
中国科技大学ICLR2025:具体领域只使用5%的训练数据,提高了14%的知识精度。






使大语言模型更好地了解特定领域的知识,有新的聘用!
王杰教授团队来自中国科技大学MIRA实验室,提出了一个创新的框架。——微调知识图谱驱动的监督管理(KG-SFT),这个框架通过引入知识图谱通过引入(KG)改进大语言模型(LLMs)了解和处理特定领域的知识。
实验结果表明,它在多个领域和多语种的数据集中取得了显著的效果,ICLR入选成功 2025。

到目前为止,LLMs在常识问答方面的表现越来越好,但是他们对领域知识的理解和推理能力仍然有限。
由于很难深刻理解行业问答背后复杂的知识和逻辑关系,在面对这类问题时,通常无法准确地给出正确的答案和详细的推理过程,这极大地限制了其在专业领域的实用价值。
尤其在数据稀缺、知识密集的场景中,怎样使LLMs更好地理解和操纵知识,成为研究的关键。。
而且中科大MIRA实验室的这项工作就是围绕这一点进行的。
KG-SFT是怎样工作的?
KG-对于LLMs来说,SFT无法理解领域问答背后的知识和逻辑,导致推理能力弱提出问题基于知识图谱增强的大语言模型监管微调技术。
KG-首先,SFT通过分析领域知识地图中的多条推理路径,设计了地图上推理路径与文本推理过程的结合生成机制。在监管和微调过程中,LLMs可以同步导出推理答案和包含丰富领域知识和逻辑关系的推理过程,从而提高其理解和推理领域知识的能力。
KG-SFT框架的核心是通过生成问答背后逻辑严密的推理过程解释,将知识地图与监督微调相结合,提高LLMs对知识和逻辑的理解。
这个框架包括三个关键部件:
- Extractor(提取器)
- Generator(生成器)
- Detector(检测器)

1、Extractor:准确提取知识关联
首先,Extractor对问答是正确的。(Q&A)实体自动识别,并从外部知识图谱中获取相关推理子图。
这个步骤揭示了Q&A背后的知识联系和逻辑,为后续的解释生成提供了基础。
命名实体识别(NER)通过搜索多条推理路径,Extractor可以有效地从大规模的知识图谱中获得与问题相关的知识。
2、Generator:生成流畅的解释
Generator利用图形结构重要性评分算法(例如HITS算法)对推理子图中的实体和关系进行评分,选择高分作为重要内容。
接着,使用ChatGPT等大型语言模型生成流畅的解释文稿。
这一解释不仅逻辑清晰,而且能帮助LLMs更好地理解问题与答案的关系。
3、Detector:确保解释的准确性
Detector测试了句子级别的知识冲突,以确保解释的准确性。
自然语言推理(NLI)Detector可以标记和纠正模型(如DeBERTa)和重新引导机制中可能出现的知识矛盾,从而提高解释的稳定性。
试验结论和创新点
试验结果表明,KG-SFT在多个领域和语言设置方面都取得了显著的性能提升。
特别是在低数据医学问答任务中,KG-SFT与传统方法相比,在英语场景中仅使用5%的训练数据提高了近14%的准确率。。
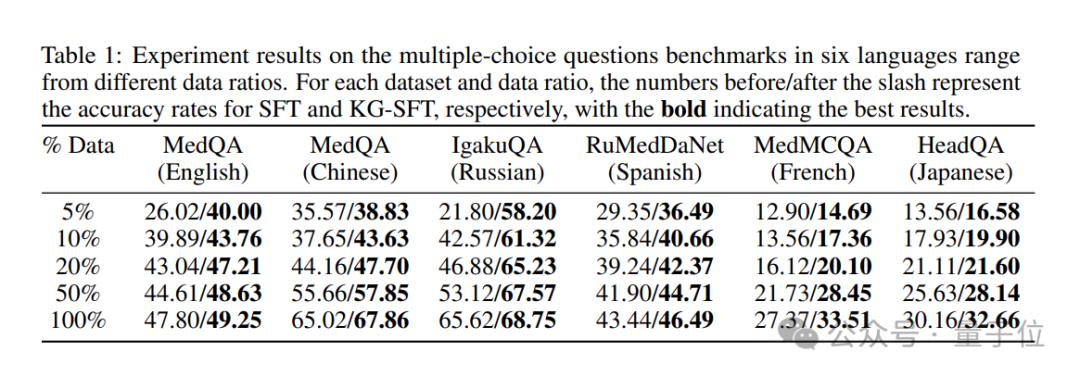
就创新而言,KG-SFT不仅注重数据的总数,而且注重数据的质量。
生成高质量的解释,KG-SFT帮助LLMs更好地理解和操纵知识,从而在特定领域实现更好的性能。
此外,KG-SFT也可以与现有的数据增强方法相结合,作为插件模块,进一步提高性能。
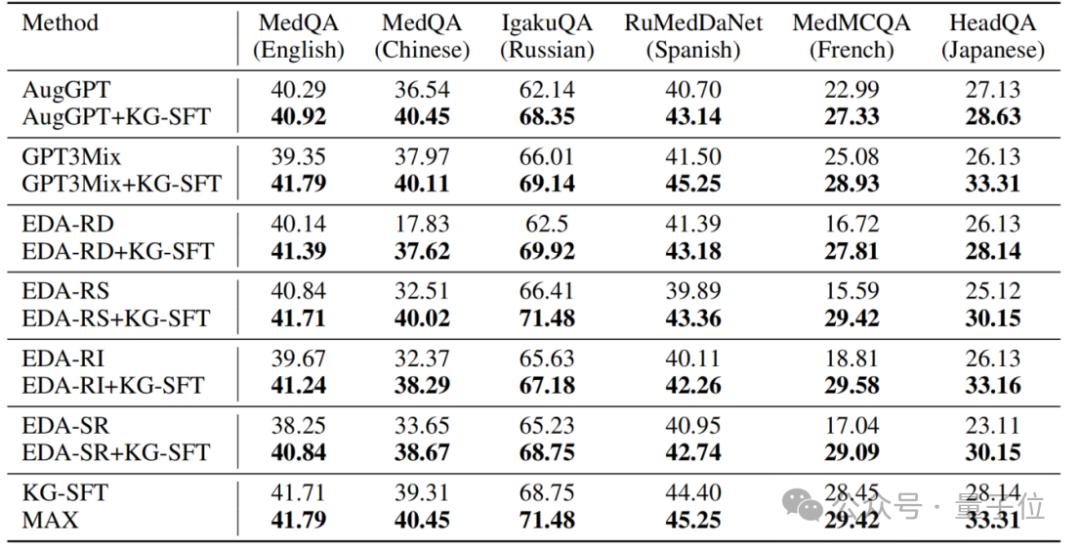
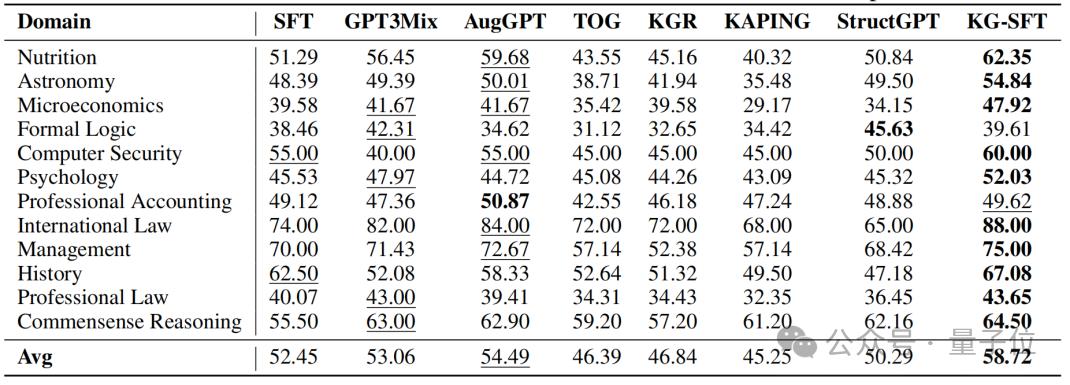
KG-SFT在多领域数据实验结论中的广泛应用得到了进一步验证。
尽管在一些需要复杂推理的行业(如形式逻辑和专业会计)中表现稍逊一筹,但综合表现仍具有较强的竞争力。
归纳而言,KG-通过结合知识图谱和LLMs,SFT框架有效地提高了监管微调数据的质量,从而显著提高了LLMs在特定领域的性能。
这种方法不仅在低数据场景中表现出色,而且显示出它作为插件模块与当前数据增强方法相结合的潜力。
作者第一作者论文陈瀚铸作为中国科技大学2021级硕士研究生,师从王杰教授,主要研究方向是生成大语言模型、知识图谱和推理数据。
有关详细信息,请参阅原文。
论文地址:https://openreview.net/pdf?id=oMFOKjwaRS
本文来自微信微信官方账号“量子位”,作者:KG-36氪经授权发布的SFT团队。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com