
国产算力“集团军”进击,“芯”势力密集IPO






当下,全球资本市场呈现两大格局:中国“缺芯”、美国缺“电”。目前,英伟达的高端AI芯片仍对中国断供,特朗普甚至在11月初的采访中公开表示,不会让美国之外的任何国家获得英伟达最先进的AI芯片。
然而,国产算力的快速崛起正迅速打破这一局面。
中国本土芯片企业正纷纷冲向资本市场。IPO快速审核“绿灯”无疑释放了重要的政策支持信号。
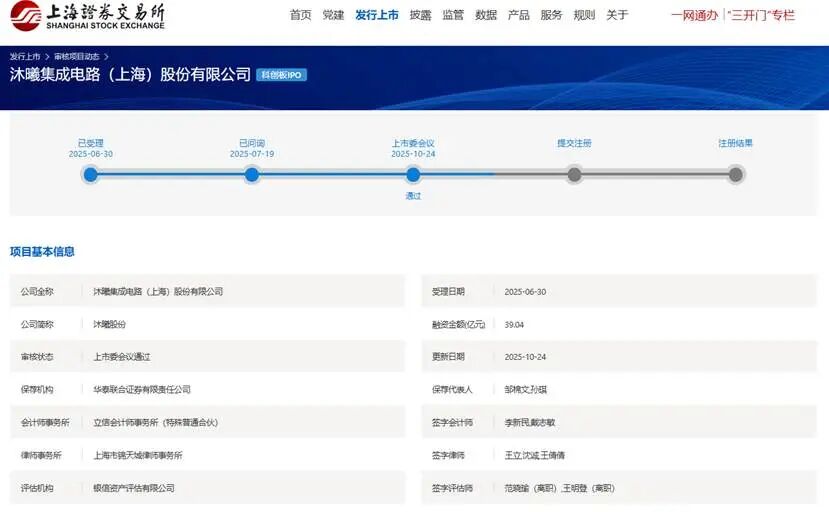
11月24日,“国产GPU第一股”摩尔线程将登陆科创板,发行价为114.28元/股,预计募资80亿元,从受理到上市仅用时不到5个月。
沐曦股份的上市申请于11月13日获证监会同意,有望年底前登陆科创板;燧原科技、航中天启分别于11月1日和4日提交上市辅导备案,开启科创板IPO进程;长鑫存储完成上市辅导、长江存储完成股改、新凯来已进入上市筹备关键阶段......
上市是企业扩大融资、推进产能技术发展的重要一步。外部封锁不断加剧,而内部力量却发起“集团式”冲锋,一系列密集的资本市场动作清晰地宣告着,全新的国产算力版图正加速形成。
在全球人工智能竞赛白热化的巨大压力下,国产“芯”势力正扛起中国AI产业赖以生存和发展的算力底座。
01 国产先进制程,矩阵成型
与过去寒武纪单点突破的“独行侠”模式不同,此轮国产芯片崛起呈现出显著的“集团军”作战态势,不再是单一环节的替代,而是试图构建涵盖底层IP、芯片设计、软件生态的全方位矩阵。
作为算力要求最高的通用处理器,GPU是这场竞赛的重点之一。中国GPU“四小龙”——摩尔线程、沐曦股份、壁仞科技和燧原科技已崭露头角。
摩尔线程自2020年成立就以自主研发全功能GPU为核心业务,成立仅四年就完成了三代全功能GPU的迭代。
其招股书显示,摩尔线程MTT S80显卡的单精度浮点算力性能接近英伟达RTX 3060;基于MTT S5000产品构建的千卡GPU智算集群效率超过同等规模国外同代系GPU集群计算效率,产品部分性能指标已接近或达到国际先进水平。
沐曦股份同样专注于自主研发全栈高性能GPU芯片。其招股书和二轮问询回复显示,旗下芯片C600、C700系列均采用国内先进工艺制程,核心技术自主可控。
其下一代旗舰产品曦云C700系列,性能直接对标国际顶尖的英伟达H100,预计2027年下半年大规模量产。若目标实现,意味着国产GPU在性能上具备与世界顶级产品竞争的潜力。
壁仞科技自成立之初就将“训/推一体、面向数据中心”作为主线,产品线覆盖AI模型训练与推理、图形渲染加速、高性能科学计算三大领域,一块芯片既能承担训练AI模型的“重活”,也能完成让AI模型应用推理的“巧活”。
它成功将至少四种来自不同厂家、不同型号的芯片整合在一起进行混合训练,这一突破性成果证明了壁仞科技软件平台的强兼容性,能适应数据中心各种新老芯片混用的复杂情况。
成立于2018年的燧原科技是国内最早专注于云端AI算力芯片的企业之一,核心竞争力是AI算力的全链路布局,未转向消费卡或图形业务,而是全力投入大模型训练。
其“邃思”系列芯片已迭代至第三代,最新一代的燧原S60自2024年下半年量产后,累计订单量超10万片,覆盖超300个应用场景,应用于中国头部的互联网公司、云服务商及金融机构的数据中心,证明了在特定AI应用场景下,国产芯片已具备相当竞争力。
除了芯片产品公司,一个成熟的产业还需要生态的构建者和赋能者。作为A股中的“AI芯片第一股”,寒武纪的“思元系列”芯片不断发展迭代,边缘推理场景的能效比甚至超过英伟达H20,精准契合互联网、金融等行业的落地需求。
同时,思元推训一体690芯片已进入最后测试阶段,性能对标英伟达H100的80%,若2026年如期量产,有望成为国内最强的算力载体。
相较于寒武纪,芯原股份更像是国产芯片产业中的“军火库”,拥有全球领先的芯片IP授权和一站式芯片设计能力。
根据IPnest的报告和企业公开数据,芯原的IP种类在全球前十的IP企业中排名前二,合作对象涵盖国内多家互联网大厂与造车新势力,以及亚马逊、谷歌、微软、英特尔等海外云巨头。
有了这样的“军火库”,国内众多AI芯片初创公司无需事事从零开始,可基于这些成熟模块迅速设计出满足自身特定需求的芯片产品,大大推动了国产芯片“百花齐放”的进程。
华为不再孤军奋战。近期华为宣布了多颗昇腾系列芯片和演进路线,从昇腾950PR开始,将采用华为自研HBM芯片,这标志着华为将在算力芯片领域构建坚实的自主可控基础。
根据瑞穗证券报告预测,华为昇腾AI芯片Ascend 910A/B/C在2025年将出货70万颗,其中昇腾910C的算力达H100的80%,而推理成本仅为H100的10%,成为英伟达A100/H100在国内市场的主要替代品之一。
这些企业不断的产品迭代与性能突破,证明国产先进制程芯片已走出实验室,进入商业化应用并实现批量生产。
芯片研发是一场“烧钱”的马拉松,从可用到好用,再到建立能与英伟达抗衡的生态,还有很长的路要走,每一步都需要大量资金投入。因此,通过IPO从公开市场获取持续发展的核心资本,成为国产“芯”势力的共同选择。
02 缺“芯”背后:AI大模型的全球博弈
当前,全球AI竞争本质上是算力的竞争,谁掌握更庞大的算力集群,谁就能更快训练出更强大的模型,在未来智能时代抢占先机。
国际市场调研机构Omdia报告显示,2024年英伟达Hopper系列芯片全球最大买家包括微软、Meta、亚马逊、xAI、谷歌等,各大科技巨头都在大规模囤积GPU,为AI竞赛储备“军火”。
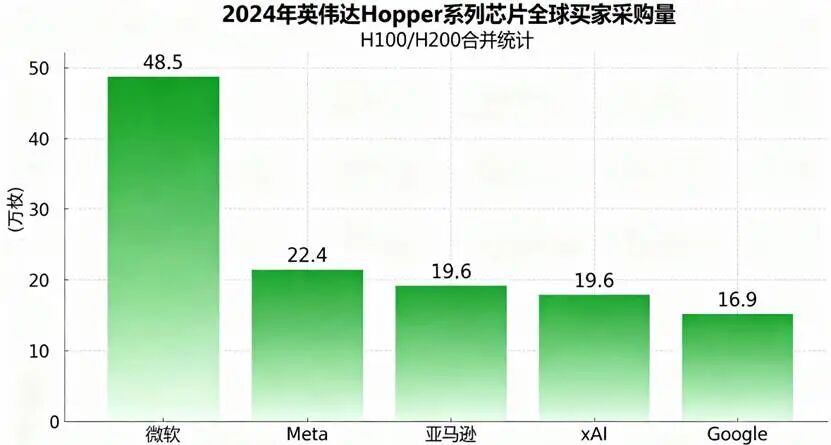
微软作为OpenAI的最大支持者,2025年第三季度资本支出飙升至近350亿美元,同比增长74%。
Meta在“元宇宙”战略收缩后,将重心转向AI,第三季度资本支出达193.7亿美元,是去年同期的两倍多。
谷歌与亚马逊两家云巨头同样疯狂“囤积”算力,谷歌母公司Alphabet第三季度资本支出约240亿美元;亚马逊宣布将2025财年资本支出预期从1180亿美元上调至1250亿美元,主要用于AI基础设施建设。
相比之下,尽管国内互联网与AI大厂也开启了“百模大战”,但在算力投入规模上与美国大厂差距明显。差距根源并非国内公司没钱,而是海外高端芯片“卡脖子”,导致企业即便有钱也难以建立强大的算力集群。
不过,英伟达创始人黄仁勋多次公开表示,美国对华芯片出口管制会倒逼中国加速发展。11月5日,他在参加英国《金融时报》举办的AI未来峰会时甚至称,以目前发展态势,“中国将赢得人工智能竞赛”。
03 “即使你卖,我也不要”
黄仁勋的观点指出,美国的封锁客观上为国产芯片创造了规模巨大、需求紧迫的确定性市场。“巧妇难为无米之炊”的困境,推动了中国反击策略的形成。
事实的确如此,英伟达的降级芯片H20在国内遇冷。
据媒体报道,中国要求所有获国家和政府资金支持的数据中心,不得使用任何国外AI芯片,包括英伟达、AMD、Intel等,更换的国产品牌有华为、寒武纪、壁仞科技、摩尔线程、砺算科技等。
从公开报道可知,多地已明确国投数据中心智算中心的国产化率。例如,上海要求2027年自主可控智算算力占比超70%,广东要求到2027年底新增国产化算力占比达70%,北京要求到2027年具备100%自主可控智算中心建设能力。
地方政府设定的时间表十分紧迫。
在商业层面,互联网大厂不能只考虑性能和商业效率,从供应链安全等角度出发,阿里、腾讯、字节等公司也在加速引入国产算力。
公开信息显示,腾讯云已全面适配主流国产芯片,阿里云通过一云多“芯”支持国产供应链,字节跳动也向寒武纪、海光信息等企业采购。
据央视报道,阿里巴巴控股的半导体设计部门平头哥开发出一款AU芯片,功能与英伟达的H20图形处理单元(GPU)相当。百度第三代的14nm昆仑芯P800在推理性能上超越了英伟达的A800,支持万卡集群部署。
任正非今年6月谈到中国与美国芯片差距时表示,中国单芯片落后美国一代,但可以用数学补物理、非摩尔补摩尔,用群计算补单芯片,结果能达到实用状况。
通俗来讲,中国计算集群需增加用量来弥补单一芯片的性能短板,这意味着要消耗更多电力能源。从政策上看,新建的数据中心可获得电力补贴。
一系列政策指引和激励措施正发挥作用,鼓励中国科技公司打破对英伟达的技术依赖,中国算力的自主可控正在快速追赶。
美国前商务部长雷蒙多近期在公开论坛上称:“美国前两届政府以为可以阻挡,但华为比任何时候都更强大地制造出令人难以置信的芯片”。
根据“十五五”规划方向,科技自立自强成为战略必选项,先进制程芯片所代表的集成电路产业是发展重点之一。
国产芯片企业近期冲刺科创板的景象,正是这一国家战略在资本市场的具体体现。从“单点”到“集团军”,再到相互赋能、共同演进的“生态圈”,这场宏大的算力“新基建”之路充满挑战,但国产“芯”势力的集体突围,已让希望清晰可见。
免责声明:本文(报告)基于已公开的资料信息或受访人提供的信息撰写,但本公众号及文章作者不保证该等信息资料的完整性、准确性。在任何情况下,本文(报告)中的信息或所表述的意见均不构成对任何人的投资建议。
本文来自微信公众号“明晰野望”,作者:洛苏,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com