
国产大模型“五强争雄”,血战AGI






中国基本的大模型市场,完全变了!现在桌子上的玩家已经成为「基模五强」——字节,阿里,阶跃星辰,智谱和DeepSeek。下一次巅峰对决,关键的制胜点又将在哪里?
DeepSeek的诞生彻底改变了全球AI形势。
从此,不仅中美大模型竞争格局发生了变化,国内大模型产业版图也一举被打破!
纵观中国基础大模型的市场,我们可以看到,今天的基础大模型版图已经改天换地,演变成了全新的五强格局。——
字节,阿里,阶跃星辰,智谱,以及DeepSeek。
新基模五强突破,下一个胜利点在哪里?
为什么脱颖而出的这五强,能成为留到最后的玩家?
回答很简单——要么有钱,要么有人。
前一种,道理大家都知道。大型训练模式是明牌重注,要么自己有粮食,要么自己有大腿。
像字节,阿里,DeepSeek,都属于有粮食的类型;而智谱和阶跃星,无疑属于后者。
其中,上海队阶跃星最新一轮融资发生在24年底至25年初,B轮融资数亿美元;2025年3月,北京队智谱获得18亿元融资。
而且说到人,自然是高密度人才,特别是需要行业认可的技术领导者。
如果我们仔细盘盘,就会发现,五强在这方面是分足鼎立的,各有骨干。
字节的吴永辉,阿里的吴泳铭,周靖人,阶跃星辰的姜大昕,张祥雨,朱亦博,智谱的唐杰,张鹏,DeepSeek的梁文锋,都是业界能够撼动局面的人物。

满足了有钱又有人,在这方面起跑线上各家都差不多,接下来要竞争的,就是硬货。
五大基模,各领风骚
事实上,仔细分析,就会发现五强的共性。
或者是全才,模型能力要能做到全面覆盖,并且性能在第一梯队。或者是专业人士,模型在某些方面遥遥领先。
阿里:开源王,世界第三。
阿里以「开源王者」独特的定位不仅在国内市场占有重要地位,而且在全球AI开源生态中稳居世界前列。 3模型推动者。
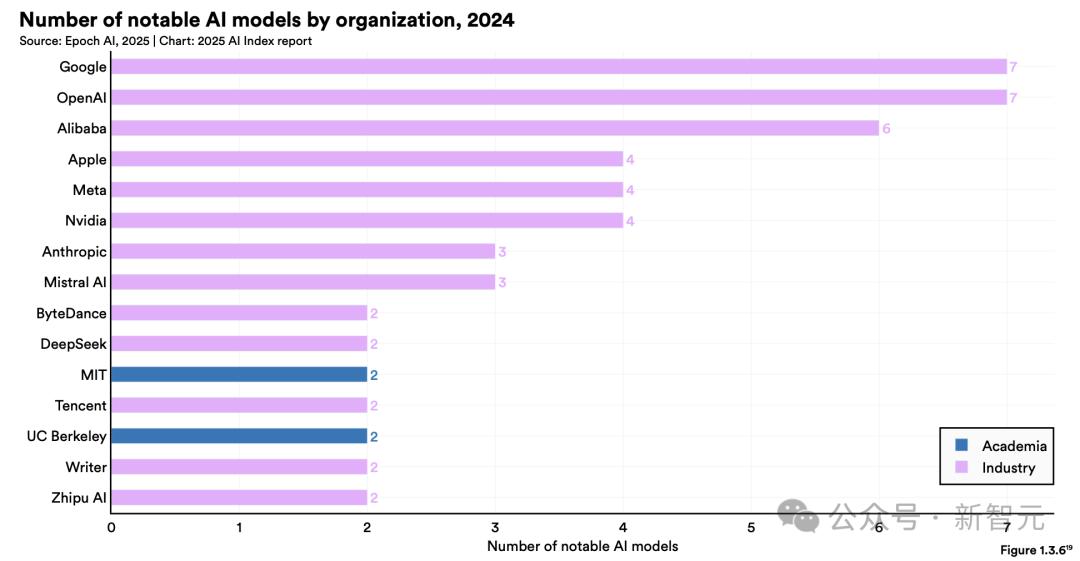
2025年斯坦福人工智能指数报告
可以说,阿里是中国最开放的LLM互联网巨头,也是世界上唯一实现的国家。「全尺寸,全模态」开源云计算制造商。
可以说,阿里作为开源最早、最完整的大企业,在AI投资方面是最坚决的,也是中国互联网巨头,布局最全,赚钱最多。
自2023年以来,通义团队累计开源2000 包括千问在内的模型(Qwen)大语言模型和万相(Wan)两大底座系列的视觉生成模型。
这类模型涵盖了文本生成、视觉/语音理解生成、文本生成、视频生成等全模式,参数规模从0.5B到235B不等,跨越了119种语言和方言。
两年前,国内LLM市场仍处于领先地位「百模」在混战阶段,阿里率先开源Qwen-7B,引起了全球开发者的关注。
Qwen全球下载量超过3亿,衍化模型超过10万,超越Llama成为世界上第一个开源模型。
这是Hugging 2024年,Face社区Qwen系列占全球模型下载量的30%以上,排名第一。
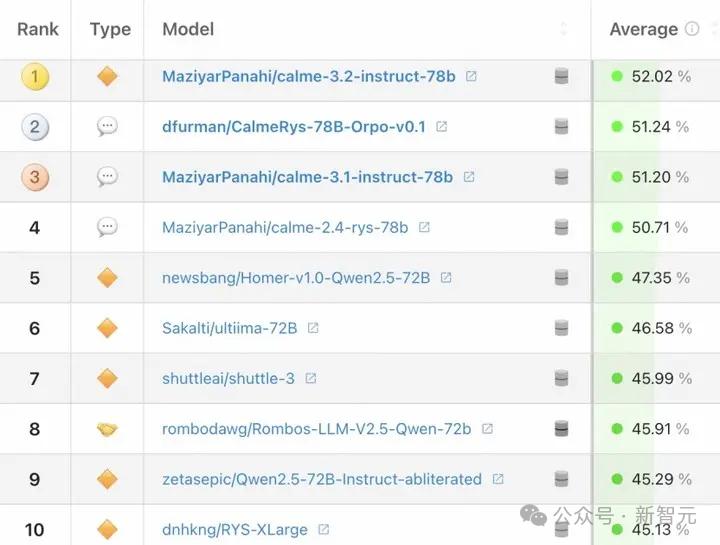
25年2月,Hugging 在Face全球开源模型榜单中,前十大开源模型都是基于Qwen二次开发的。
在这场「烧钱」未来三年,阿里还将在AI研发上投入3800亿元,用于云和AI硬件基础设施,总额超过过去十年的总额。
这种投资规模在国内互联网公司中首屈一指,正好展现了阿里在AI赛道上的战略决心。
与其它大型玩家相比,阿里凭借完善的商业化路径和广泛的客户基础,率先实现了投资收益的闭环。
截至2025年1月底,已有29万多家公司通过阿里云百炼平台调用通义大型API。
字节:巨型航空母舰,回归创业
大型字节模型「综合能力强」它涵盖了文本生成、图像理解、视频生成、语音处理等多种模式领域。
在这场技术与资源的巅峰对决中,字节不仅展现了自主研发模型和AI应用领域,「残酷的战斗力」。
现在,字节旗下的AI应用超过20款,爆红核心产品「豆包」凭借其强大的文字生成和多模态能力,迅速占据用户心智,月活用户超过1亿。
视频生成工具「即梦」在虚拟偶像、电商直播等领域,也被赋予了更高的战略优先权,实现了商业化。
类似地,字节不敢落后于AI编程领域。与Cursor等AI集成开发环境相比,他们推出了AI编程工具Trae。
就企业服务而言,以豆包大模型为基础,火山引擎「飞连」AI应用程序也在多场景落地等。
字节的全面布局也体现在它的生态整合能力上。字节通过抖音、今日头条、飞书等渠道,将大模型嵌入内容推荐和协同办公中,构成了从技术到应用的生态闭环。
而且现在,字节以「重返创业的巨型航空母舰」姿态,以雄厚的资金,极高的人才密度,多方向的全面布局,成为中国AI跑道的领头羊之一。
阶跃星辰:低调的大模型国家队
与其它家庭相比,阶跃星辰可以算是五强中最低调的大型国家队。
可以说,阶跃星是一支出生在上海,在上海长大的国家队。2024年底,阶跃星完成融资总额达数亿美元,包括上海国有资本投资有限公司及其基金在内的核心投资者,包括腾讯投资、五源资本、启明风险投资等。
现在只成立了两年,已经发布了22款自主研发的基础模型,涵盖文字、语音、图像、视频、音乐、推理。其中16款是性能领先整个行业的多模态模型,得到了业界的认可「多模态卷王」。
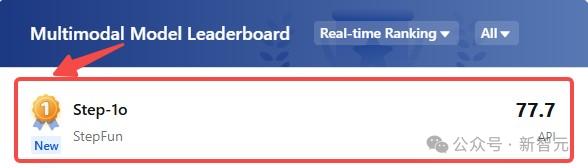
其中,Step-1o 2025年初,Vision分别在Chatbotbot中分别进入著名的大型试验场。 国内权威评估平台Arena「司南」(OpenCompass)其中,各自在视觉领域中获得了中国大模型第一名,在多模态模型榜单中获得了第一名。
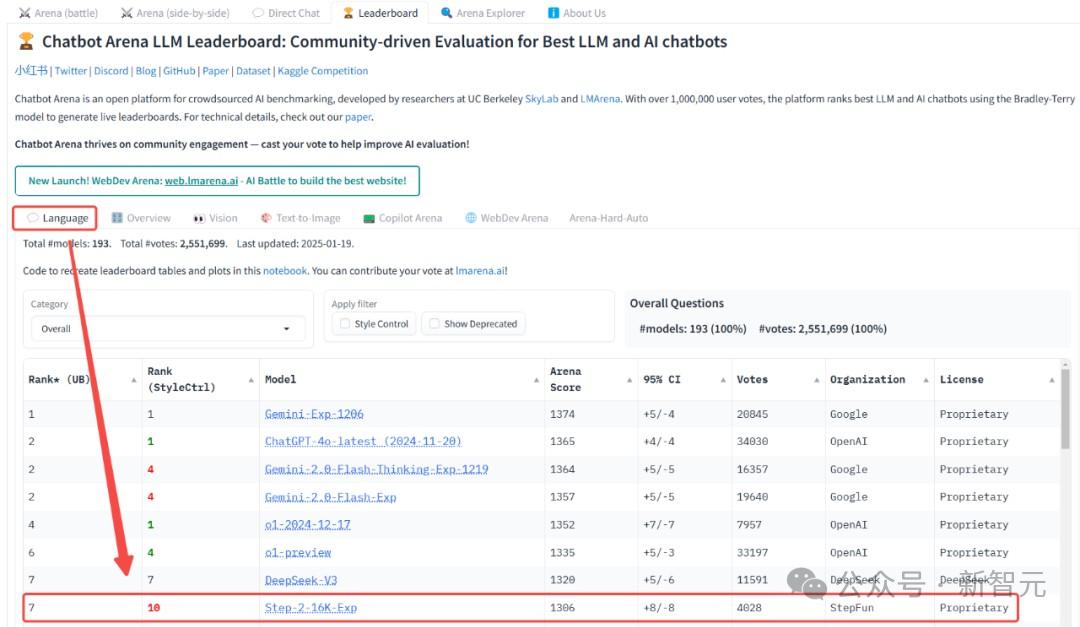
更难得的是,阶跃星的多模态矩阵全面,在整个行业都处于领先地位。要知道,多模态模型的核心是综合能力,不仅需要语音、照片、视频的多模态能力,还需要模型的理解、生成和推理。在这种布局中,阶跃星的每一条线都达到了第一梯队。
多模还有一个很大的困难,就是单个模特的性能在组合过程中不能丢失,尤其是智力下降。阶跃星采用原生多模式,在这方面有独特的经验。
在阶跃星星看来,多模式是通往AGI的唯一途径。随着多模式交互和推理的结合越来越完善,更多的Agent将出现在智能终端上。
现在,阶跃星辰正在努力彻底解决视觉领域的基本问题——表征与对齐,即「predict next frame」。
未来,AI将能够建模物理世界互动,模拟整个世界,建立世界模型,按照阶跃星辰的多模R&D路径。到目前为止,AGI已经实现了。
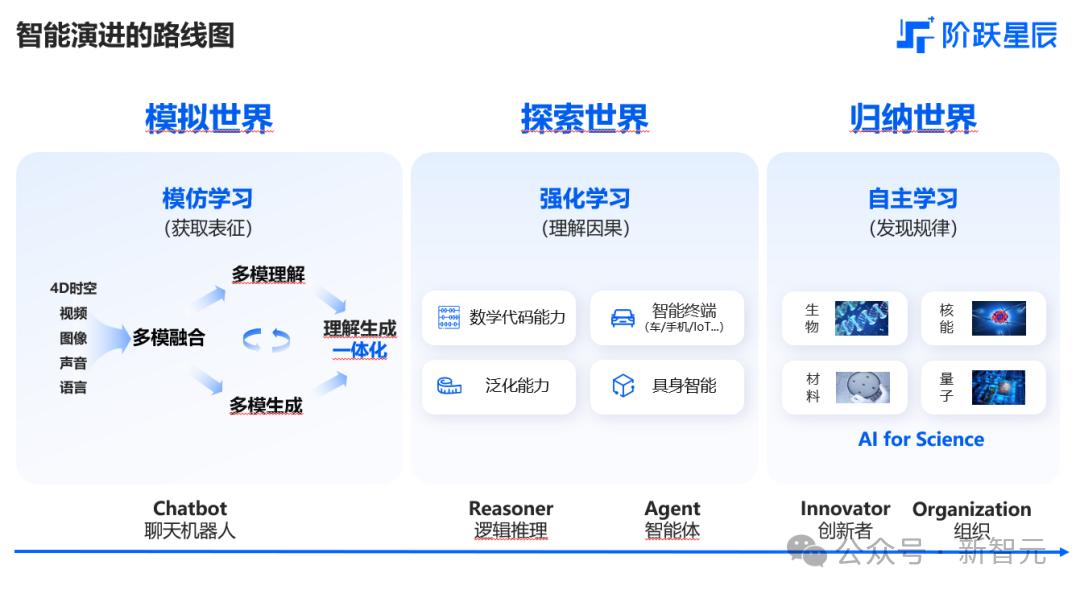
成立之初,姜大昕团队就画出了这样一幅智能进化路线图,将智能进化分为三个阶段:模拟世界、探索世界和总结世界。
同时,阶跃星的核心技术人员在一线经历了十年的AI发展。这个团队人才密度极高,既有技术洞察力,又有实践经验,堪称基本模型。「梦之队」。
其中,创始人、首席执行官姜大昕曾担任微软全球副总裁、微软亚洲互联网工程院副院长、首席科学家。2025年IEEEE当选 姜大昕博士,Fellow,是中国唯一一家大型创业公司的候选人。
与之相比,首席科学家张祥雨参与了《图像识别深度残差学习》论文。(ResNet)这是21世纪以来世界上引用次数最多的论文,引用次数超过25万次。
在商业化方面,很多头部企业和大量AI应用开发者都认同阶跃的多模式模型,纷纷接入。同时,阶跃还将智能终端Agent视为大模型落地的核心突破点,已与吉利汽车、万里科技、OPPO、实现深度合作的智元机器人、原力灵机、TCL等。
智谱:全栈创新,使力智能体
智谱作为国内首家开放IPO模型的创业公司,背靠清华的技术底蕴。「学院派」独特的气质脱颖而出,全面布局底座模型、多模态技术和智能体。
当前,智谱已建立新一代认知模型技术体系,开发了全栈自主GLM模型,其性能参数与国际顶级LLM对齐。
去年8月,GLM-4-Plus问世在多项任务中表现出色,与GPT-4系相当。
今年4月,智谱再次开放了包括底座、推理和思维模型在内的32B/9B系列GLM模型。主流模型性能与320亿参数相媲美。
GLM-Z1-Rumination思维模型是智谱对下一代AGI技术的最新探索。
就智能体而言,智谱先于OpenAI提出Phonene Use概念并推出了Agent产品,并发布了全球首个集深度研究和实际操作于一体的L3级智能体——AutoGLM思维。
现在,他们正以AutoGLM和GLM-PC与全球汽车公司、PC和手机制造商进行深度合作,推动大模型从Chat走向Act。
以2G和2B业务为核心的智谱商业化路径,对政府和企业的需求有着深刻的联系。
它构建了包括百万规模开发者在内的MaaS私有部署和智能体平台等服务模式,构成了模型服务的新生态。
根据统计,MaaS平台支持超过80万的企业和应用程序开发者。
这一学术创业模式,促使智谱在技术深度和战略稳定性上占据领先地位。
DeepSeek:研究方向,厚积薄发
DeepSeek,这是目前五强中最受海外关注的一个。同时,在中美AI大赛中,也是被提及最多、存在感最强的一个。
可说,这是一个特立独行的技术奇兵,直接用自己的力量,掀翻了大型牌桌。
DeepSeek技术的特点是聚焦语言模型,特别是数学能力,走坚定的开源路线。
今年春节期间,DeepSeek-R1以极低的计算资源获得了与GPT-4等顶级AI模型相媲美的性能,给全世界带来了亿点震撼。
与OpenAI相比、在Anthropic训练模型中,数亿美元的资金、数万个高档GPU、DeepSeek四两拨千斤的关键秘诀在于以下极致的工程优化。
举例来说,MoE架构使模型总参数达到671B,而在运行过程中只需激活37B,大大降低了计算需求;多token预测(MTP),这样可以提高AI的练习效率,防止逐字预测;双头潜注力(MLA),使模型能够更准确地分配计算资源。
总而言之,DeepSeek成功的关键在于偏向研究型的方向,而非以盈利为短期目标。在不面临财务变现压力的情况下,从研究角度鼓励工程师提高效率。
而且DeepSeek团队,也聚集了许多顶级人才。创始人梁文锋,在用人方面也有自己独特的原则。
举例来说,以应届毕业生和毕业一两年的人才为主,不追求规模,而是建立一个小而精的团队。
伴随着大规模的破圈,云厂商、行业合作伙伴纷纷积极接入,使模型的生命力持续旺盛。
随着DeepSeek的热潮,现在已有数亿普通用户开始拥抱AI。
血战下一阶段,「智能上限」与「多模态能力」
当「基模五强」局势初步形成,竞争的焦点也随之转变为更具核心和前沿的技术领域。
技术决胜点,重点在哪里?
显然,追求更高的东西「智能上限」和突破的「多模态能力」,在通往AGI的道路上,已经成为两大技术高地。
另一方面,追求智能上限仍然是目前大型模型领域最重要的问题。
虽然目前领先模型在很多任务中表现出色,但是在逻辑判断、常识理解、长文本处理等方面,仍然有很大的提升空间。
提高智能上限的最终目的是走向可以执行任何人类智商任务的AGI,这就需要模型具备更深层次的理解、学习、推理和创造能力。
另外,多模态理解和产生的统一是走向AGI的唯一途径。
人类通过各种感官与世界互动,获取信息。为了让AI真正理解和融入复杂的世界,它必须赋予它处理和整合各种模式信息的能力,如文本、图像、音频和视频。
在理解和生成统一的情况下,不仅可以促进智能终端的普及,还可以收集环境数据,通过智能与物理世界的交互构建世界模型。
AGI可以在世界模型的基础上实现,加上复杂任务的规划、抽象概念的归纳能力、学习算法的强化能力和非常对齐的能力。
总而言之,未来对更全面智能上限的无限探索与多模态能力的深度融合,将是决定这场比赛输赢的关键。
现在站在AGI的门槛之前,「基模五强」竞争不仅仅是技术竞争,更是资源、人才、生态的全面博弈。
五大领军人物,字节、阿里、阶跃星辰、智谱、DeepSeek,正以其独特的优势和战略远见,推动中国AI不断接近世界前沿。
而且这场比赛的结束,也许正是AGI的曙光。
参考资料:
https://qwenlm.github.io/zh/blog/
https://seed.bytedance.com/zh/
https://platform.stepfun.com/
https://www.deepseek.com/
https://zhipuai.cn/
https://chat.z.ai
本文来自微信微信官方账号“新智元”,作者:新智元,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com