
DeepSeek-OCR实现光学压缩 光计算助力大模型突破长上下文瓶颈










注意力机制是大语言模型成功的关键,但上下文窗口增大时,注意力矩阵的算力需求呈指数级增长。当窗口长度达1000K,仅存储该矩阵就需约2TB显存,导致大模型算力不足。
为解决此问题,DeepSeek提出上下文光学压缩方案,用视觉token压缩文本token。其DeepSeek-OCR论文验证了该方案的可行性,还启发业内探索让大模型“学会遗忘”。
光计算企业光本位科技认为,这一验证进一步表明光计算是大模型的未来方向,公司正积极推进光计算与大模型的融合。
01 以“视觉token”压缩文本token
DeepSeek-OCR论文的数据显示,该方法的视觉压缩能力出色:压缩率达10倍时,仍能保持96.5%的精度,证实了视觉压缩的可行性。
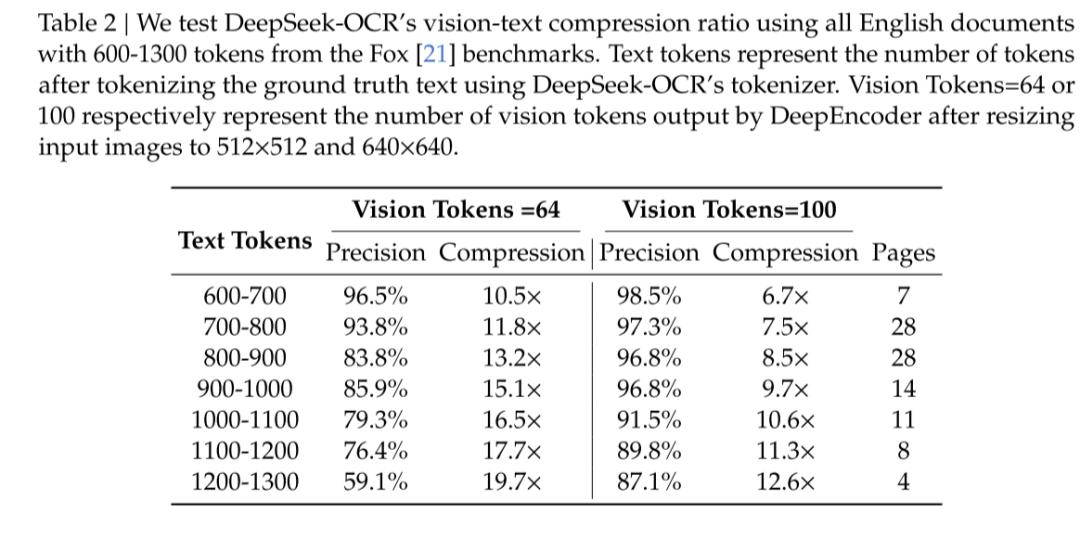
DeepSeek-OCR论文数据
DeepSeek提出的DeepEncoder模块是上下文光学压缩的核心,包含SAM、两层卷积块和CLIP三个子模块。
SAM模块先通过窗口注意力机制将原图分割为多个局部窗口,再用ViT图像识别模型计算各窗口的关联度。关联度高的区域会融合特征,空白区域因关联度低保持低特征值,在后续卷积模块中被丢弃,实现信息提取与压缩的双重效果。
最后,压缩后的视觉token输入CLIP,通过全局注意力机制捕捉图像的整体语义和上下文信息。
至此,DeepSeek-OCR完成压缩流程,可将原本需1000个文本token表示的数据压缩为100个视觉token。

DeepSeek-OCR压缩示意图
02 光计算为何适配上下文压缩
DeepSeek-OCR的光学压缩依赖ViT图像识别模型和CNN卷积运算两大结构,关键环节是ViT中的注意力机制与CNN中卷积核对信息的过滤。
本质上,这两种机制都是信息聚合的计算过程,需要高效的硬件载体支撑。
ViT和CNN的底层计算以向量矩阵乘法和卷积为主,天然适配光计算的并行架构。光计算芯片处理这类任务时,速度和能耗远优于电芯片,且灵活性更高——内部传播路径和计算逻辑可根据需求调整。
如下图所示,将计算迁移至光域后,DeepEncoder经光本位科技自主研发的128×128矩阵规模全域可编程存算一体光计算引擎加速,计算效率可提升100倍,能效比提升10倍。
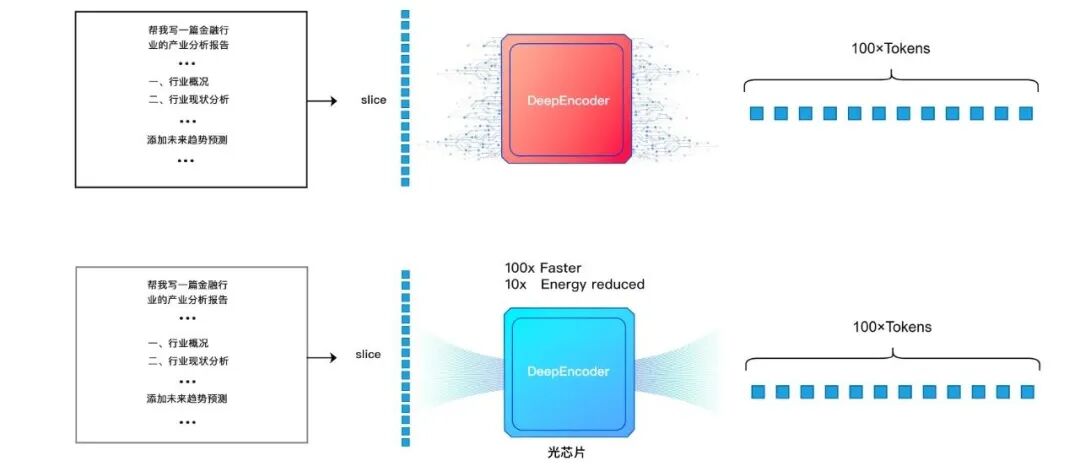
DeepSeek-OCR光计算加速示意图
光计算为何能实现高效加速和极致能效比?光本位科技测试发现,在上下文压缩这类类脑任务中,光计算相较GPU有压倒性优势。
最直观的优势是计算过程简化:电芯片需完成卷积、缩放、池化等多步计算,而光计算中图像信息可通过光学方式自然处理,上述过程在光传播中即可完成,无需额外功耗。此外,光本位的存算一体架构在处理批量任务时能保持“零静态维持功耗”。
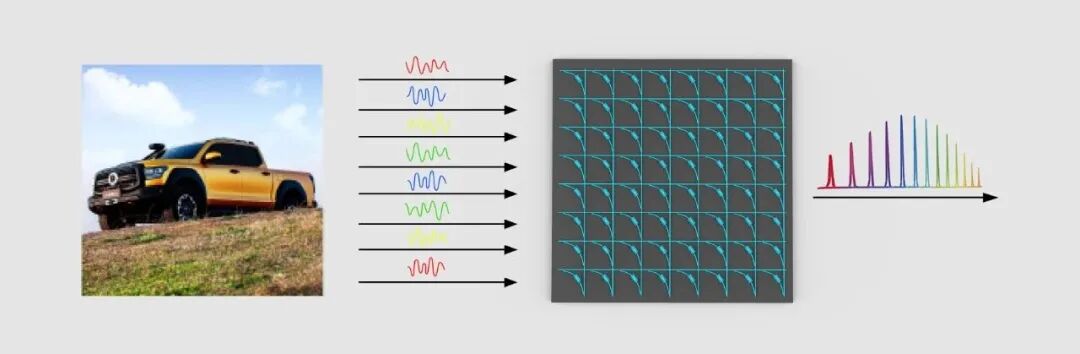
图像信息输入示意图
光计算芯片的另一大优势是可扩展性:扩大阵列规模提升并行度、提高参数刷新频率增强动态可编程性等都比电芯片更易实现,且能耗更低。这种维度扩展为长文本推理提供了超越传统电计算的空间。
除图像外,光本位科技还在尝试将其他形式的信息编码为不同频率的光信号,输入光计算芯片后,通过光路调制和耦合实现无额外能耗的计算。
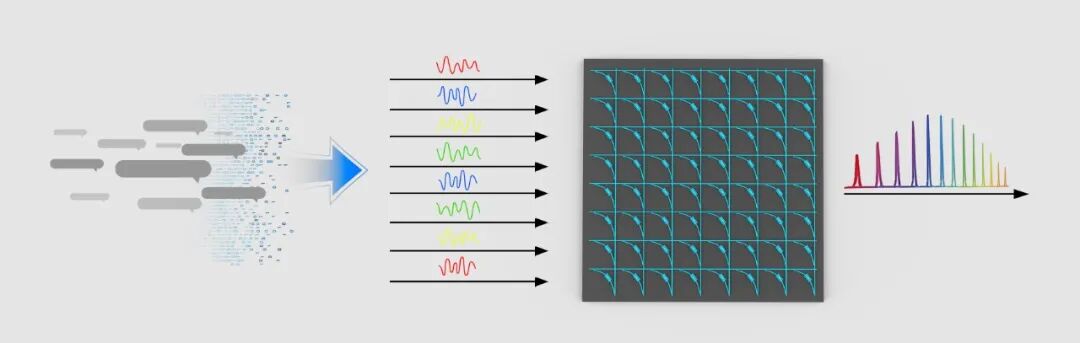
其他形式信息输入示意图
03 光计算硬件:大模型的未来基座
DeepSeek-OCR发布后,DeepSeek提出探索基于人脑遗忘机制的算法,核心是高效提取特征、降低维度甚至融合特征。光本位科技认为,这类算法的实现关键仍在于高效的特征处理。
为此,公司设想通过特殊光路结构或异质集成设计,结合相变材料(PCM)的非易失性,将存算一体架构与类脑神经元模拟结合,实现高效计算和类脑信息编码存储。
DeepSeek-OCR为光计算芯片的通用化设计提供了新思路,可能成为打通光计算硬件与大模型连接的突破点。
光本位科技计划未来推出上下文压缩专用硬件、AI任务专用硬件及配套软件栈,与大模型接轨。这不仅能在现有模型上提升近百倍算力和超十倍能效比,还能为新计算范式提供高效基座。
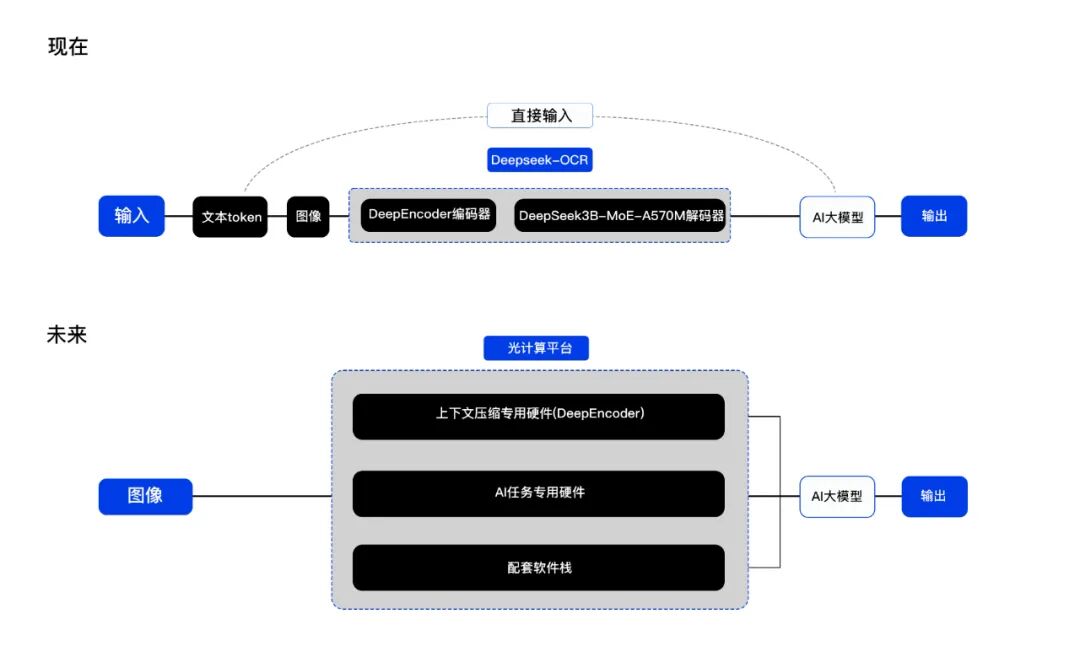
光本位光计算平台与DeepSeek-OCR融合前后示意图
当前,大模型的长文本推理对参数规模、带宽和上下文压缩能力提出新挑战。传统GPU受内存墙和功耗密度限制,扩展上下文时易受显存和带宽制约。光计算的大算力、高带宽、低功耗优势,有望改变这一现状。
光本位科技表示,未来将构建全光大规模AI计算的下一代颠覆式平台系统,提供全场景覆盖的全栈光计算解决方案。
本文来自微信公众号“光本位”,作者:光本位研究院,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com