
现在我是AI产品经理,用了几个开源模型。






作为AI产品经理,自然要接触到AI模型。
除了调用API,很多产品经理也希望团队进行私有部署,通过建立自己的AI模型来个性化自己的功能设计,保证数据安全。
但不同模型的参数值不同,因此所需的硬件资源也不同。例如,DEEPSEEKEEK 除了我分享的Macc之外,理论上需要700GB显存,最低要求是512GB显存。 studio ultra 另外,就是购买几十万的GPU显卡服务器。
然而,有些模型不需要摇动这么大的显存。参数越小,成员越低。
因此,在今天的文章中,我根据不同的使用场景,在博士研究和产品研发中选择了一些开源模型。除了建设端到端的能力,还有很多模式建设的场景需求,都是考虑不同的模型能力。
但是由于政策法规的原因,一些AI模型在国内很难通过备案审核,也不能谈起落地。
如果面对国内客户,产品经理只能选择国产模型。在不同的场景中,客户应该考虑不同的模型选择,甚至模型组合。
从模型列表中选择模型:推荐一个模型列表 LLM rankings
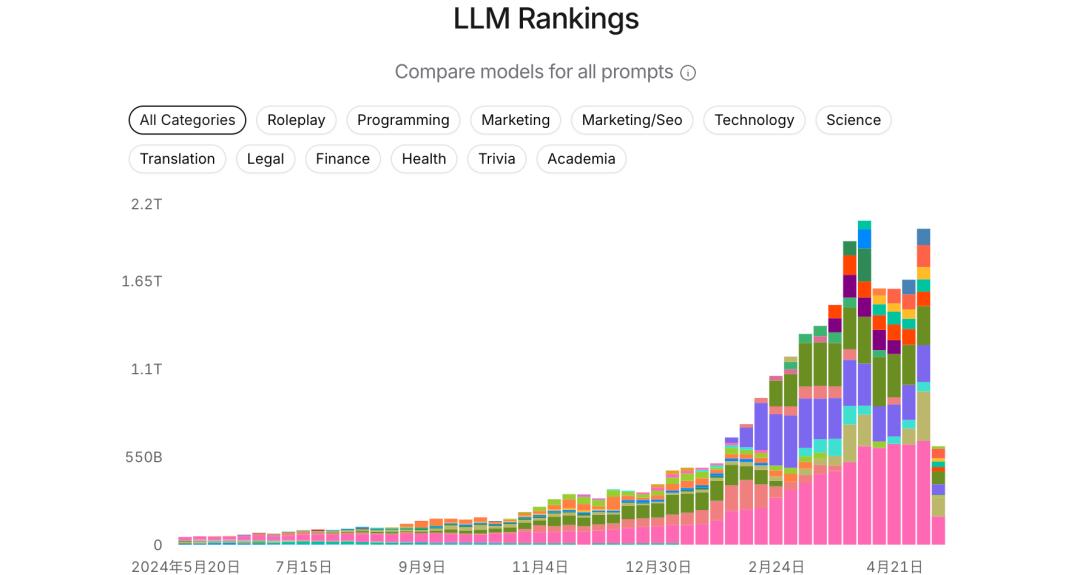
这里可以看到各种模型列表,有了模型列表之后再去看看。 https://huggingface.co/上来寻找开源模型下载。
首先看一下模型列表,可以看到目前国内开源型DEEPSEEK R1 V3领先于V3。
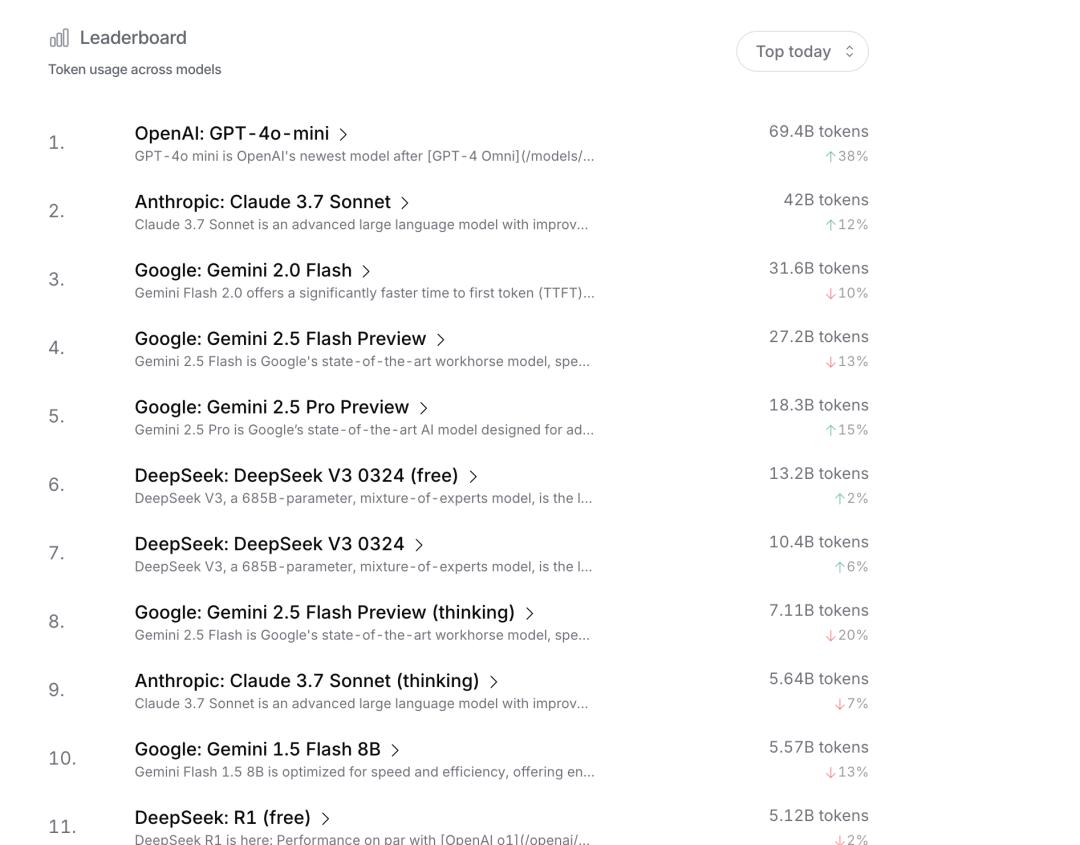
当然,现在有很多列表。不同的列表侧重点不同。有的只注重开源模式,有的只注重聊天,有的在评价推理能力。因此,找到你需要的列表也很重要,可以参考一些主流列表。
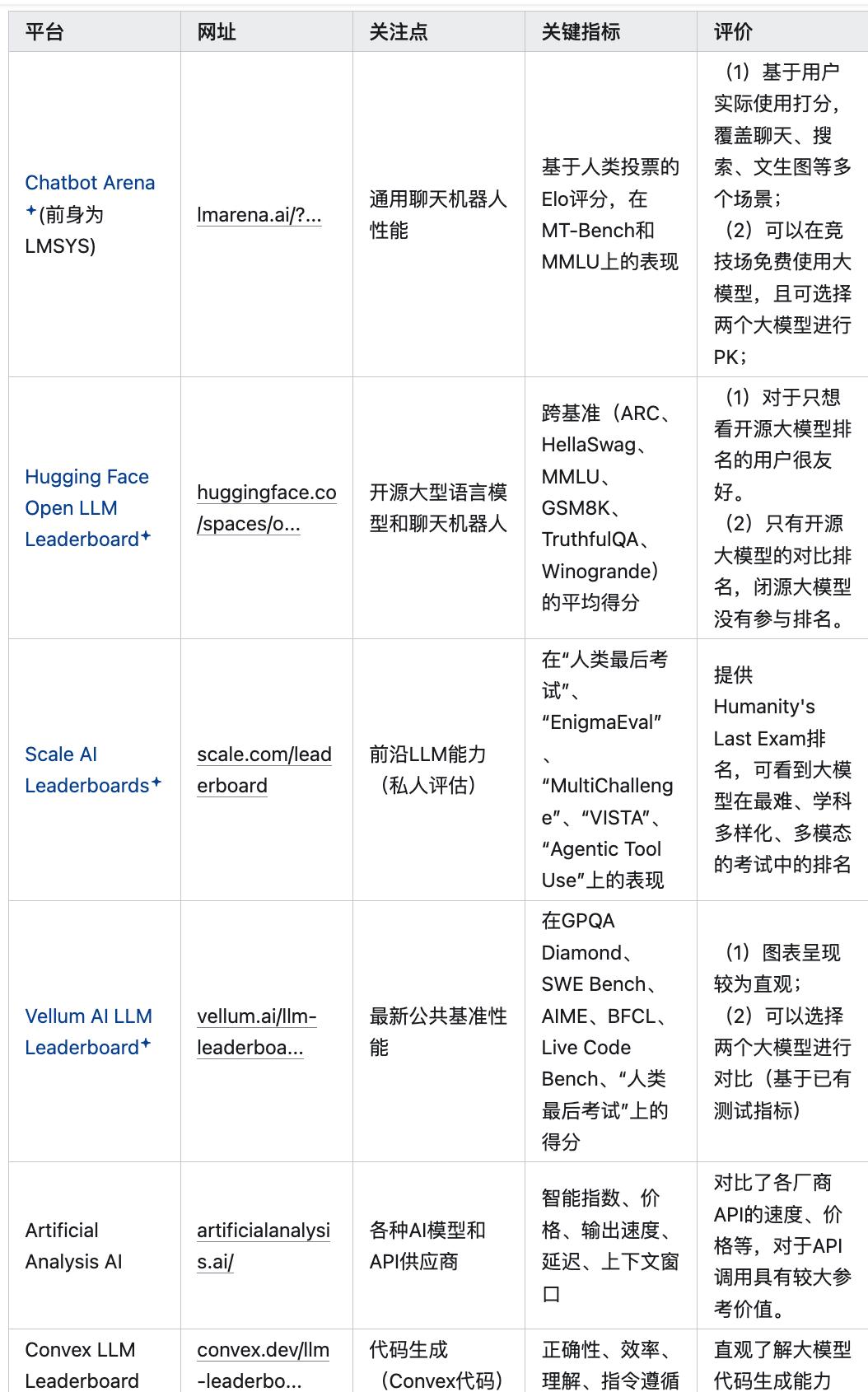
接下来我将分享一些我们开源部署的主流模型。
适用于国内用户的大模型
阿里通义qwen3.0
选择支持多模态和视觉,而阿里同义千问的参数值没有DEEPSEEK 如此之大,在显存上的占用很少。
我们改善了 Qwen3 模型 Agent 和 代码能力,而且还加强了对代码能力, MCP 支持。以下是一些例子,展示 Qwen3 怎样思考,与环境互动。
在国内情景中使用阿里同义千问肯定没有问题,因为是国内生产的,所以在开源中使用完全不用担心合规。
2.DEEPSEEK R1 与V3
两种模式都可以使用,但如果您想要快速输出结果,则使用DEEPSEEK V3 ,若需要其推理和关注如何进行深入思考,则R1模型。
V3是一种全能的大语言模型,作为DeepSeek的默认模型。(LLM),选择混合专家系统是一种可以处理通用任务的工具。(MoE)结构,可以根据不同的任务激活特定的“专家”模块,在节省计算率的同时保证精度。
国内其它开源模型3.
目前,如果我国能够使用并达到国际水平,我们将选择这两种模式。当然,如果你专注于某个行业或场景,比如医疗和金融,就会有百川。 智慧一般,专注于视频生成就有腾讯混元模式,可选择某些特定的开源模式。然而,这些模型只能在特定的行业产生效果,但目前,通用模型的能力涉及到这些行业,用户的场景不仅仅是在某个行业,还有跨行业。
开源模型适用于CPU等移动终端部署。
由于手机的CPU和GPU性能有限,因此我们可以选择参数较低的大型模型,为了能够应用于手机本地化运行,现在选择了微软的bitnetb1.58,大型推理的能耗可以大大降低,性能优越,可以在单个CPU上运行。 100B 参数 BitNet b1.58 达到人类阅读速度的模型(5-7 tokens/s)。BitNet 框架,在手机、边缘终端等设施上运行大模型成为可能。。
而且在国外,可选择的开源模型如下
llama4
Facebook孵化的第一个开源模式,现在是海外领先的开源团队,并支持多模式。模型通过“初始组合”将文本、图像、视频等模态数据统一整合到模型骨干中,支持联合预训练。比如,Llama 4 Scout可以处理1000万token的前后文本(相当于15000页文本),并且支持多个图像输入(最多48个),在医学、科学等领域具有显著的潜力。
LTX-Video Model Card
一个支持文本生成的视频模型,现在如果你想生成一些材料,你可以使用它。生成相应的视频模板
Parakeet TDT 0.6B V2
支持文本转语音,将其文本能力转化为语音能力生成模型。
Stable Diffusion v1-4 Model Card
对文字生成图像模型的支持, 即现在最热门的图片校正,将其模型生成图片,并支持文字生成图片。
Whisper
同时也是一种语音识别模式,将其语音转换为文本,可以支持机器人学习,并配合TTS开始文本对话。
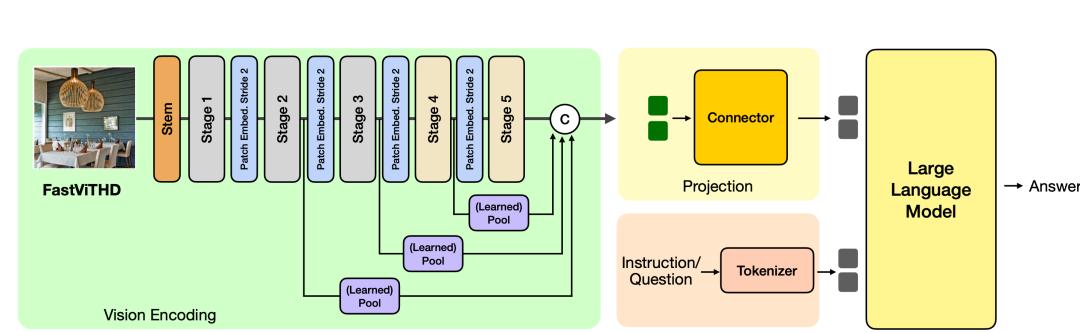
fastvlm
它是苹果推出的苹果视觉模型,可以快速识别物体,调用并回答语言模型。
模型机制
不同模型的分类与组合,构建产品经理的场景。
我们可以将模型分为生成文本、生成图片、生成视频和语音。不同的模型使用不同类型的数据,但现在我们最多可以形成一些图片,但其他场景功能应该区分开来。
这涉及到多种模式的合作。如果我们是数字人的产品系统,我们需要文本生成和相应的语音识别,这需要多种模式的对接和整合。
这就涉及到非端到端模型的缺点,其计算流程链接长,导致响应速度慢。以上是我们做的数字人。如果我们能看到缓慢的响应,我们将涉及许多模型调用。
有几种开源模式可供选择,其中ASR分别为、TTS、以及DEEPSEEK V3。然而,作为一名AI产品经理,我们可以看到学习的难度和门槛越来越高,至少我们应该熟悉英语,同时我们应该有时间了解这些开源模型来帮助文档。
这篇文章来自微信公众号“Kevin改变世界的点点滴滴”(ID:Kevingbsjddd),作者:Kevin那些事情,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com