统激活函数差异较大,因此需为PNN开发全新AI模型。
A. 基于光电非线性的概率神经网络模型
目前已提出并验证了多个基于光电非线性的AI模型:第一个模型包含从输入参数空间到高维空间的非线性投影映射,通过调整MZI工作点训练其光电传递函数。转换后的光学复空间非线性映射数据,可通过寻找超平面实现分类,类似支持向量机原理。
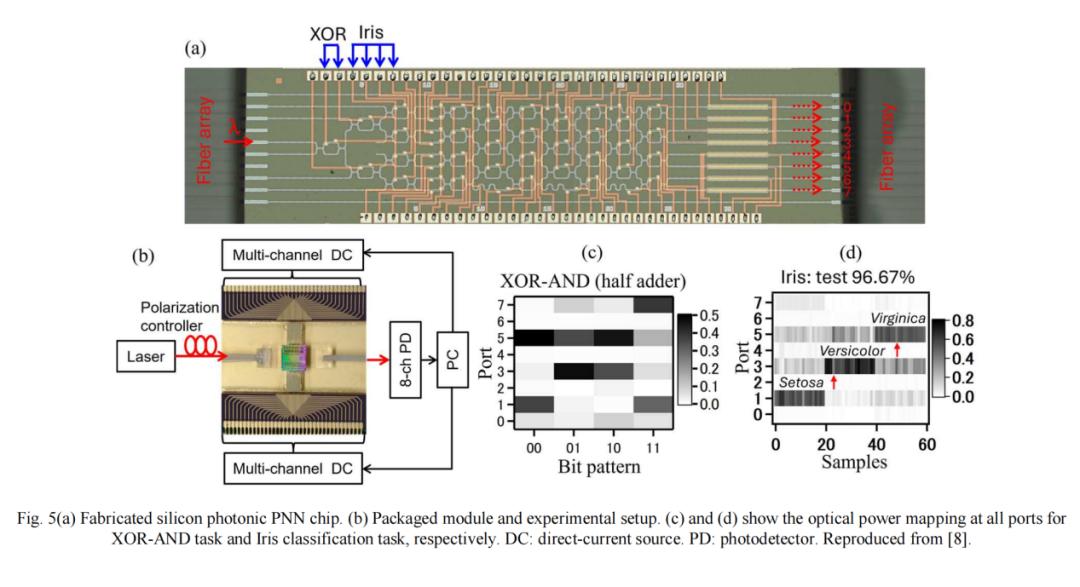
图5(a)与5(b)分别展示了研发的硅光子芯片与实验装置。研究人员在芯片上采用细菌觅食优化(BFO)与前向差分算法进行训练,图5(c)验证了其对多种布尔逻辑的分类有效性,图5(d)则展示了其对鸢尾花数据集的高精度分类能力。该PNN仅通过无源光子电路中的信号物理传播完成计算,确保了低功耗与低延迟特性。
第二个模型是上述模型的级联版本——“垂直分层光电概率神经网络”(如图6所示)。该模型中,所有光路长度不随层数增加而变长,为构建更深层次的学习模型提供了可能。
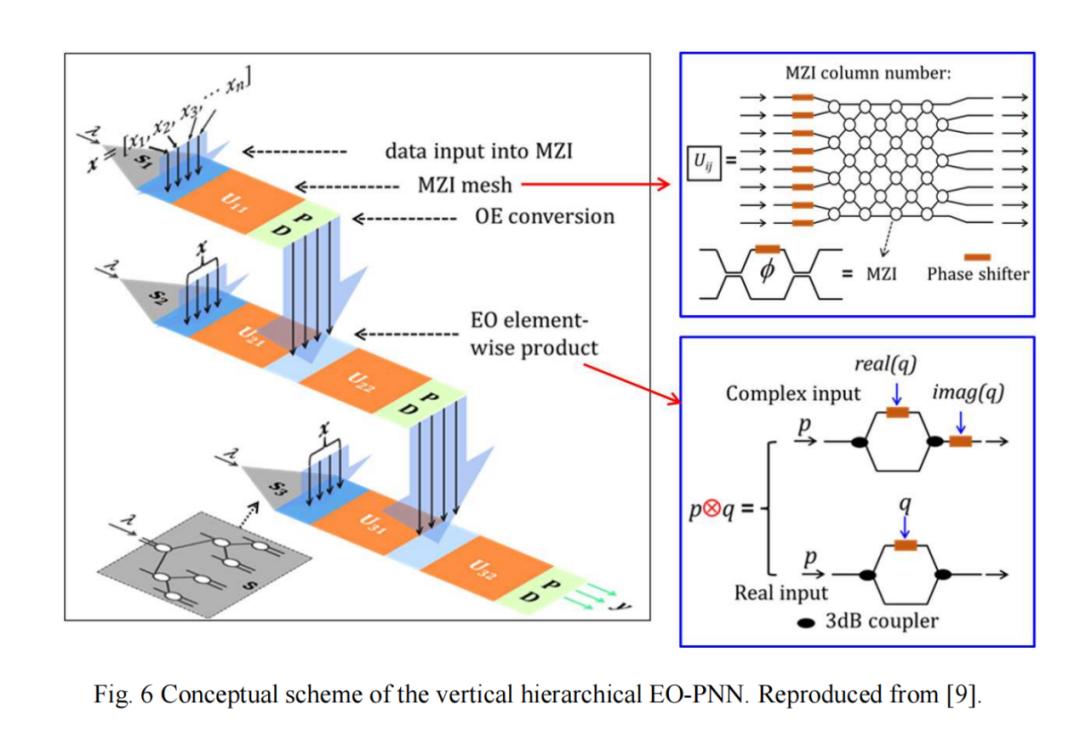
图7展示了该模型在MNIST、Fashion与KMNIST数据集上的测试准确率——三层模型准确率优于两层模型。第三个重要模型是光电霍普菲尔德网络。
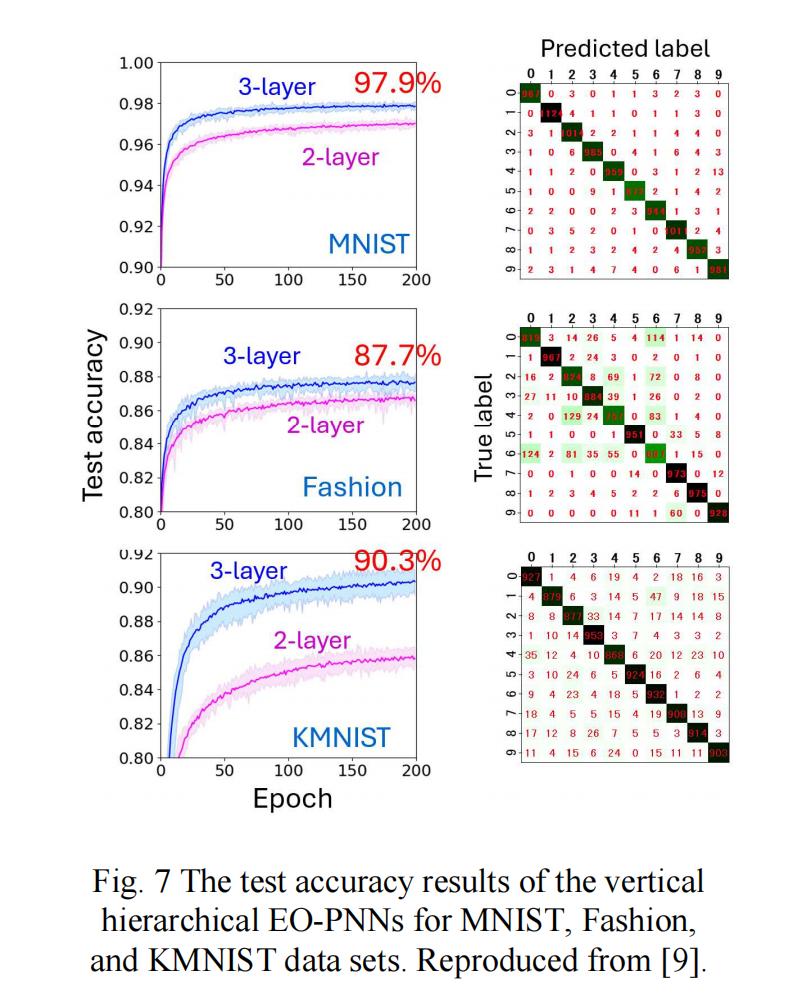
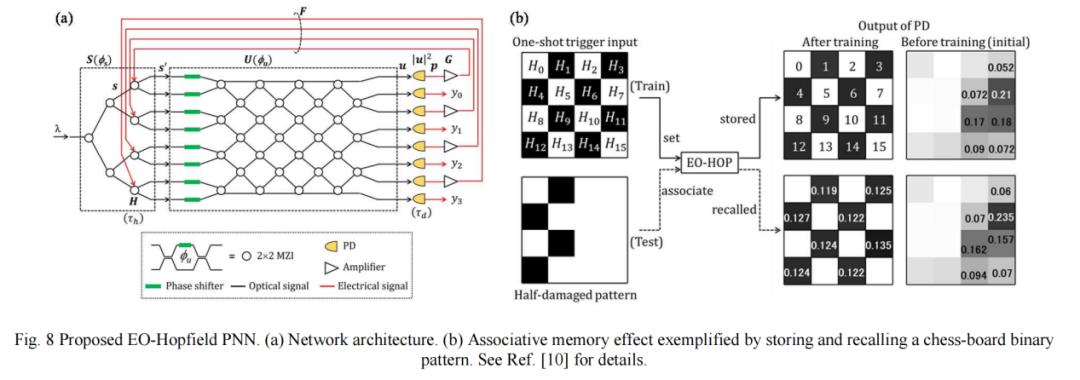
图8(a)为该网络架构:MZI作为非线性神经元,将输入数据与反馈信号编码到单频连续波(CW)光(记为λ)上。图8(b)显示,经过训练后,即使输入模式半损坏,系统仍能回忆起存储模式,体现了霍普菲尔德网络特有的联想记忆效应。
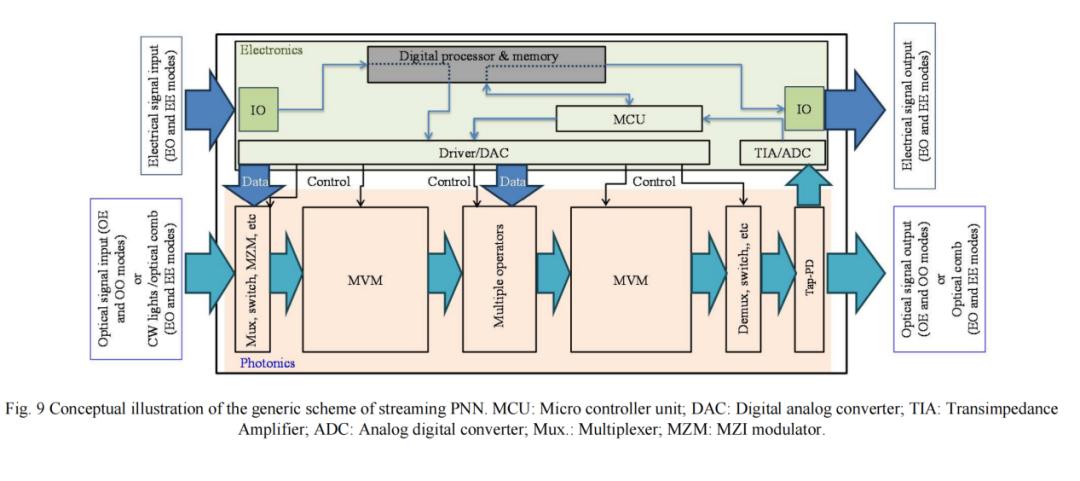
B. 流式PNN的通用方案
运行PNN存在不可忽视的开销,因此需对整个系统进行全面评估与整体优化。同时,PNN的固有优势——低延迟、高速度、低能耗等——需通过合理设计充分发挥。研究表明,PNN作为流式处理器,同时具备电域与光域I/O时性能最佳。流式PNN的概念如图9所示:通过该方案,PNN可同时在电域与光域流式处理数据,无缝融入现有数字基础设施。
技术总结与展望
硅光子技术已取得显著进展,在高密度I/O、带宽无关光路切换、光速AI加速等方面展现出巨大潜力,有望从多维度提升AI基础设施的可持续性。不过,将OCS、PNN等光子功能器件引入传统数字基础设施并非易事,未来需在整体系统设计与实现层面开展更深入研究。
本文来自微信公众号“半导体行业观察”(ID:icbank),作者:AIST,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com