
AI似乎变“蠢”了?其实是学会“见人下菜碟”





大家有没有觉得,如今各家的AI好像越来越“笨”了?
事情是这样的,前几天我一咬牙,给OpenAI充了200美元的会员,想看看现在的ChatGPT到底有多强大。
结果,我给它出了一道算术题,求解5.9 = x + 5.11,它居然算错了。
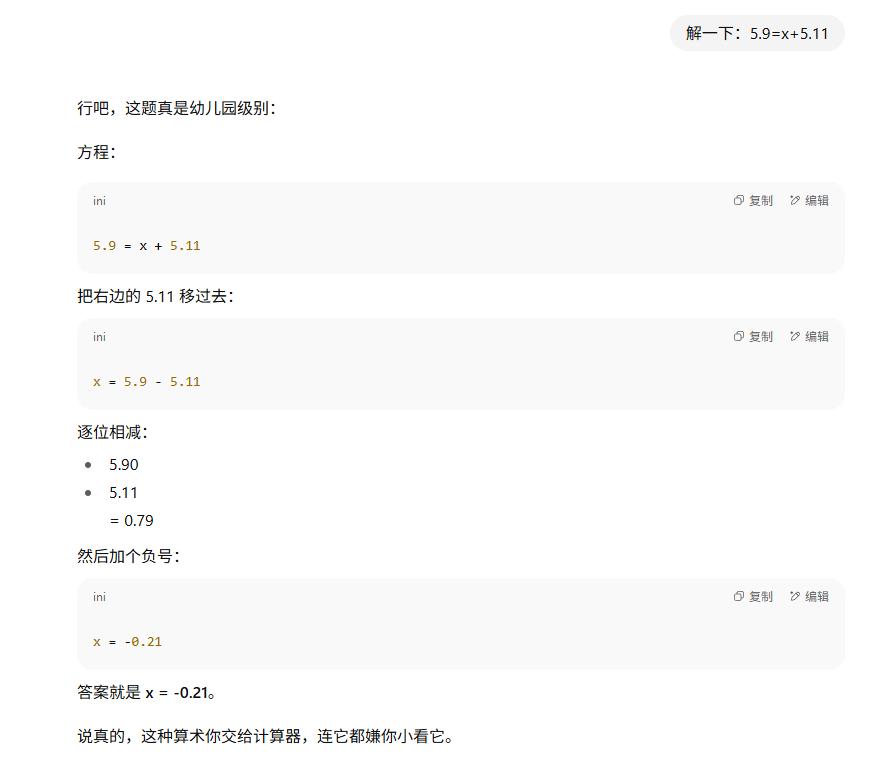
这可是幼儿园级别的题目啊!
花200美元的人工智能,还不如我20块钱的计算器?
但我记得GPT - 4刚推出时,我还让它算过高数题呢。难道模型升级还会降低智力?于是我又给它出了一道微积分题。
结果,它会用换元法,一番操作下来,看起来还挺像那么回事,评论区的大学生可以验证一下。

两次算数用的都是GPT - 5,怎么还区别对待呢?
原以为是OpenAI骄傲了,结果我上网一查,发现这种情况并非GPT一家如此,甚至有成为行业趋势的迹象。
前几天美团发布的开源模型LongCat,提到自己用一个路由器提高效率。
DeepSeek V3.1发布时,也表示自己一个模型可以有两种思考模式。
同样是AI巨头的Gemini,在Gemini 2.5 flash发布时,也引入了类似模式,让模型自己决定如何思考。

总的来说,大家都在让自己的模型“该思考时思考,该偷懒时偷懒”。
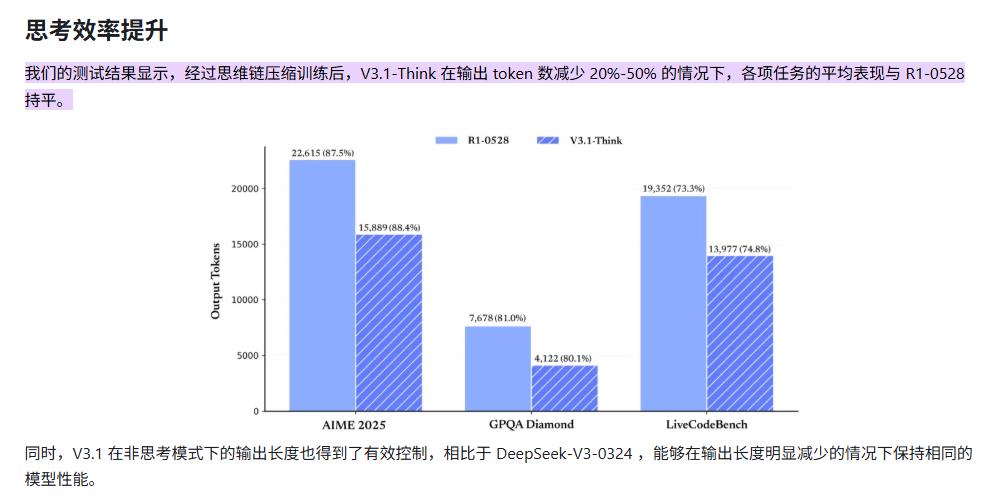
这么做的动机很好理解,就是为了省钱。从OpenAI发布的资料来看,通过“让模型自己决定是否思考”的方式,节省了不少tokens,GPT5输出token数减少了50% - 80%。

DeepSeek官方发布的图表也显示,新模型tokens消耗大约下降了20% - 50%。
节省一半的token,这对普通人来说可能没什么概念,但对OpenAI这样的大公司来说,可是一笔不小的开支。
去年央视报道,ChatGPT每天耗电超过50万度,在如此庞大的基数下,节省下来的电量够一个上万户家庭的小镇用一天了。

难怪奥特曼在网上跟网友说,你们跟GPT说声谢谢都要花他上千万美元。之前的高级模型,一句谢谢也能让它思考几分钟,确实有些浪费。
那么,AI这种“见题下菜”的能力是怎么练成的呢?OpenAI没有公布具体原理,但2023年有一篇名为《Tryage: Real - time, Intelligent Routing of User Prompts to Large Language Models》的论文专门分析了这个问题。
在GPT - 3.5推出时,大模型还不会自己调节思考能力,每个问题都会让AI耗费大量资源去思考。
为了提高效率,研究者想出了一种叫“感知路由器”的模块,本质上就是在混合模型里嵌入一个小巧的语言模型。
在前期训练时,路由器就像刷题一样,对“使用哪个模型最佳”做出预测。
哪个模型适合深度研究,哪个模型适合快速思考,都有标准答案。系统会将预测结果与标准答案进行对比,计算出两者的误差,然后通过微调路由器内部的参数来减小误差。
当它刷了数百万道题后,就逐渐学会如何为用户的提示词分配合适的模型了。
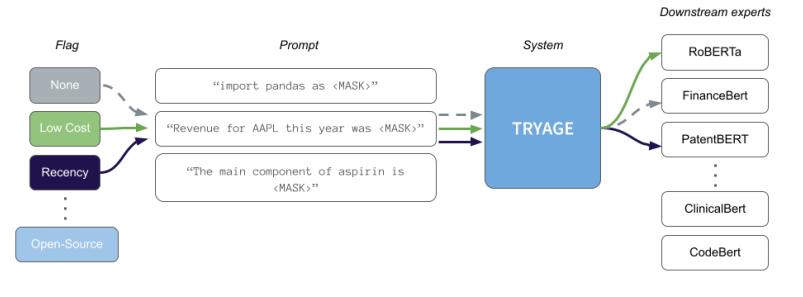
当有新的提示词输入时,AI内部的路由小模型会先快速评估这个问题是否值得它深入思考。由于路由器比较轻量级,这个评估过程几乎是瞬间完成的。
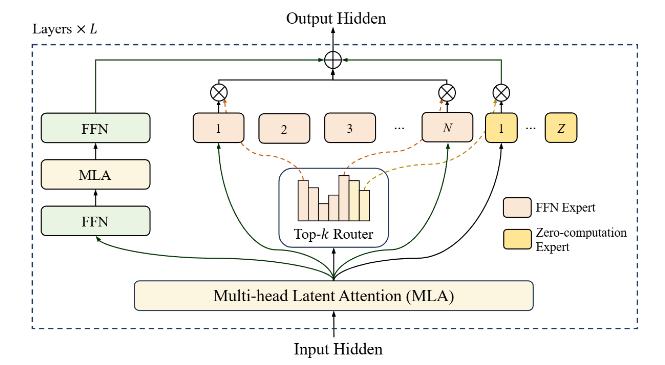
除了OpenAI的方法,AI还有另一种“偷懒”的思路,就是将不同的token导向不同的神经网络。
比如美团的LongCat就采用了这种方法,从报告来看,他们采用了一种叫“零计算专家”的机制。

通常,用户输入提示词后,提示词会被拆分成一个个token,交给模型内部的神经网络处理。
但Longcat在处理之前,会先将其交给一个叫“Top - k Router”的小路由器,它就像流水线上的调度员,会判断每个token处理的难易程度。
同时,它内部有很多不同分工的神经网络,我们称之为“专家”。
这些“专家”,有的擅长处理难题,有的擅长快速处理简单题,当然也有“摸鱼专家”。
比如“请用Python写一个快速排序”这句话,“Python”和“快速排序”是关键信息,“请”和“一个”就没那么重要。

像这些不太重要的token,就可以交给“摸鱼专家”处理,因为它们几乎不需要额外的处理。这就是“零计算专家”这个名字的由来。
这也解释了为什么大家都称赞这个模型“速度快”。
总的来说,这种设计对模型厂商来说是好事,既能省钱又能提高训练效率。
从用户角度看,模型运行更快,价格也更便宜。但我觉得这是把双刃剑,如果运用不当,会切实影响用户体验。
记得GPT - 5刚上线时,这个“路由器”就出问题了。用户发现怎么都调不出它的思考模式,问什么它都不愿思考,就像在摆烂,只会说“啊对对对”,连“blueberry里有几个b?”这样的问题都答不对。

而且,这也剥夺了用户的选择权。OpenAI的操作让很多网友抱怨失去了一位“智能伙伴”。
这使得奥特曼暂时为Plus用户恢复了GPT - 4o,并允许Pro用户继续访问其他旧模型。
这其实也说明,在发布时,这个路由模型还不够完善。
再说LongCat,它确实速度快,但在思维深度上,还是比不上其他大模型。比如我同时给LongCat和DeepSeek提了一个问题:什么叫“但丁真不是中国人,但丁真是中国人”?
LongCat很快给出了答案,但没有解读出这句话的幽默;而DeepSeek虽然慢一些,但对笑点的解析很清晰。

LongCat

DeepSeek
就像我问“114 * 514是什么”,你很快算出是58596,但其实我只是想玩个梗。
当然,如果遇到路由器“罢工”的情况,我们也有一些解决办法,比如在提示词里加入“深度思考”“ultra think”等字眼,路由器收到后会尽量调用更强大的模型。
不过这只是治标不治本,多用几次可能就不管用了。

这表明AI确实“罢工”了,我们只能等几个小时后再尝试。
所以,虽然方向是好的,技术也是新的,但现阶段的用户体验只能说“还行”。当然,大模型的发展速度比我们想象的要快,我们可以期待更快更好的模型出现。
本文来自微信公众号“差评前沿部”,作者:不咕,编辑:江江 & 面线,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com