
使大型模型训练更加高效,奇异摩尔利用互联网创新方案定义下一代AI计算





电子爱好者网报道(文章 / 最近一段时间,吴子鹏,DeepSeek 卓越的爆红引起了行业对大规模数据中心建设的探索和争议。在练习端,DeepSeek 通过算法优化(如稀疏计算、动态结构)开源模型,降低了培训成本,使企业能够低成本实现高性能。 AI 大型练习;在推理端,DeepSeek 加快了 AI 应用程序从训练转向推理阶段。所以,有观点认为,DeepSeek 未来计算能力的需求将会放缓。然而,国内外更多的机构和研究报告认为,DeepSeek 减少了 AI 应用门槛,将加速 AI 大型应用落地,吸引更多企业进入这条赛道,计算能力需求将继续增长,但需求重点将从“单卡峰值性能”转变为“集群能效提升”。例如,SemiAnalysis 预计全球数据中心的容量将在 2023 年 49GW 增长至 2026 年 新建智算中心容量将占96GW的增加。 85%。最近,世界四大巨头(Meta、发布的亚马逊、微软和) 2025 AI 基础设施支出总额超过 3000 与亿美元相比 2024 年增加 30%。
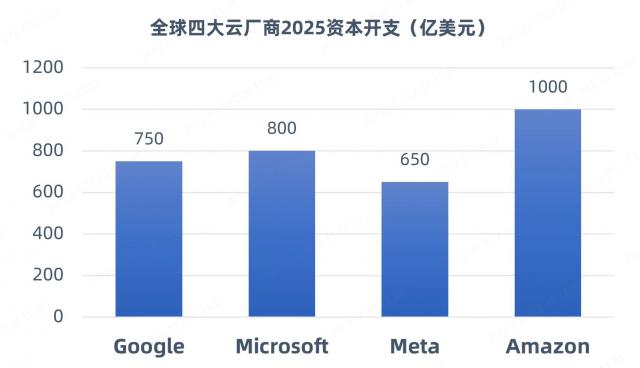
(资料来源:科技巨头公开披露报告)
奇怪的摩尔创始人兼 CEO “田陌晨说:” Scaling Law 仍在继续。从 Transformer 引领风骚到了 MoE 创新突破专家模型,AI 该领域正在向万亿甚至十万亿参数规模迈进。 AI 大型训练时代。DeepSeek-R1 没有基础模型,推理模型的出现是不可或缺的 Deepseek-V3 巨大的训练积累。强大的算率集群仍然是这种背景下的支撑。 AI 的基石。而且如何提高集群的线性加速比,一直是行业的核心话题。与此同时,AI 计算网络的重要性日益突出,它使数据能够在集中的各个层次、各个维度上快速传输,实现各节点资源的高效激发。"

(图片:奇异摩尔创始人兼兼 CEO 田陌晨)
所以,作为行业领先的行业 AI 基于高性能的网络全栈互联产品和解决方案提供商,奇异摩尔提供了一套极具竞争力的解决方案。 RDMA 和 Chiplet 运用“技术” Scale Out "" Scale Up "" Scale Inside "三个概念,提高网络、片间、片中算率基础设施的传输效率,赋能智能计算率发展。
Scale Out ——打破系统传输瓶颈
DeepSeek 成功证明,与闭源模型相比,开源模型具有一定的优势。随着模型智能化趋势的演变,模型量的增加仍将是行业发展的主要趋势之一。为完成千亿、万亿参数的规模 AI 大型训练任务,通用做法一般都会采用 Tensor 并行(TP)、Pipeline 并行(PP)、和 Data 并行(DP)对训练任务进行策略拆分。随着 MoE(Mixture of Experts,混合专家)模型的出现不仅涉及上述并行策略,还引入了专家并行。 ( EP ) 。其中,EP 和 TP 通讯数据费用较高,主要是通过 Scale Up 应对互联网的方式。DP 和 PP 并行计算的通信费用比较小,主要是通过 Scale Out 应对互联网的方式。
所以,如图所示,目前主流万卡集群中有两个因特网领域。—— GPU 朝南 Scale Up 互联域(Scale Up Domain,SUD)和 GPU 朝北 Scale Out 互联域(Scale Out Domain,SOD)。田陌晨强调:“以 Scale Up 和 Scale Out 双引擎驱动形式构建大规模、高效率的智算集群,是应对计算能力需求爆发的有效手段。"
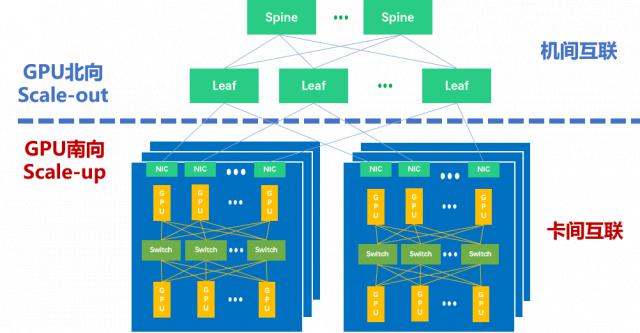
在智算集群中 Scale Up 和 Scale Out
这是一个集群网络,Scale Out 致力于横着 / 扩大标准,强调通过增加更多的计算节点来扩大集群规模。目前,远程直接内存浏览(RDMA)已成为建筑 Scale Out 主流的网络选择。作为一种 host-offload/host-bypass 技术,RDMA 它提供了从一个计算机内存到另一个计算机内存的直接访问,具有延迟低、带宽高的特点,在大规模集群中发挥着重要作用。如图所示,RDMA 主要包括u200c InfiniBand(IB)、以以太网为基础 RoCE 和基于 TCP/IP 的 iWARP u200c。其中,IB 和以太网 RDMA 它是计算集群中应用最广泛的技术。
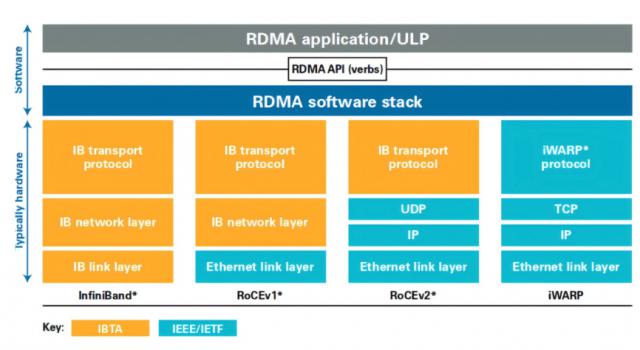
RDMA 应用与实现方式(来源:知乎 @Savir)
IB 是专门为 RDMA 开发的一种网络通信技术,具有高带宽、低延迟等优点, IB 默认为无损网络,无需特殊设置。得益于这些优点,过去 IB 在 Scale Out 在网络建设中占主导地位。然而,IB 网卡和交换机需要特别支持这项技术,价格是传统网络。 5-10 倍数,成本比较高,而且 IB 交换机交换时间较长。同时,IB 兼容性差,难以与网卡、电缆、交换机、路由器等大多数以太网设备相适应,不能成为行业统一的发展路线。
随著集群规模的增加,以太网 RDMA 得到了主流厂商的广泛支持。以太网 RDMA 它还具有高速率,高带宽,CPU 低负荷等优点,在低延迟和无损网络特性方面也已跟随 IB 性能持平。同时,以太网 RDMA 具有较好的开放性、兼容性和统一性,更有利于大规模的网络集群。就某些行业代表案例而言,如万卡集群字节跳动,Meta 公司数以万计的卡集群,以及特斯拉希望建立的十万卡集群,都一致选择了以太网计划。另外,由于硬件通用和操作简单,以太网 RDMA 该方案更具性价比。
尽管以太网 RDMA 已被公认为未来 Scale Out 大趋势,但田陌晨指出:“如果是基于这样的话。 RoCEv2 建设方案仍然存在一些问题,如乱序需要重传,负载分担不完善,存在一些问题。 Go-back-N 问题,以及 DCQCN 部署调优复杂等。行业需要加强型以太网,在万卡和十万卡集群中。 RDMA 为了应对上述挑战,超以太网传输 ( Ultra Ethernet Transport,UET ) 就是下一代 AI 运算 HPC 核心技术内部。"
为能进一步发挥以太网和 RDMA 博通,思科,技术潜力,Arista、微软、Meta 等待公司牵头成立超以太网联盟(UEC)。如图所示,现在 UEC 规范 1.0 在浏览版中,UEC 从软件 API、在运输层、链路层、网络安全和拥堵控制等方面 Transport Layer 对传输层进行了全面优化,包括关键功能 FEC(前向纠错)统计,链路层重传递(LLR)、多路报纸爆发,新一代拥堵控制,灵活排序,端到端监控,交换机卸载等。根据 AMD 数据的各个方面,UEC 就绪(UEC-ready)系统可以提供比传统 RoCEv2 系统高出 5-6 倍的性能。
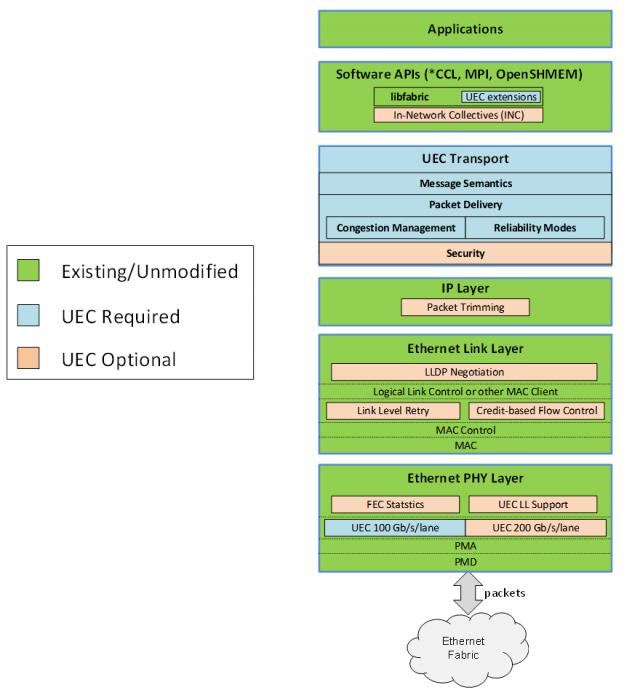
UEC 规范 1.0 图表(来源:UEC)
田陌晨说:" UEC 是专门为 AI 网络 Scale Out 通过因特网建立的国际联盟,致力于通过 Modernized RDMA 提升 AI 和 HPC 工作负载。借助 UEC 关键性能,Scale Out 网络可以充分利用系统中所有可用的传输路径,最大限度地减少网络拥堵。当前基于 RDMA RoCE 未来的解决方案也可以通过实践来实践。 UEC 联盟标准升级了各自的以太网产品计划,创造了更大规模的无损集群通信。"
奇怪的摩尔制造的 Kiwi NDSA-SNIC AI 原生智能网卡是一种 UEC 准备方案,性能堪比全球标杆 ASIC 商品。Kiwi NDSA SmartNIC 为领先行业提供高性能,支持高达 800Gbps 提供低至低的传输带宽 μ s 一级数据传输延迟,满足当前数据中心产业的需求 400Gbps-800Gbps 升级需求,可以实现 Tb 万卡集群之间无损数据传输。

奇异摩尔 Kiwi NDSA-SNIC AI 原生智能网卡计划(来源:奇异摩尔)
借助 UEC 就绪 RDMA 路径感知拥塞控制、有序消息传递、选择性确定重传、自适应路由、数据包喷洒等关键功能,Kiwi NDSA-SNIC 能全面保证 AI 平稳地传输网络间数据。例如,Kiwi NDSA-SNIC 提供的自适应路由和数据包喷洒功能可以充分发挥高速网络的性能,支持高级分组喷洒,提供多路径数据包传输和粗粒度负载平衡,有效应对传输拥堵。同样的用例还包括:通过有序消息传递(In-Order Message Delivery)通过路径感知拥塞控制,减少系统延迟(Path Aware Congestion Control)对多条路径的数据包流进行优化等。
此外,Kiwi NDSA-SNIC 还有许多其他的关键特征。例如,Kiwi NDSA-SNIC 它具有优异的高并发特性,支持数百万个序列对,可扩展的存储空间达到 GB;Kiwi NDSA-SNIC 具有可编程性,可以面对各种网络任务加速, Scale Out 互联网带来了不断创新的功能,并保证与未来的行业标准无缝适应。
总的来说,奇怪的摩尔 Kiwi NDSA-SNIC AI 本地智能网卡是一种高性能、可编程的网卡。 Scale Out 网络引擎,将打开 AI 网络 Scale Out 新的发展篇章。田陌晨说:“目前,奇异摩尔已成为 UEC 联盟成员。由于以太网逐渐过渡到超以太网,奇异摩尔愿意与联盟合作伙伴深入探讨和实践。 Scale Out 制定和完善相关标准,并在第一时间为行业带来领先的性能。 UEC 方案,推动 AI 网络 Scale Out 技术向前发展。"

奇异摩尔 UEC 会员(来源:UEC 官网)
Scale Up ——使计算芯片配合更加高效
和横向 / 水平扩展的 Scale Out 不同,Scale Up 是竖直 / 向上扩展,目标是打造机内高带宽互联的超级节点。上述提及,TP 张量并行和 EP 在整体同步中,专家需要更高的带宽和更低的延迟。通过 Scale Up 更多的算率芯片方法, GPU 集中在一个节点上,是一种非常有效的应对方式。如今的 Scale Up 事实上,它是一种以超高带宽为核心的机器。 GPU-GPU 组网方式,还有一个名字叫超带宽域。(HBD,High Bandwidth Domain)。
英伟达 GB200 NVL72 它的推出促进了国内外 AI 网络生态对 HBD 广泛讨论技术。英伟达 GB200NVL72 服务器是典型的超大型服务器。 HBD,完成了 36 组 GB200(36 个 Grace CPU,72 个 B200 GPU)超高带宽相互连接。在这个 HBD 第五代在系统中 NVLink 这是最重要的,它能提供 GPU-GPU 之间双向 1.8TB 传输速度,使这一传输速度 HBD 该系统可作为一个大型系统 GPU 使用时,训练效率比较 H100 系统提高了 4 倍,能效提高了 25 倍。
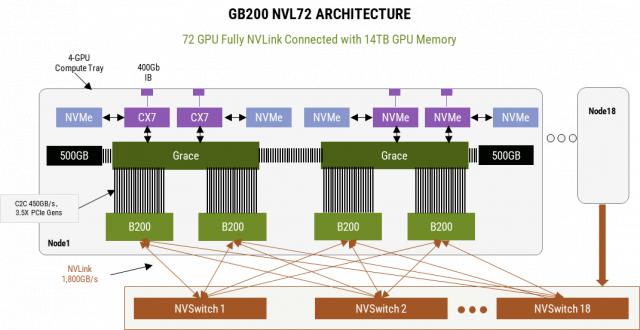
NVL72 互联架构 ( 来源:英伟达 )
和 IB 一样,NVLink 同时也是由英伟达主导,虽然性能强劲但生态封闭,仅为英伟达高端服务。 GPU。因为没有 NVLink 和 NVSwitch 以前其它厂家主要采用这种技术, full mesh 或是 cube-mesh 构造,以 8 卡片互联是主要的,而且 16-32 卡片互联是下一代的计划。
DeepSeek 这一事件引起了业界的关注。 NVLink 和 HBD 不同的需求预期。但是从中长期发展的角度来看,与软件迭代速度相比,硬件迭代速度是以年为单位,从浅入深,不会一蹴而就。据 SemiAnalysis 随着未来模型的发布,预计大型模型的标准将继续上升,但从经济效用的角度来看,相应的硬件必须持续有效地使用。 4-6 一年,而不仅仅是直到下一个模型发布。
对于这一点,田陌晨感觉:“未来 MoE 在一定程度上,模型高级路线存在不确定性,创新随时可能发生。但国产 AI 网络生态闭环势在必行。英伟达 NVLink 和 Cuda 环城河依然存在,首先要解决 Scale Up 因特网国内替代方案是否存在问题,再看看做到了什么程度。未来,随着国内大模型、芯片架构等软硬件生态的协同发展,国内计算率闭环有望逐步实现。"
现在,科技巨头正在联合上下游生态。 GPU-GPU 高效率的互联网主要分为内存语义和消息语义两个派系。内存语义 Load/Store/Atomic 是 GPU 内部总线传递的原始语义,英伟达 NVLink 以内存语义为基础,对比 NVLink 的 UAlink 等待也是基于这个语义;消息的语义是采用类似的语义。 Scale Out 的 DMA 语义 Send/Read/Write,包装和传输数据,亚马逊和 Tenstorrent 等待公司是建立在消息语义基础上的。 Scale Up 互联方案。
记忆语义和消息语义各有千秋。记忆语义是 GPU 内部传输的原始语义,Cpu负担较小,在数据包规模小时内效率更高;消息语义采用数据包装的方式。随着数据包容量的增加,性能逐渐赶上内存语义,随着数据包容量的增加, AI 增加大型模型的规模也很重要。
然而,田陌晨指出:“对于厂商来说,无论是内存语义还是新闻语义,都面临着一些共同的挑战,比如传统。 GPU 直出将 IO 集成在 GPU 内部,性能提升受到光罩尺寸的严格控制,留给光罩尺寸 IO 空间非常有限,IO 难以提高密度;Scale Up 网络化和数据传输协议复杂,计算芯片制造商大多缺乏相关经验,尤其是开发交换机芯片的经验; NVLink 以外,其他 Scale Up 协议不成熟、不统一,协议迭代给计算芯片迭代带来了极大的困扰。"
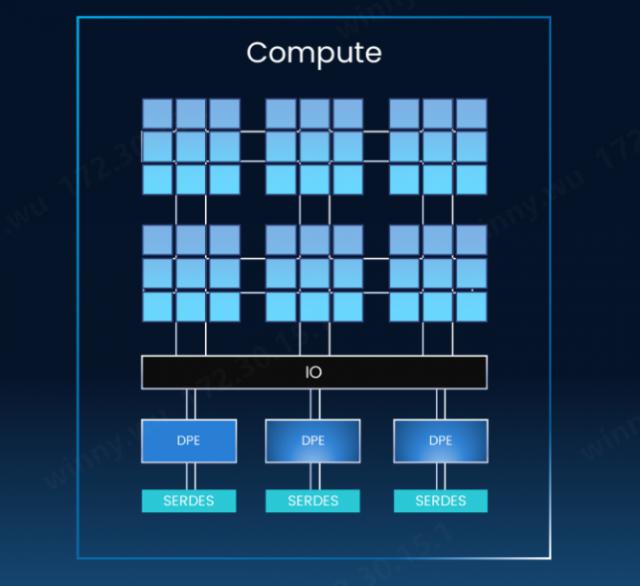
GPU IO 集成在 GPU 内部(来源:奇异摩尔)
为更好地应对上述挑战,工业界提出了一种创新的方法。 GPU 直截了当的方法-运算 IO 分开。奇怪的摩尔 NDSA-G2G 在这条技术路径上,互联方案是一个很有竞争力的方案。
借助 NDSA-G2G 能实现芯粒计算和计算 IO 通过通用芯粒互联技术解耦芯粒。 UCIe 进行互联。这样做的好处是,只需要牺牲一点点芯片面积(小百分之几),就可以将珍贵的中介资源接近 100% 用于计算,并根据客户的需求灵活增加 IO 芯粒总数,并计算芯粒和 IO 基于不同的生产工艺,可以使用芯粒。加上 IO 芯片的复用特性,能显著提高高性能计算芯片的性能和性价比。
NDSA-G2G 第二个优点是提高 IO 具有高带宽、低延迟和高并发性能的密度和性能。就高带宽而言,基于 NDSA-G2G 可以实现芯粒 1TB 传输层等级的吞吐量,TB 级的 GPU 侧吞吐量;低延迟方面,NDSA-G2G 芯粒提供百 ns 等级数据传输延迟和 ns 级 D2D 数据传输延迟;在高并发方面,该产品支持数百万个序列对,可以扩展系统中的内存资源。换言之,借助奇异摩尔 NDSA-G2G 颗粒能赋能国产产品 AI 实现芯片自主突破,构建性能堪比英伟达 NVSwitch NVLink 的 Scale Up 方案。

Kiwi NDSA-G2G 产品示意图(来源:奇异摩尔)
NDSA-G2G 其三大优点是灵活性极佳。如上所述,现在 Scale Up 技术性路线不统一,而且智算中心厂商在协议上多采用自己的协议,或者是自己主导的联盟协议。这样就使得高性能计算芯片在设计过程中需要考虑未来。 2~3 年,甚至是 3~5 年度协议的发展,具有很大的挑战。NDSA-G2G 用来计算芯粒和 IO 让芯粒分离的方法 IO 可灵活升级芯粒, NASG-G2G 基于可编程性,可以支持目前市场上的各种类型 IO 协议。这种灵活性使得高性能计算芯片制造商能够坦然面对当前的现状 Scale Up 技术线不统一,协议混乱的挑战。
与此同时,田陌晨也呼吁:“希望科技产业在 Scale Up 在方向上可以拥抱一个开放统一的物理接口,实现更好的协同发展,这也是建立国内自主可控率基础的关键一步。"
Scale Inside ——全面提高计算芯片传输效率
在 Scale Out 和 Scale Up 作为计算率基础模块,在快速发展的过程中,Scale Inside 此外,我们还致力于通过先进的封装技术来填补摩尔定律速度放缓的影响。更高计算能力的计算芯片可以在整个智算系统中进一步提高。 Scale Up 和 Scale Out 性能水平,促进 AI 大模练习效率更高。
目前,单个高性能计算芯片的成本已经很可怕了,随着工艺的进一步完善,这个数字还会继续飙升,所以 Chiplet 技术得到了广泛的重视。Chiplet 通过混合封装,技术可以创建高性能的计算芯片,换句话说,计算单元和 IO、其他功能模块,如存储,可以通过不同的工艺实现,具有很高的灵活性。厂家可以根据自己的需求定制芯片,不仅可以显著降低芯片设计制造成本,还可以大大提高良率。
在 Scale Inside 从方向上看,奇异摩尔能提供丰富的 Chiplet 包括技术规范 Kiwi Link UCIe Die2Die 接口 IP、Central IO Die,3D Base Die 系列等。其中,Kiwi Link 全系列支持 UCIe 标准化,具有行业领先的高带宽、低功耗、低延迟特性,并提供多种封装类型。Kiwi Link 支持高达 16~32 GT/s 传输速度和低至 ns 等级传输延迟,支持 Multi-Protocol 包括多个协议 PCIe、CXL 和 Streaming。
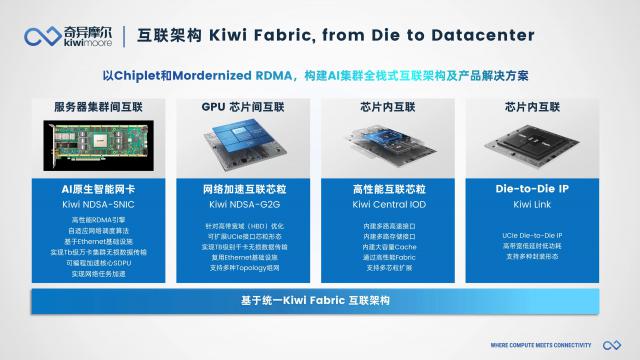
Kiwi Fabric 因特网结构(来源:奇异摩尔)
总的来说,奇异摩尔的解决方案可以从“ Scale Out "" Scale Up "" Scale Inside “三个视角,推进 AI 大型训练效率的提高。在 Scale Out 另一另一方面,奇异摩尔已经是超以太网联盟。 UEC 成员,能在第一时间做出反应 UEC 规范 1.0 以及后续规范;是的 Scale Up 另一方面,奇异摩尔 NDSA-G2G 不仅可以帮助科技公司打造与英伟达达相媲美的芯片。 NVSwitch NVLink 特性的 Scale Up 方案,适应各种技术路线和协议,也促进了计算芯片的设计创新; Scale Inside 计划,奇怪的摩尔 Kiwi Link UCIe Die2Die 接口 IP、Central IO Die、3D Base Die 该系列可以帮助制造商创建高性能的计算芯片,具有高效的传输能力。
这一方案更好地执行了奇异摩尔公司的使命——以互联为中心,依靠 Chiplet 和 RDMA 技术,构建 AI 高性能计算的基石。对于国产 AI 大型和国产 AI 对于芯片行业来说,奇异摩尔的方案是新生产力的代表,潜力更大,值得挖掘。为了实现国内生产 AI 芯片产业的“中国梦”,除了提供支持前沿协议之外,奇异摩尔 IO 为了实现高速、高带宽、低延迟的传输性能,芯粒仍然存在。 Chiplet 在路线上另辟蹊径,借助创新的芯片架构,帮助创造更高性能。 AI 芯片。奇异摩尔愿与国内公司携手,为国产企业 AI 芯片产业的发展,共同勾勒出国产产业的发展。 AI 广阔的发展蓝图。”田陌晨最后说。
更多信息:
市场联系媒体:marcom@kiwimoore.com
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com