
随着Qwen3的发布,阿里也将依靠多模式和性价比。






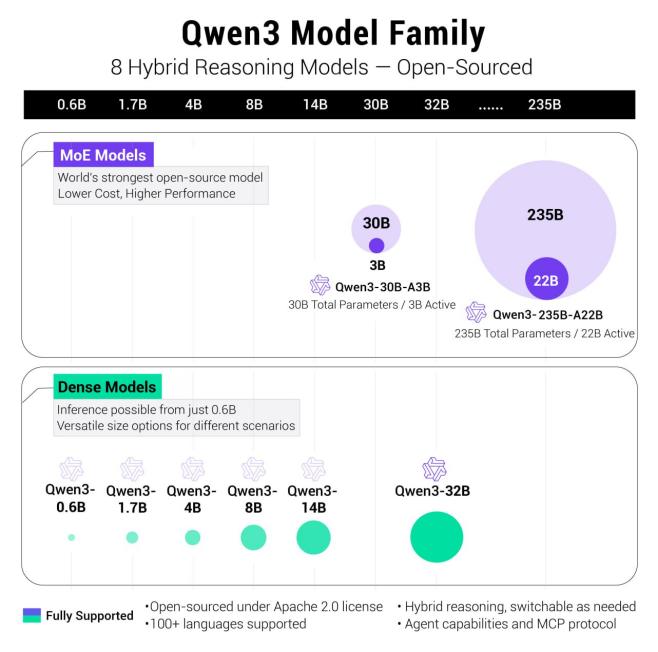
今日上午,阿里云正式发布了Qwen3系列,从0.6B到235B,一口气打开了8个模型:2个MoE模型和6个Dense模型,形成了一个完整的阿里模型矩阵。
这次Qwen3的开源重塑了大模型标准,可以说是“后DeepSeek” 在R1时代,以阿里为代表的国内大公司正以实用思维、性价比和多模态能力,全面争夺DeepSeek的市场影响力。
01 Qwen3再次提高了世界开源标准
这一次,阿里云开源的Qwen3在架构、性能、推理速度和应用方向上都有了很大的创新和提升。MoE(混合专家)架构是Qwen3系列的模型架构。
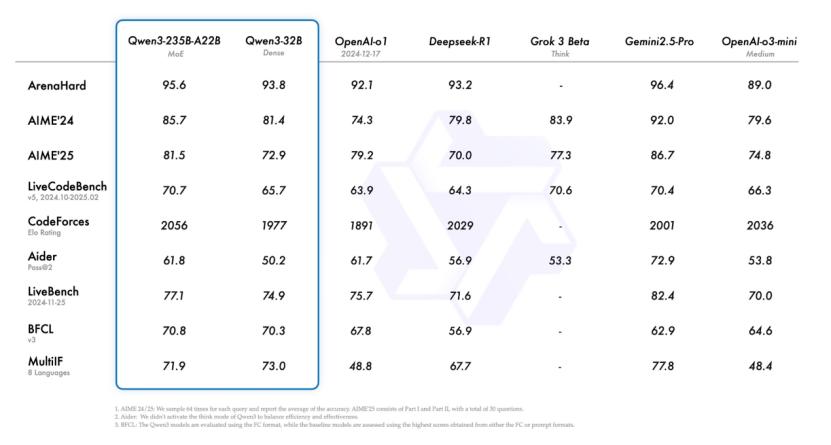
旗舰模型 A22B-Qwen3-235B- 在综合能力、代码与数学、多语言能力、知识与推理等多项基准测试中,总参数约2350亿,每次推理时仅激活约220亿参数,性能极其抗打。可以和DeepSeek一起使用 R1、OpenAI o1、o3-mini、Grok Geminiini3和谷歌 2.5 目前市场上的主流大模型Pro等相互竞争。
其中一个亮点是:Qwen3-4B模型在一系列基准测试中与GPT-4o(2024-11-20版)进行了一系列基准测试。这说明阿里在推理效率上的提高并非以牺牲能力为代价。
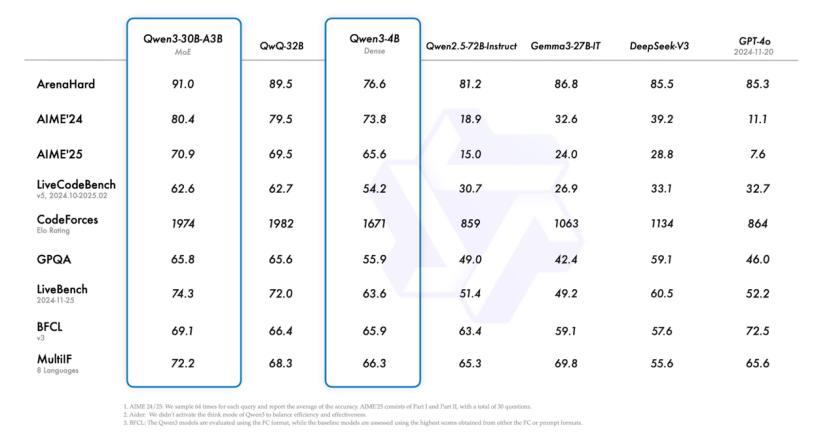
它的轻量化模型Qwen3-30B-A3B和32B,在很多任务中的表现也足够令人满意。
此次Qwen3系列的一个主要创新特点是:除了基准测试中的亮眼表现外,混合思维模式。这种设计允许用户根据任务难度控制模型的推理量:在思维模式下,模型可以逐步推理,适合复杂的问题,强调深度思维。无思维模式:模型响应快,适合简单的问题,优先考虑速度。用更多的推理来解决难题,快速回答简单的问题。
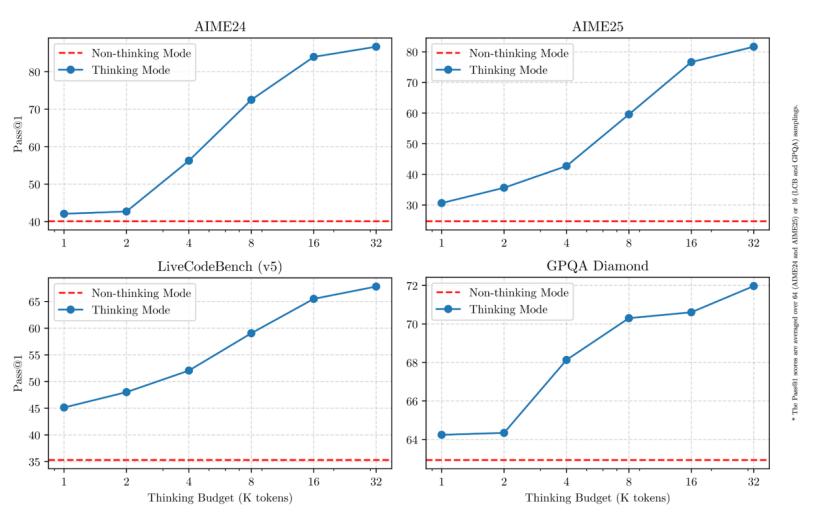
此外,Qwen3已经能够支持119种语言和方言,以扩大其在国际应用端的知名度。外国网民对它的评价非常好。如果横向比较,Qwen3已经追上或超越了OpenAI。 o1、Gemini谷歌 2.5 Pro。

Qwen3还对近半年爆红的“AI智能体”概念进行了改进,强调了“智能体”的能力。举例来说,他们强化了Qwen3 模型代码和代理能力得到增强, MCP 让Qwen3的支持 学习如何思考,如何与环境互动。
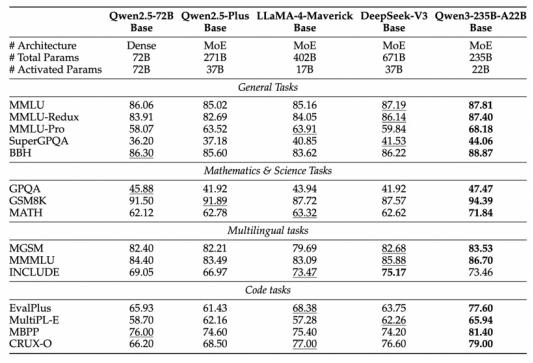
就预训练而言,Qwen3 与数据集相比 Qwen2.5 在复杂的任务处理和多语言场景中,几乎翻了一番,达到了36000亿个token,涵盖了更广泛的领域知识和情境,再次提高了其表现。
此次Qwen3系列开源,Apachee统一采用。 2.0开源协议开放权重。一个完整的产品逻辑是通过“小杯-中杯-大杯-超大杯”构建的。Qwen宇宙"。
总的来说,Qwen3 在技术性能简单,成本价格,工具调用与MCP调用等各个方面都有了全面的提高,它已将开源世界的标准提高到了一个更高的水平。
02 DeepSeek光晕下的大厂百相
百度创始人李彦宏在4月25日的2025百度AI开发者大会上点名批评DeepSeek。“这不是万能的。它只能处理单一的文本,不能理解声音、照片、视频等多种模式的内容。更大的问题是缓慢和昂贵。中国市场上大多数大型API价格更低,反应更快。”
在DeepSeek巨大的光晕之下,他指出了中国大厂正以性价比与DeepSeek竞争的现状:实现更快的响应,以更小的参数,更低的成本,完成不属于DeepSeek的多模态效果。
阿里的Qwen3迅速引入了MoE架构和双模式推理设计,大大降低了实际使用中庞大模型的成本。DeepSeek 参数R1的三分之一,性能完全超过R1。
第一,Qwen3的MoE结构促使部分专家在推理过程中被激活,从而降低实际计算费用。例如,虽然Qwen3-235B-A22B的总参数达到了235B,但是每个token只需要计算9%(22B)左右的参数值。这就是说,在类似的硬件条件下,推理延迟并不像参数规模那样高。
其次,Qwen3的双模式推理设计有效分配了计算率。在“非思维模式”下,模型可以直接生成答案,实现接近实时响应;然而,当你需要“思维模式”时,你可以投入额外的计算资源进行多步推理。这种按需分配计算的策略使模型在大多数简单的互动中保持快速,并在关键时刻发挥深层推理能力。
事实上,这类似于腾讯的双轨思维。腾讯元宝于2025年2月13日接入DeepSeek R1满血版,几天后上线。 混元T1模型“强推理深度思维模式”,随后混元团队正式宣布Turbo S模型在线测试,声称在响应速度上比DeepSeek更快 R1更快。Turbo模型优化日常对话,弱化长链推理,追求即时回答能力。在腾讯内部的AI助手“元宝”应用中,Turbo快速思考和T1深度思考融为一体。用户可以在需要详细推理的时候调用T1,通常会默认使用Turbo即时回答。
这种双轨策略类似于阿里Qwen3单模式的双模式,为不同复杂度的问题提供多样化的模式,既保证了效果,又保证了速度。
DeepSeek R1自正式上线以来,其幻觉现象频繁发生,已成为各大厂商的目标。
百度就是其中的代表。在国内大型模型竞争中,百度经历了一个明显的战略转折点:在DeepSeek等影响下,从最初坚持闭源、寻找商业变现,到宣布开源、全面免费的重大转变。
2025年3月16日,百度如期发布了文心大模型4.5。文心4.5被定义为百度首个具有图像、文字、音频等多模式联合理解和生成能力的“原生多模式”模型。它引入了深度思维能力,可以逐步推理复杂问题,集成了百度自主研发的iRAG检索增强技术。
通过“深度搜索”功能,文心4.5可以自动识别外部知识来回答客户的问题,显著降低了幻觉率,这也是百度面对DeepSeek的信心。
就价格而言,百度也开始加码。百度AI开发者大会前几天发布的文心4.5Turbo,与文心4.5相比,价格下降了80%,每百万token的输入输出价格仅为DeepSeekek。 V3的40%。在大厂商面前,DeepSeek的成本优势已经化为乌有。
为了应对DeepSeek的竞争,字节跳动专注于多模式。2024年5月,其火山引擎团队首次全面介绍了编号“豆包”的大模型家族。自9个模型一口气出现以来,豆包一直专注于多模式模型的发展。
与其他喜欢强调模型参数和基准测试结果的厂商不同,字节刻意淡化参数的规模和列表,进而突出实际落地性能和低使用门槛,努力让大模型真正融入多样化的实际场景。
本月中旬,豆包1.5深度思维模式上线,在数学推理、编程竞赛、科学推理等专业领域表现超越DeepSeek。 除了R1,Doubao-1.5是最大的亮点。-thinking-pro-vision具有视觉推理理解能力,同时发布了豆包文生图3.0版,进一步丰富了多模态生态。
字节跳动多模态战略的背后,是敏锐感知大模型从技术概念向产品概念转变的路径。之后,DeepSeek 在R1时代,单纯追求参数规模和技术指标的提高已经不足以建立商品环城河。
字节跳动带着这个宇宙厂商的“互联网基因”,加入了大模型竞争。多模型的并进保证了它在文本、语音和图像方面的全面开花;极低的价格和广泛的商品植入为其获取了规模和数据。
总体而言,除专业领域的基准测试刷分外,价格、响应、多模态已成为各大厂商应对DeepSeek竞争的有力武器。在基本语言对话能力难以拉开距离的情况下,各大厂商通过产品思维找到了快速突破DeepSeek的差异化功能。
03 结合开源生态的长期和短期利益
随着DeepSeek、Llama、Qwen、智谱在开源生态建设上付出了越来越多的努力,开源已经成为主流路线之一。过去,大工厂专注于关闭源头来盈利,但现在开源被证明是获得生态和快速迭代的有效途径。DeepSeek进一步刺激了大工厂拥抱开源生态的决心,阿里全面开源的问题证明了 AI时代的主题是模型开源。
不难看出,国内大模式正在走向一个综合实力和效率竞争的时代,而不仅仅是基于参数和单点性能。
Qwen3、DeepSeek以及腾讯、百度、字节的各种“模型”迭代实践,反映了一个变化:每个人都在追求更高的性价比——性能要足够好,成本要足够低,应用要广泛。
可以说,在AI的后半段,我们正在进入。

OpenAI的研究人员姚顺雨最近发表了一篇长文,讨论了AI后半段应该致力于哪里:“从现在开始,AI将解决问题转化为定义问题。如果你想在‘后半段’蓬勃发展,你应该及时改变你的思维方式和技能,更接近产品经理的水平。”
阿里云CTO根据晚点采访、通义实验室负责人周靖人对开源大模型的战略意义:首先,作为核心生产要素,开源可以加速其普及,促进产业快速发展;其次,开源已经成为大模型创新的重要动力。
可预见:国内大型模型的落地方向将更贴近实际应用,而不仅仅是实验室模型的竞争。它还为开源大模型的参数值效率、推理成本提供了更加激烈的竞争区域。
本文来自微信微信官方账号“直接面对AI”,作者:涯山,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com