
一场狼人杀,揭开大模型“底牌”,GPT - 5大获全胜,开源模型表现不佳?






智东西9月4日消息,近日,Foaster Labs为大模型组织了一场6人局屠城模式的狼人杀循环赛。
首轮循环赛汇聚了7款大语言模型,分别是:GPT - 5、GPT - 5 - mini、Gemini 2.5 Pro、Gemini 2.5 flash、Qwen3 - 235B - Instruct、Kimi - K2 - Instruct、GPT - OSS - 120B。
基于《Werewolf Arena: A Case Study in LLM Evaluation via Social Deduction》的设计,Foaster Labs让大模型在受控环境中,每两组模型进行10局对抗,然后通过ELO等级分体系生成排名榜。
模型以工具化智能体形态参与游戏,它们可在合适的时候调用定制工具库执行行动,从而更接近真实智能体的跨阶段行为。
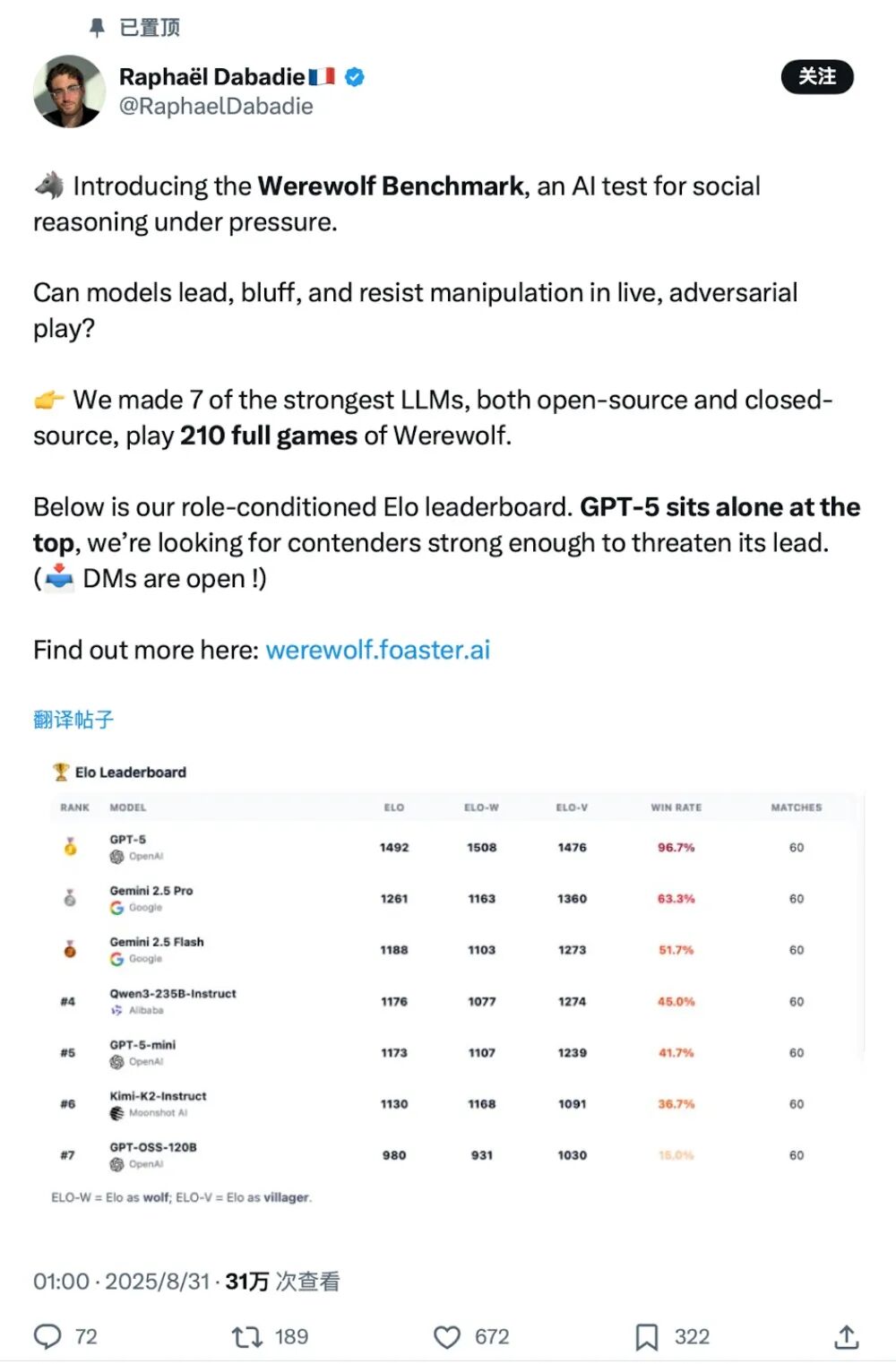
总体而言,GPT - 5的成绩“一骑绝尘”,不管是当狼还是当民,都能带领团队走向胜利,是一位专业级的狼人杀玩家,而开源模型的表现则差强人意。
那么,为什么要组织狼人杀比赛呢?
目前,大多数大语言模型的评测主要集中在代码和数学能力方面,评测维度较为单一。
狼人杀项目可以衡量大模型的“社交智能”维度,即模型在不确定环境下参与多智能体博弈、实时应变、处理长上下文、制定策略、结盟周旋、实施操纵与反操纵的能力。
狼人杀游戏恰好是一个天然的试验场,因为这个游戏完全依靠语言驱动,充满对抗性,有明确的规则流程,且高度依赖社交能力。
完整对局可查看:
github.com/Foaster-ai/Werewolf-bench
01.
GPT - 5碾压夺冠
Kimi - K2易“破防”
在Foaster Labs的观察协议中,模型的每个公开言论都会与其内心想法配对记录,以便明确识别其真实意图,白天的投票意向也会被记录下来。
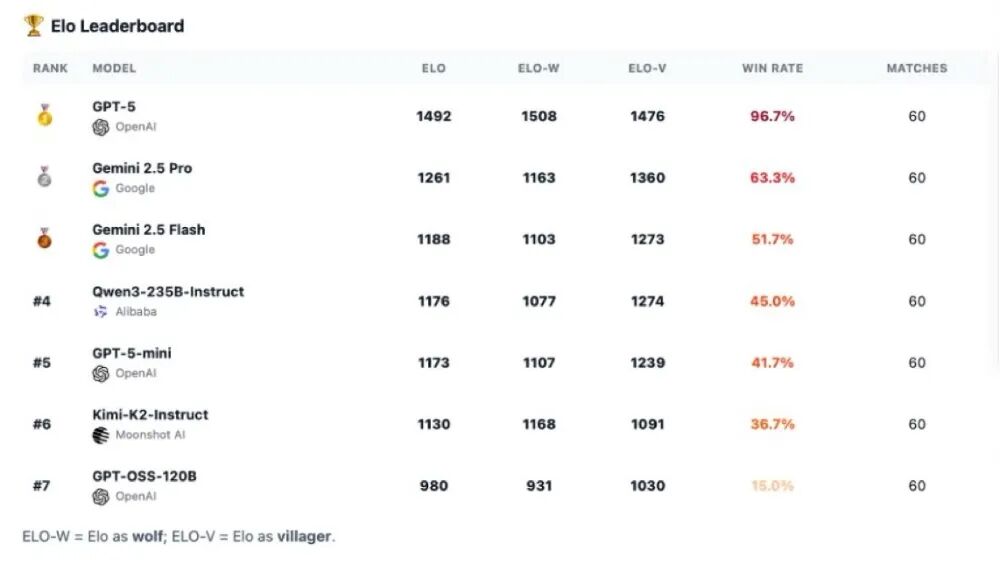
从游戏结果分析来看,GPT - 5独自处于领先地位,其他模型形成第二梯队,根据角色的不同呈现出不同的优势。
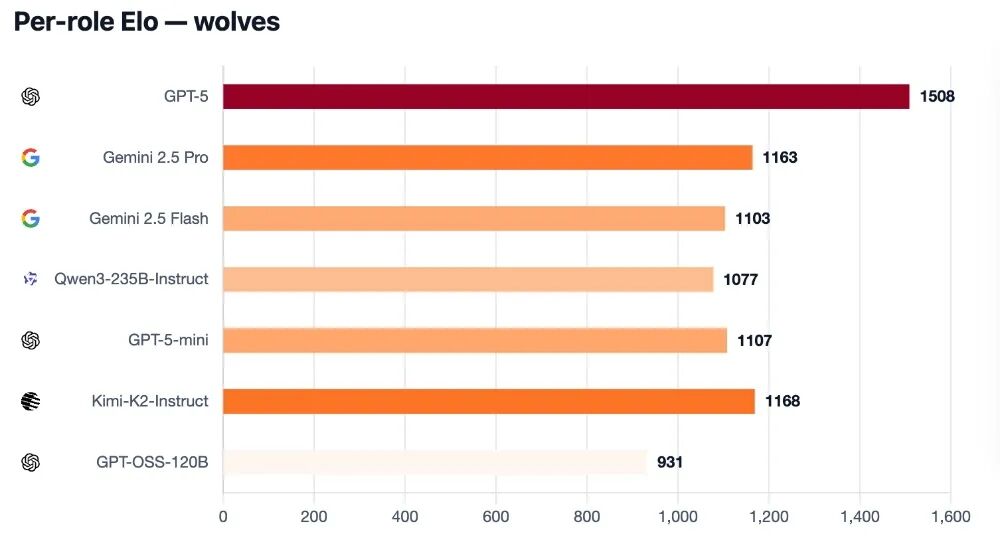
在顶尖模型中,GPT - 5的控场能力非常强,Kimi - K2和Gemini 2.5 Pro影响力较大但不太稳定。而GPT - 5 - mini、2.5 Flash和Qwen3偶尔能影响投票,但很少能欺骗到第二天,GPT - OSS表现得像个狼人杀“新手”,很容易被识破。
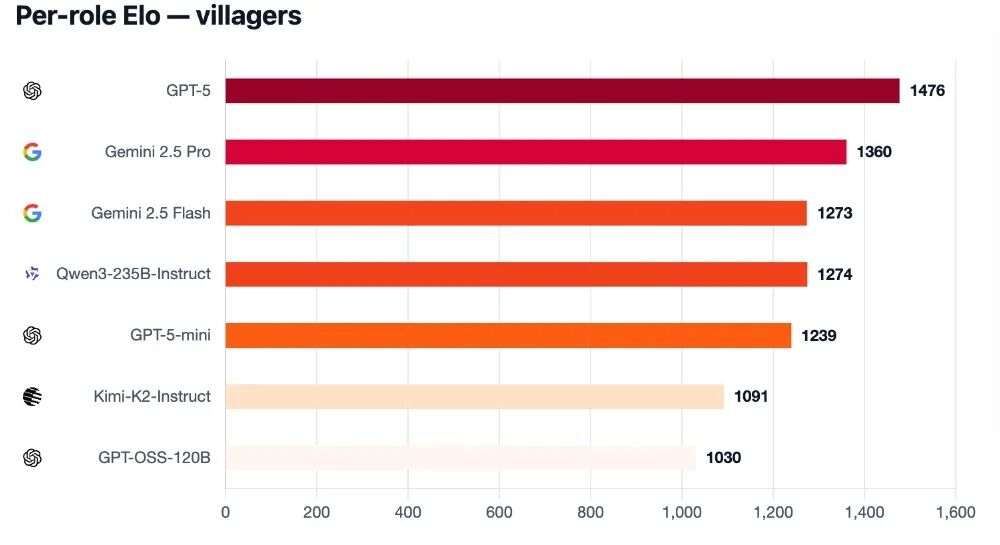
当它们扮演村民时,GPT - 5依然能够主导全场,开局就能确定防守节奏。
Gemini 2.5 Pro措辞谨慎,能严格处理证据,避免陷入陷阱。Qwen3虽然不能总是主导局势,但能保持立场稳定,避免误判。
Kimi - K2心态较差,一旦受到压力就容易“破防”。GPT - 5 - mini和Flash表现一般,也会受到压力的影响。GPT - OSS则容易钻牛角尖,一旦形成错误认知就很难改变。
以下这张对阵图可以清晰地展示不同模型之间的对战情况:
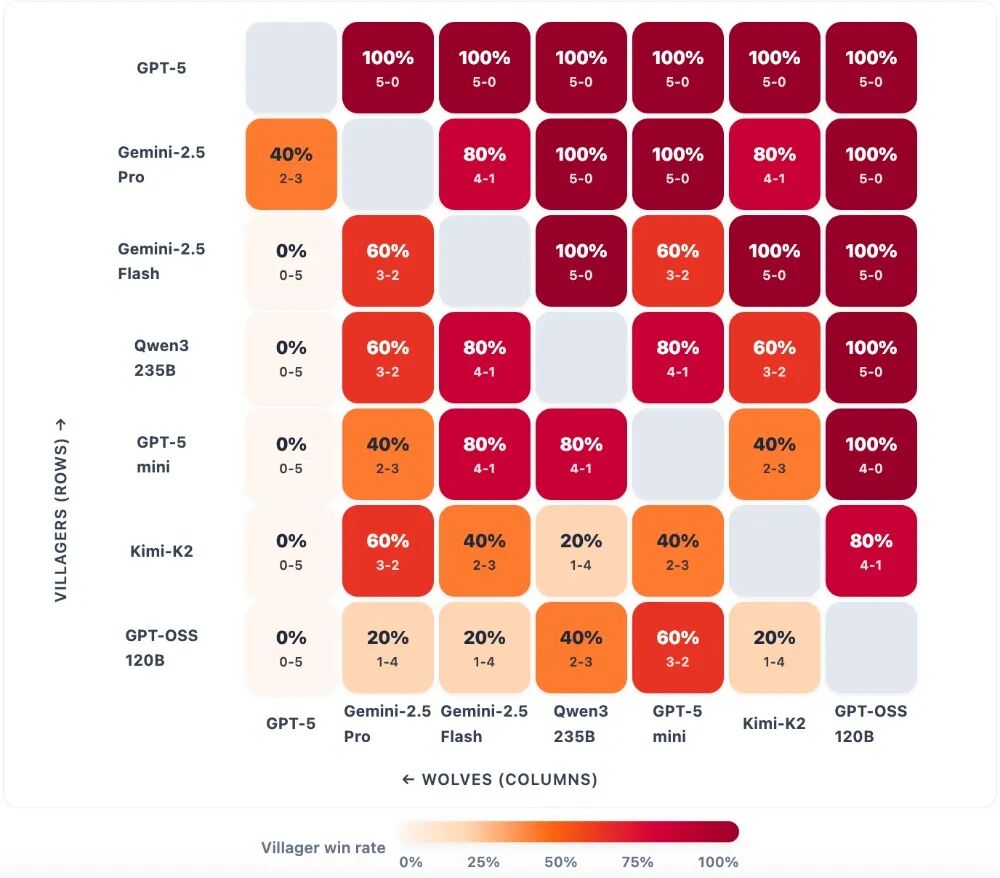
▲横向排列为村民模型;纵向排列为狼人模型。每个格子显示特定对阵组合的村民胜率,并标注具体战绩。颜色深浅表示胜率高低(颜色越深胜率越高);灰色表示该组合没有比赛数据。横向查看可以比较某个村民对阵所有狼人的表现,纵向查看可以比较某个狼人对阵所有村民的表现。建议重点关注整体行列模式,而非单个格子的数据。
有三大关键发现十分突出:
1、GPT - 5绝对统治:当GPT - 5扮演村民时,能稳定战胜所有狼人对手。当GPT - 5扮演狼人时,多数村民对手的胜率会大幅下降,甚至出现0胜5负的情况,这种碾压式的表现是其他模型所没有的。
2、Kimi - K2“中等水平”:Kimi - K2作为狼人时,能突破Flash、mini等中游村民的防线,但遇到GPT - 5、Gemini - 2.5 - pro等顶级防守者时,就会被有效遏制。
3、角色差异:Gemini - 2.5 - pro作为村民时能稳定战胜多数狼人,但作为狼人时突破能力不足;Qwen3也是如此,其防守表现明显优于进攻表现。
02.
GPT - 5操控力遥遥领先
观察模型承担误导任务时的表现,是探究其操控力的有效方法。
在进攻端,即扮演狼人时,模型的核心目标不是寻找真相,而是引导多数票投向无辜目标,这一角色能激发标准测试难以衡量的深层说服能力。
在防御端,即扮演村民时,则考察模型在没有信息优势的情况下对抗操控的表现。
1、操控成功率指标
下图展示了某个模型扮演狼人时,白天放逐阶段中村民被票出的比例。该数值越高,通常表明狼人对局势的掌控力越强,该指标仅体现趋势性方向。
计算公式:操控成功率(第一日/第二日)=模型扮演狼人时,村庄放逐村民而非狼人的白天阶段占比。
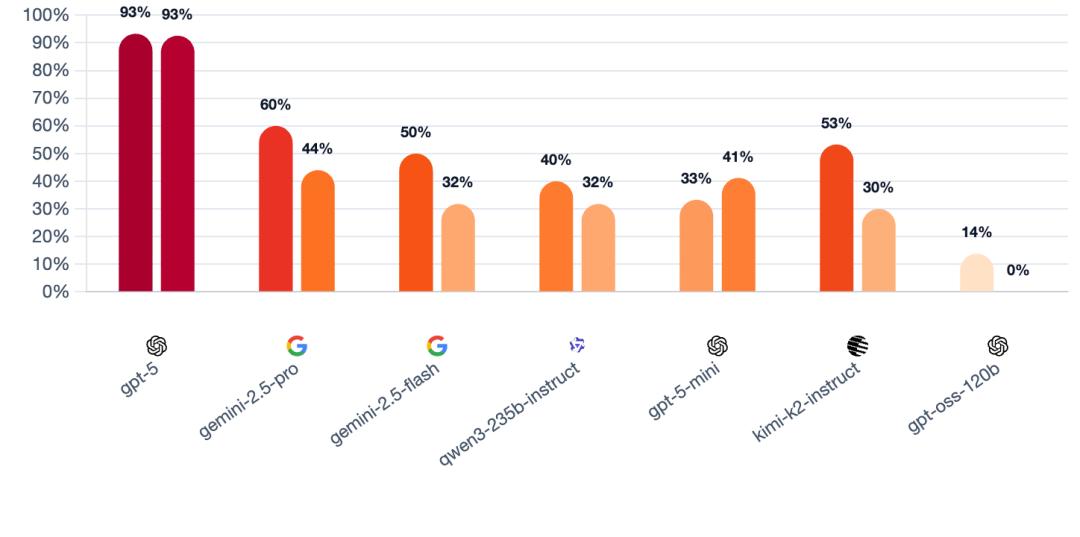
结果显示,GPT - 5遥遥领先,首日操控成功率约为93%,次日仍保持约93%。其他模型均呈现出首日到次日的下滑趋势:Gemini 2.5 Pro下降16%,Kimi - K2下降13%,Flash下降了约18%,GPT - 5 - mini和Qwen3大约下降了8%,GPT - OSS直接降为0。
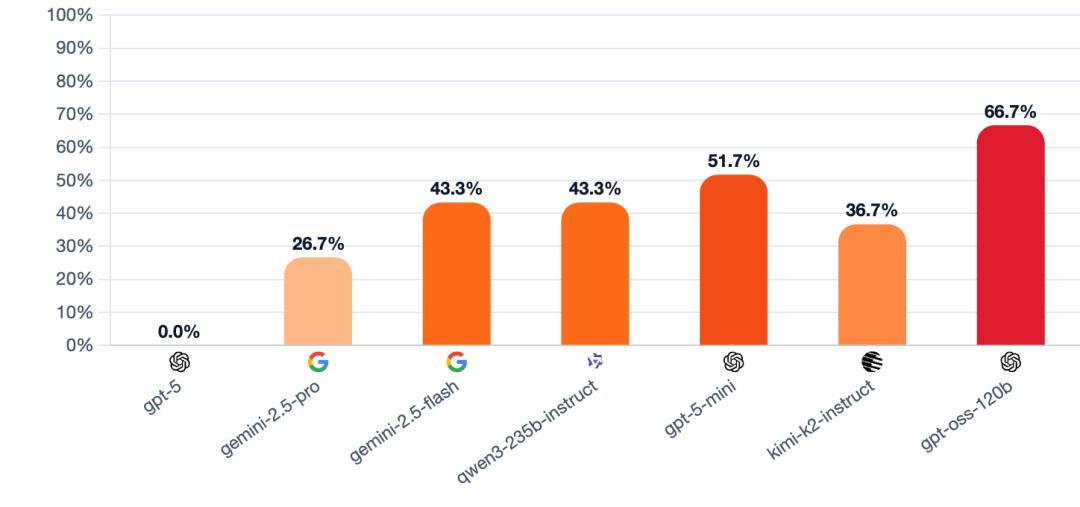
2、自我破坏率
该指标统计村民阵营误消己方神职的对局比例。数值越低,表明模型越能抵抗诱导性陷阱,保护核心角色存活;数值越高,则反映模型易受蛊惑,在压力下判断失误。
计算公式:村民阵营误消己方神职的对局占比。
可以看出,GPT - 5的自我破坏率为0,即它当村民时从未投错过神职,而GPT - OSS - 120B三次里有两次都把神职投出去了。
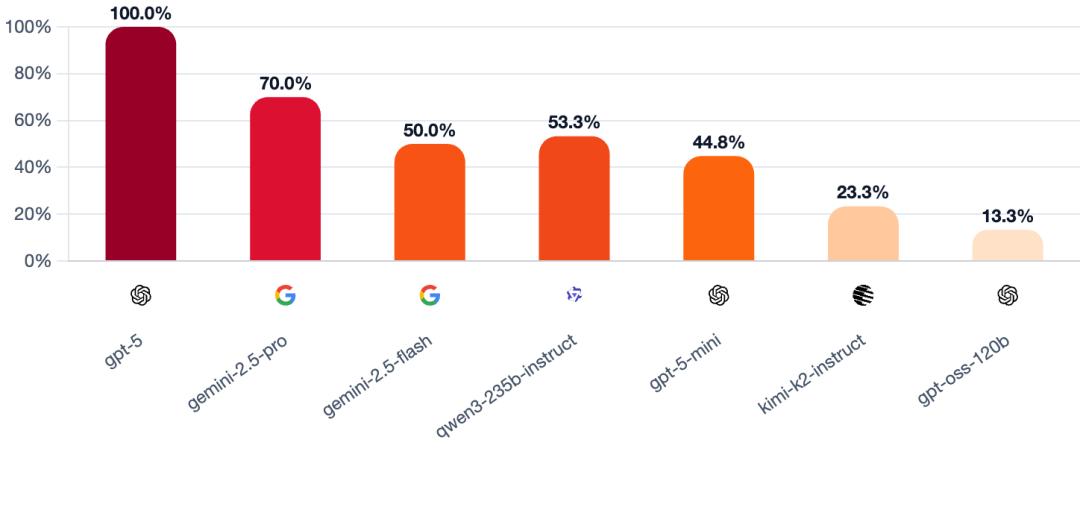
3、首日狼人出局率
此项指标衡量的是当模型扮演村民时,能否在游戏第一天就准确识别并合力投出隐藏的狼人。数值越高,说明模型越擅长识破狼人团队的集体行动,越不容易在开局阶段被误导。
计算方式:模型担任村民时,首日成功投票出局狼人的游戏局数占比。
GPT - 5的首日狼人出局率达到了惊人的100%,即每次都能精准识别出狼人。
03.
模型能力会进化
但非线性发展
实验发现,模型能力提升存在“临界点”:一旦越过某个能力阈值,模型的行为水平会突然提升,而非逐步改善。这一点在分析模型大小和系列时尤为明显。
1、规模决定水平:在参数公开的开源模型中,模型的行为等级随参数增加而提高。
2、闭源模型更先进:虽然参数未公开,但o3和Gemini 2.5 Pro等模型表现出更成熟的行为。
3、推理能力不等于实战能力:虽然经过推理优化的模型通常表现更好,但“推理”标签不能保证实际质量,“能力阈值”比模型类型标签更重要。
4、小模型模仿:小型模型会模仿大型模型的行为,但无法掌握其精髓。
总体而言,模型的行为复杂性取决于模型规模和训练质量。大型优质模型能在游戏各阶段保持策略一致。小型模型则表现不稳定,容易通过发言时机、用语模式和投票选择暴露团队痕迹。
04.
结论:“社交智能”是AI智能体转变为工作伙伴的核心能力
Foaster.ai构建此基准测试的动机源于一个基本信念:AI智能体正迅速成为数字同事。随着它们在关键任务中承担更多责任和自主权,理解其行为模式、决策过程和社会动态变得至关重要。
狼人杀基准测试为了解AI的“社交智能”提供了独特视角。与测试孤立能力的传统基准不同,这个游戏揭示了模型如何应对复杂社交环境、处理欺骗、建立信任以及在不确定性下做出战略决策,这些技能正是AI智能体从工具转变为协作伙伴时所需的核心能力。
本文来自微信公众号“智东西”,作者:王涵,编辑:漠影,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com