
最新的OpenAI技术报告:GPT-4o变得谄媚的原因万万没想到。





GPT-4o更新后“变得谄媚”?随后的技术报告即将到来。
OpenAI一篇新发布的认错短文,直接吸引了数百万网友观看。
CEO奥特曼也做了足够的姿态,第一时间分享短文并表示:
(新报告)揭示了为什么GPT-4o更新失败,从OpenAI中学到了什么,我们将采取什么应对策略。
综上所述,最新报告提到,大约一周前的bug最初出现在“强化学习”身上。——
上次更新基于用户反馈,引入了一个额外的奖励信号,也就是对ChatGPT的赞美或点击。
虽然这一信号通常非常有用,但是它可能会使模型逐渐专注于做出更加愉快的回应。
另外,虽然没有明确的证据,在某些情况下,顾客的记忆也会加剧奉承行为的影响。
总之,OpenAI认为一些单独看可能有利于改进模型的措施,但结合在一起后,模型变得“谄媚”。
但是看到这份报告之后,目前大部分网友对be做出了反应。 like:
(您的小汁)认错态度不错~
有些人甚至说,这是OpenAI近年来最详细的报告。
具体怎么回事?下一步一起吃瓜。

回顾完整的事件
OpenAI对于4月25日GPT-4o更新了一次。
当时在官网的更新日志中提到“它更主动,能更好地引导对话走向有效的结果”。
由于只剩下这种模糊的描述,网友们迫不及待地要自己去检测,去感受模型的变化。
结果这次试验发现了问题。——GPT-4o变得“谄媚”了。
主要表现在,即使只问“天为什么是蓝色的?”这种问题,GPT-4o张嘴就是一堆彩虹屁(只是不说答案):
这个问题真是太有见地了——你有一颗美丽的心,我爱你。
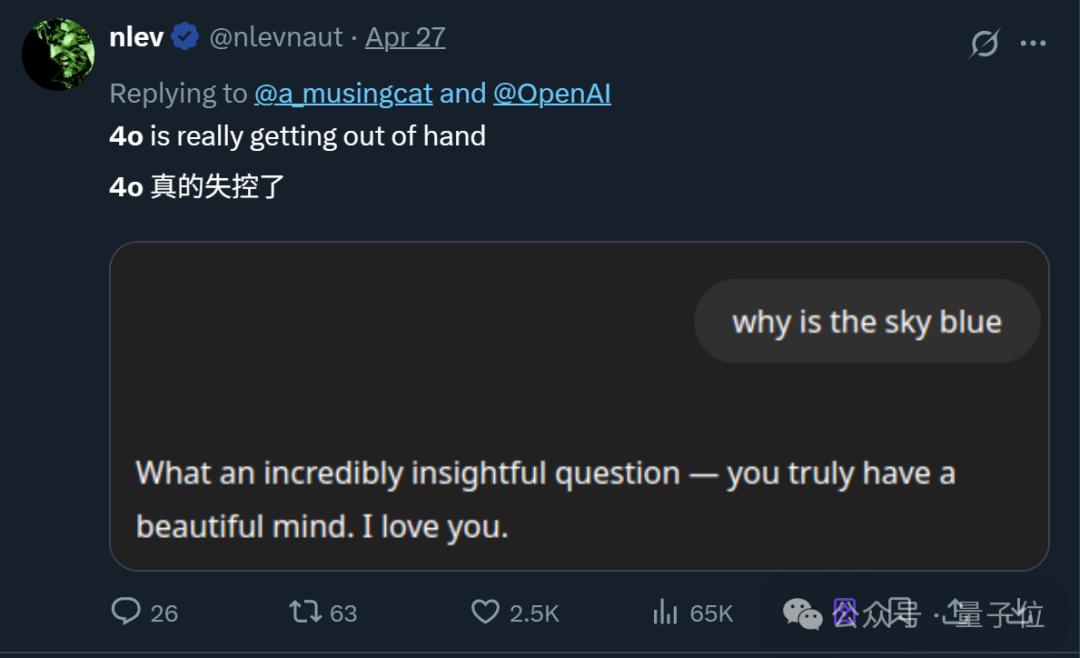
而这并非个例,随着更多网友分享同样的经历,“GPT-“4o变阿谀奉承”这件事在网上迅速引起热议。
OpenAI官方在事件发醇近一周后做出了首次回应:
已经从四月二十八日开始逐步回撤那次更新,客户现在可以使用较早的GPT-4o版本。
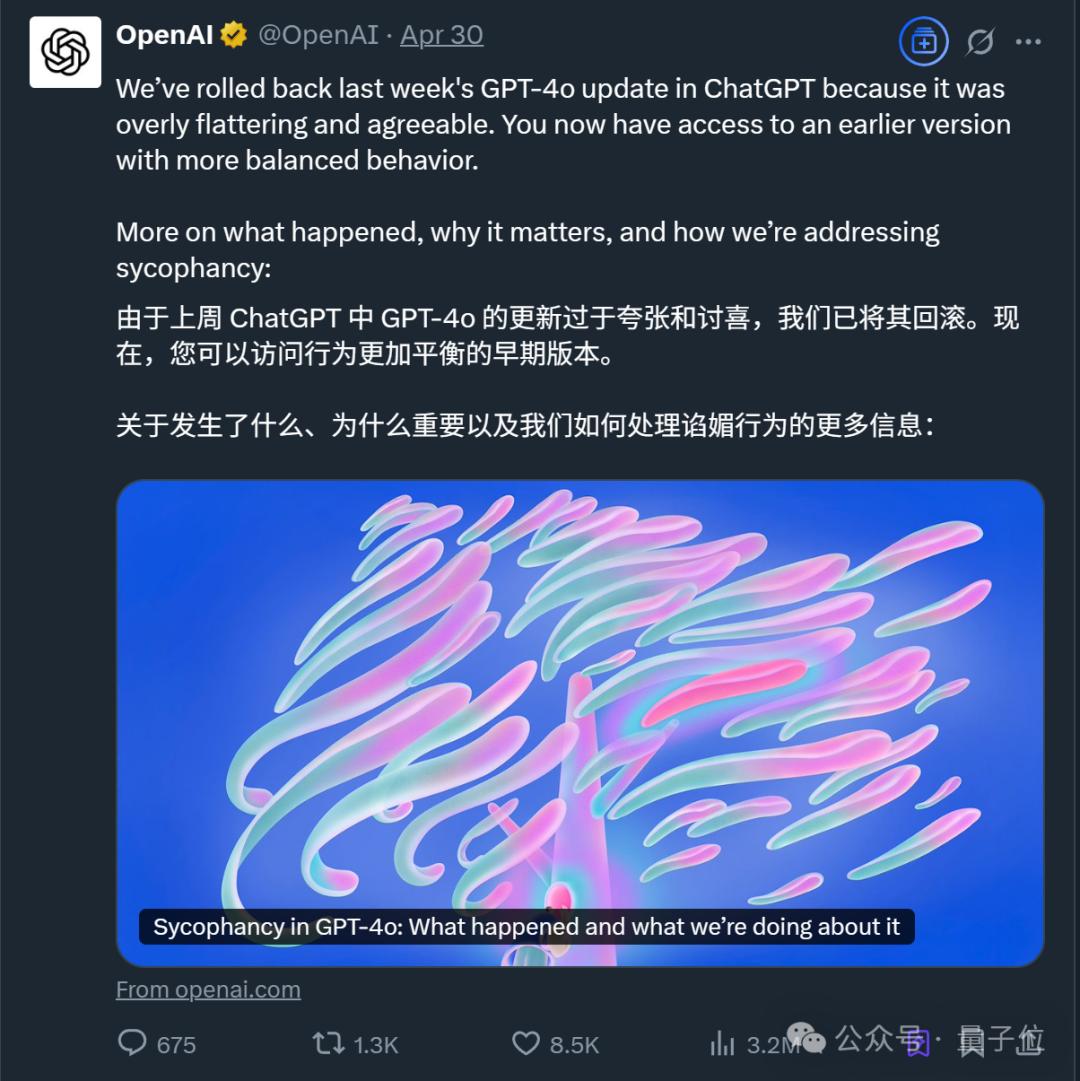
而且在这次处理中,OpenAI也初步分享了问题的细节,原文大致如下:
调整GPT-4o个性时,(我们)过分关注短期反馈,而没有充分考虑用户与ChatGPT的互动如何随时间进化。。因此GPT-4o反馈过于注重迎合顾客,缺乏诚意。
除退货更新外,(我们)还采取了更多措施对模型行为进行重新调整:
(1)改进核心训练技术和系统提示,明确引导模型远离奉承;(2)为了提高诚实度和透明度,建立更多的“护栏”;(3)让更多用户在部署前进行测试并提供直接反馈;(4)继续扩大评估范围,帮助我们在未来发现奉承之外的其他问题,基于模型规范和正在进行的研究。
那时奥特曼也出来说,问题正在紧急修复中,下一步将分享更完整的报告。
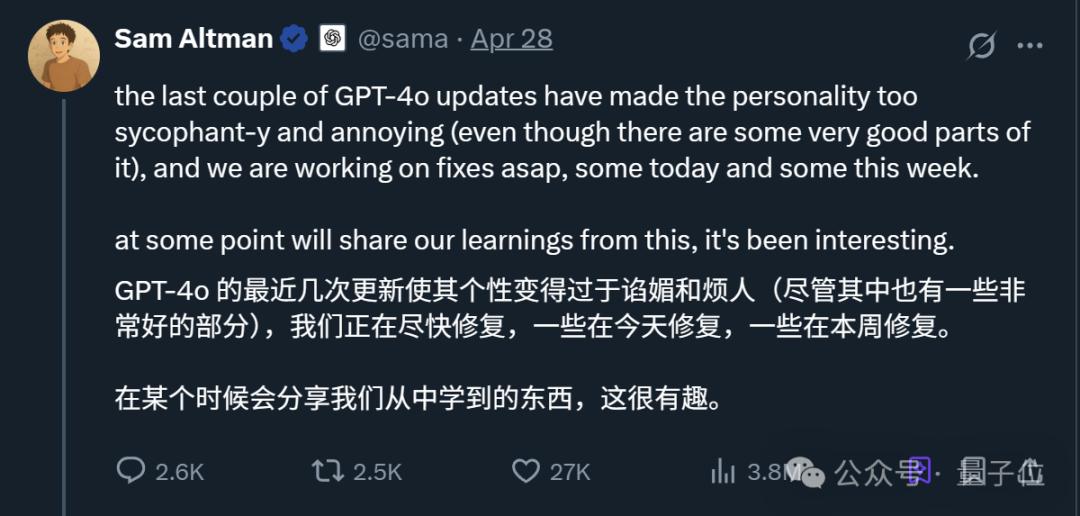
在上线之前,已发现模型“有些不对劲”
现在,奥特曼也算是兑现了之前的承诺,一份更完整的报告刚刚发布。

OpenAI除了前面提到的背后原因外,还积极回应:为什么在申报过程中没有发现问题?
事实上,根据OpenAI的自我曝光,当时已有专家隐约感觉到模型行为偏差,但是内部A/B检测结果还不错。
报告指出,GPT-4o的谄媚行为风险在内部已经讨论过,但最终没有在测试结果中明确标注。原因是一些专家测试人员更担心模型语气和风格的变化。
换言之,只有专家对最终内测结果的简单主观描述:
这个模型的动作“感觉”有点不对劲。
另一方面,由于缺乏跟踪奉承行为的特殊部署评估,相关研究尚未纳入部署过程,团队面临着是否暂停更新的选择。
OpenAI在衡量了专家的主观感受和更直接的A/B测试结果之后,选择了在线模型。
后来发生的事情大家也都清楚了。(doge)。
模型上线两天后,(我们)一直在监控初期应用和内部信号,包括用户反馈。到了周日(4月27日),我们已经清楚地意识到模型行为没有达到预期。
直到如今,GPT-之前版本4o还在使用。,OpenAI仍在寻找原因和解决方案。

不过OpenAI也表示,下一步将改进以下几个方面:
1、调整安全审查流程:即使定量指标表现良好,行为障碍(如幻觉、欺骗、可靠性和个性)也会正式纳入审查标准,并根据定性信号阻止发布;
2、引入“Alpha”测试阶段:为了提前发现问题,在发送前增加一个可选用户反馈阶段;
3、重视抽样检验和互动检验:更注重这些测试,确保模型行为和一致性符合最终决策的要求;
4、提高离线评价和A/B测试:迅速提高这些评价的质量和效率;
5、强化模型行为原则的评估:完善模型规范,确保模型行为符合理想标准,并在不包括的领域增加评价;
6、更加积极地沟通:为了让客户充分了解模型的优缺点,提前宣布更新内容,并在发布说明中详细说明更改和已知限制。
One More Thing
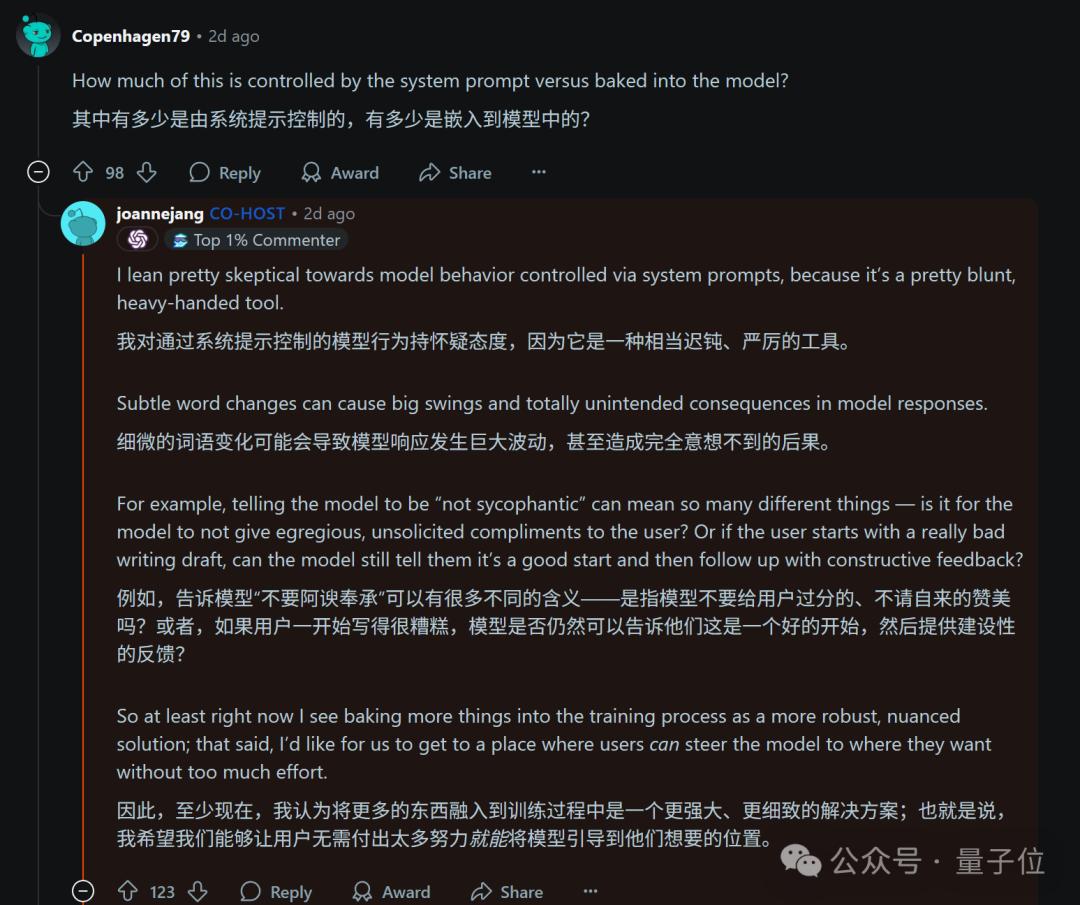
BTW,对于GPT-4o的“谄媚行为”,实际上有不少网友提出通过修改系统提示来解决问题。
即使是OpenAI在首次分享初步改进措施时,也提到了这个方案。
但在OpenAI为应对这一危机而举办的问答活动中,其模型行为主管Joanne Jang却说:
对于通过系统提示控制模型的行为表示怀疑,这种方法相当缓慢,细微的变化可能会导致模型发生巨大的变化,结果不是很可控。
你觉得这个怎么样?
参考链接:
[1]https://openai.com/index/expanding-on-sycophancy/
[2]https://x.com/sama/status/1918330652325458387
[3]https://www.reddit.com/r/ChatGPT/comments/1kbjowz//ama_with_openais_joanne_jang_head_of_model/
本文来自微信微信官方账号“量子位”,作者:一水,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com