
在DeepSeek的冲击下,大模型六小强怎么样?「回应」?





马上整整一个月!
这个月到现在,DeepSeek搅拌了全球大模型市场,没有一个大混乱。。
大型中外厂商和创业公司都是秃头,都被追着问:你觉得DeepSeek怎么样?DeepSeek出来大家怎么办?
有些人避而不谈,有些人主动回应。
国内,例如腾讯,昨天刚在微信上打开灰度测试“AI搜索”功能,接入的是DeepSeek-R1;例如百度,四月份马上宣布文心一言免费,下一代文心模型决定开源…
海外,比如OpenAI,紧急发布o3-mini、上新深度搜索,公开o3思维链;比如谷歌DeepMind,新发布的Geminini 2.0系列,Geminini新模型 2.0 Flash-Lite,它的API砍价能力比DeepSeek还要狠;
但是,就在全球AI大模式格局重塑的时候,放眼国内,很多人还是非常关注一件事:
六家大型创业公司已经成为独角兽,零一万物,百川智能,阶跃星辰,智谱华章,月亮暗面,MiniMax江湖人称大模型六小强。
他们是如何应对DeepSeek的猛烈冲击波的?
在冲击下,六小强有什么“回应”?
六小强中,没有一个人站出来,正面表达对DeepSeek的看法。
但是,这并不意味着他们没有行动——毕竟,与高谈阔论相比,落地的实际行动更值得证实。
注意:以下都是六小强1月20日(含)后的动态动态。
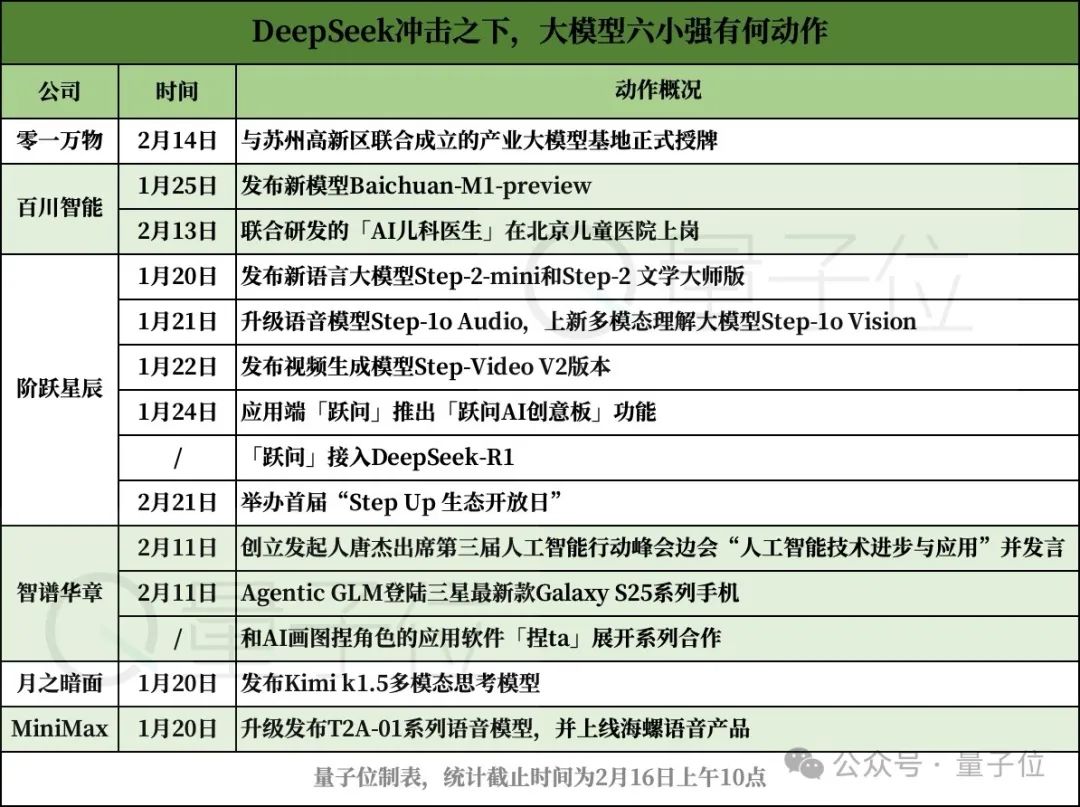
零一万物
DeepSeek-在R1出现之前,创始人李开复博士已经明确表示,零一万物将不再追求超大的训练模式。
经过半年多的探索和验证,他们明确表示,参数适中、性能优越、推理速度快、推理成本低的轻量化模型更适合商业场景,“它将成为AI-First应用程序爆发的催化剂”。
而且DeepSeek出现后,零一万物对外曝光的第一个动作,选择与苏州携手。——
二月十四日,零一万物与苏州高新区联合成立的行业大模型基地正式授牌。
该大模型基地聚焦垂直产业,聚焦制造、金融、医疗、政务、生物、身体等多个领域的行业大模型解决方案。联合产业链上下7家企业,“探索大模型技术从实验室走向生产线的产业化路径”。
在现场,李开复表示,在人工智能技术重构行业的关键节点,大模型绝不是“空中楼阁”,而是驱动实体经济的核心引擎。

而且零一万物官方表示:
继1月2日与阿里云联合成立“工业大模型联合实验室”之后,零一万物再次落地于工业大模型方向。这次在苏州高新区落地“工业大模型基地”,进一步加快了零一万物模型能力的商业落地进程。
百川智能
DeepSeek-5天后,R1发布,一月二十五日,百川智能发布Baichuan-M1新模型-preview。
这个模型是百川第一个全场景推理模型。所谓全场景,就是这个模型同时具有三个领域的推理能力:语言、视觉和搜索。
同时,百川仍在走向医疗转型的道路:
Baichuan-M1-preview解锁了医疗循证模式,官方解释说“实现了从医疗证据检索到深度推理的完整端到端服务,可以快速准确地回答医疗临床和科研问题”。
二月十三日,基于Baichuan-M1的底座「儿科医生AI」经过一个月的内测,在京“上岗”。
对于临床推理,首先会根据一诉五史生成诊断和治疗假设,然后通过检查和检查信息进行假设和排除,最后通过自我反思机制对剩余假设进行概率排序,导出符合临床思维路径的诊断和治疗建议。
官方公告显示,当天,北京儿童医院首次推出国内“儿科医生AI” “多学科专家”双医并行多学科会诊。除了多学科13位专家外,该医院还与百川智能、儿童健康技术(这家医疗数据企业在百川投资)联合开发了该医院「儿科医生AI」。
与会者对一名颅底肿块伴有鼻炎症状的儿童进行了多学科会诊,另一方面,工程师将病人的主诉和病历输入模型。
AI儿科医师还提出了与专家团会诊结果高度一致的意见。

阶跃星辰
DeepSeek-在R1发布当天,阶跃星辰正处于模型上的新过程中。
一月二十日发布的两个模型都是语言模型。,一款Step-2,重量轻,响应快,性价比高。-mini,相对于自己的模型玩意参数Step-2,Step-在3%左右的参数中,2-mini的性能保持在80%以上。
另外一个是Step-2 “专为创作而生”的文学大师版。
在接下来的两天里,阶跃继续保持对外发布的节奏。
Step-1o升级语音模型。 Audio,更新的多模式理解大模型Step-1o Vision。在发布公测之后,后者冲到了大型试炼场前10名,在视觉领域位居国内第一。
22日,视频生成模型Step发布。-Video V2版本,该版本基于前代V1,从VAE模型、DiT架构与RL结合、多模态大模型应用三个方面进行升级。

模型侧更新外,阶跃星辰的应用「跃问」一月二十四日还推出了全新的功能,跃问AI创意板。
它的作用是“在3步内实现想法,开发应用,无需代码”,并在整个平台上共享结果。
BTW,发现量子位,不知道什么时候跳问已经偷偷接入了DeepSeek-R1…

还有农历新年前频繁动作的时候,阶跃星辰系统负责人朱亦博在朋友圈里做了一个小剧透,年后阶跃有了大动作。
而且“大动作”本身,也许会第一届“二月二十一日阶跃星辰”Step Up “生态开放日”上面公布了。是否有针对DeepSeek-R1的回复动作或策略,也要等到下周的会议才能看到。
智谱华章
2月11日,清华大学计算机系教授、智谱创始人唐杰在巴黎大王宫举行的第三届人工智能行动峰会上发表了“人工智能技术进步与应用”讲话。
同时也是唯一一位参加这次峰会的大型代表。
唐杰在阐述了AGI的五个阶段划分后,表示现在正处于L2和L3的交界处,即“与机器和人类的意图对齐”和“机器自学”的交界处。
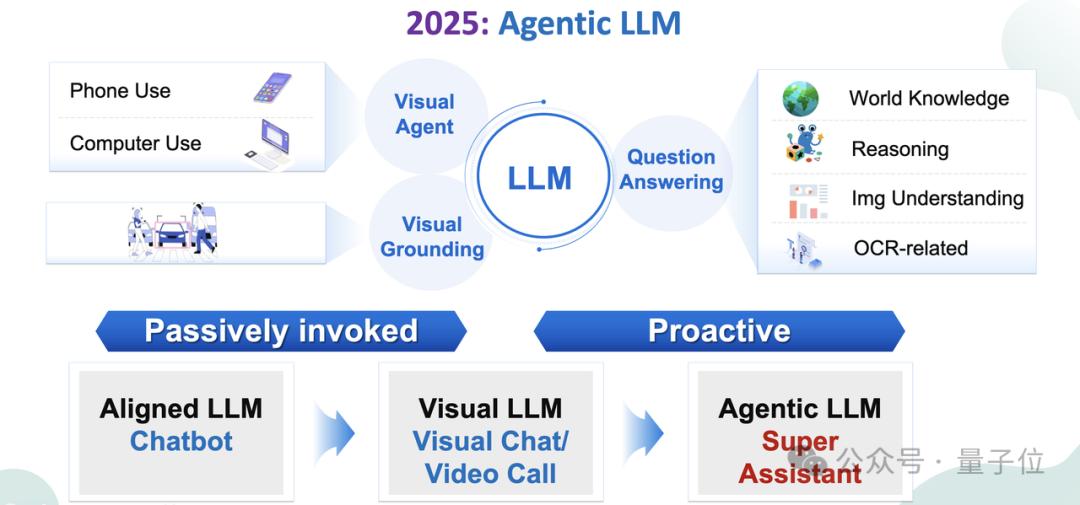
而且2025年的关键字,部分摘录如下:
具有Agent能力的自主大型语言模型(Agentic LLMs)它将成为日常生活和工作的核心。
通过给出高层次的目标,独立的LLMs将制定计划,使用数字设备并实施复杂的项目,而人类需要的干扰很少。
这类自主系统不再仅仅是一个独立的实体,而是协调工作,互补优势,更有效地完成任务。
另外,面对DeepSeek搅动风云,在开年时,智谱的“回应”得到了更多的实施。
首先是二月十一日,继续与三星合作。
让Agentic主要表现为 GLM登陆三星新款Galaxyyy新款Galaxyy(智谱专为手机开发的系统级大模型) S25系列手机提供基于AI的实时语音和视频聊天,实现视觉理解和系统功能调用、AI搜索、文案写作等功能。
(这里确实与当天唐杰演讲的部分内容相照应)
第二,注意量子位,虽然没有正式宣布,但智谱最近悄然开始了AI绘图捏人物的应用软件,二次元非常流行。「捏ta」展开合作。
另一方面,智谱在自己的视频模型中推出捏ta。;另外,基于智谱的CogVideoX-2模型等,两家公司在涅ta推出联名活动。
月之暗面
你们说巧不巧?DeepSeek-R1发布一个半小时后,月亮暗面官方公众号宣布其Kimi k1.5多模态思维模式。
相关论文《Kimi k1.5:Scaling Reinforcement Learning With LLMs》中显示,k1.模型设计与训练有几个核心要素:
进行长前后文。
k1.5队将RL的前后文窗口扩展到128k,其背后的一个关键想法是使用部分。(partial rollouts)提高训练效率。
改进战略优化。
k1.5团队推导了long-CoT的RL公式,并采用在线镜像下降的组合,对策略进行稳定优化。
简洁框架。
以上两者的结合为LLMs学习简历提供了一个简单的RL框架,从而在不依赖蒙特卡洛树搜索、价值函数和过程奖励模型的情况下实现更强的性能。
多模态能力。
也就是说,它有两种模式:联合推理文本和视觉。
OpenAI展示o3于2月12日轻松获得IOI。 在最新的2024金牌报告论文中,介绍部分提到了。DeepSeek-R1和Kimi k1.通过CoT,可以提高大模型在数学和编程方面的性能。

MiniMax
现在回头看看1月20日,真是神仙打架热闹非凡。——
同一天,MiniMax也有一个新的模型。
T2A-01系列语音模型升级发布,海螺语音产品上线。(同样考虑到模型和产品的推广)。
T2A-T2A-01系列包括-HD、T2A-两个模型:01-Turbo,API服务同步推出MiniMax开放平台。该系列模型支持17种语言和数百种预设音质。
依托这一系列模型,在海螺AI中,客户只需输入文字即可生成自然流畅的超拟人声,最多可输入1万字。并且可以根据需要自由配备情绪、语速、音准,甚至根据需要调节音质效果。
这里特别提到了1月20日前发生的一件事,那就是1月15日,MiniMax创始人兼CEO闫俊杰对话《晚点》稿件发布,其中MiniMax当时对2025年进行了调整和规划。
首先要做的是“开源”。
若重新选择,应在第一天开源。因为开源可以加速技术进化。
这个问题与MiniMax当天正式宣布MiniMax-01系列模型相呼应,并且发布即开源。
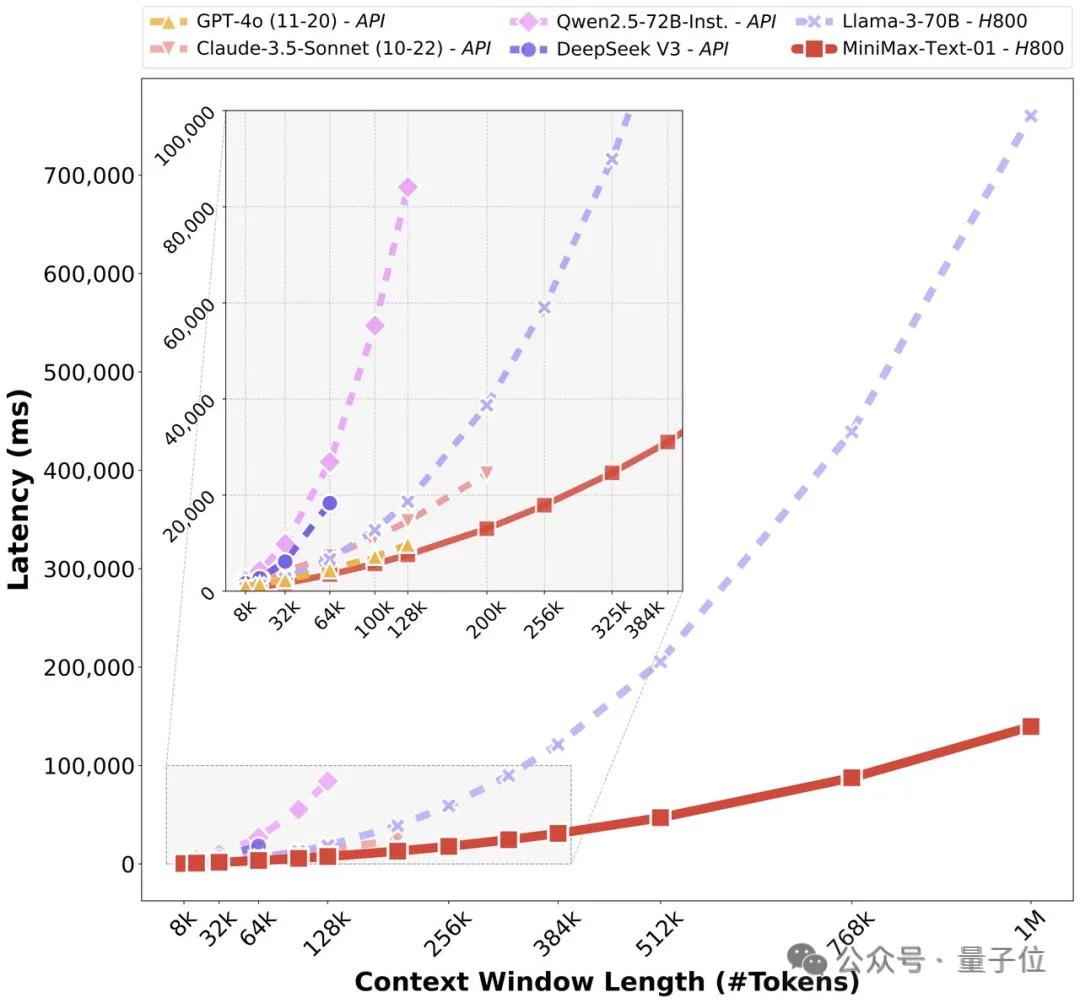
其中,MiniMax-新Lightning首次大规模扩展 取代传统的Transformer架构,Attention架构使模型能够有效地处理4M。 前后文中的token。
综上所述,截至推送,六小强最近的动态如下:
不只是六小强受到了冲击。
当然,这只海底巨鲸DeepSeek这次丢了R1,不只是国内六大模型独角兽的圈子在搅拌。
换言之,放眼国内,受到影响的不仅仅是六小强,没有一家科技巨头或AI大型企业置之度外。
冲击力下有新的角度,新的变化。
比如DeepSeek「大胆利用行业内经验不足的年轻技术人才,将其作为追求突破性技术创新的一环」这个故事,在大街小巷广为人知,再一次询问了每个企业对用人标准的定义。
比如百度在宣布免费宣布文心的消息后,宣布决定背叛闭源大模型——文心大模型4.5系列将在未来几个月陆续推出,从6月30日起正式开源。
当被问及DeepSeek是否可预测时,李彦宏还在最近的迪拜AI峰会上直言:
在我看来,创新是无法规划的。您不知道创新何时何地到来,您所能做的就是创造一个有利于创新的环境。
在冲击下,有了新的发展,新的机遇。
云计算制造商和AI 第一时间在DeepSeekek上线的Infra平台/公司 API,不仅陆续搭载了671B满血版,还争相提高截断率、回复率、准确性等。有的还推出了有利于当地部署的框架,然后打破了大模型推理的门槛。
为了流入大量用户的DeepSeek分流,让更多的用户可以通过不同的渠道使用AI。
另一方面,以腾讯为例,从云平台腾讯云、腾讯云大型知识应用开发平台知识引擎、国民应用微信、AI智能控制台ima、主AI应用元宝全方位拥抱DeepSeek,纷纷宣布接入R1模型,并利用个人能力为其使用体验做出贡献。
而且华为、阿里、字节等大厂商及其应用、团队,也是如此。
他们开放适应,拥抱的不仅仅是DeepSeek,还有最好的客户体验模式——不管是不是“纯自研”。
总而言之,仙人竞技,凡人捡漏,AI普惠,多多益善。

毫无疑问,在搅动的水面上,不只是在国内航行。
从国际上看,DeepSeek的名字已成为华尔街分析师大会上最常被提及的AI企业。
伴随着Alphabet(谷歌母公司)、AMD、Palantir和亚马逊等科技巨头公布了收入,DeepSeek被提及的次数仍在增加。
外国媒体用一句很短的话来形容这个“盛况”:
“DeepSeek, DeepSeek, DeepSeek。”

具体到海外大型玩家身上,面对“DeepSeek冲击波”,有急得跺脚的,也有反思和取精的。
单举一个例子,就能看出顶级巨头对此作出“回应”的态度:
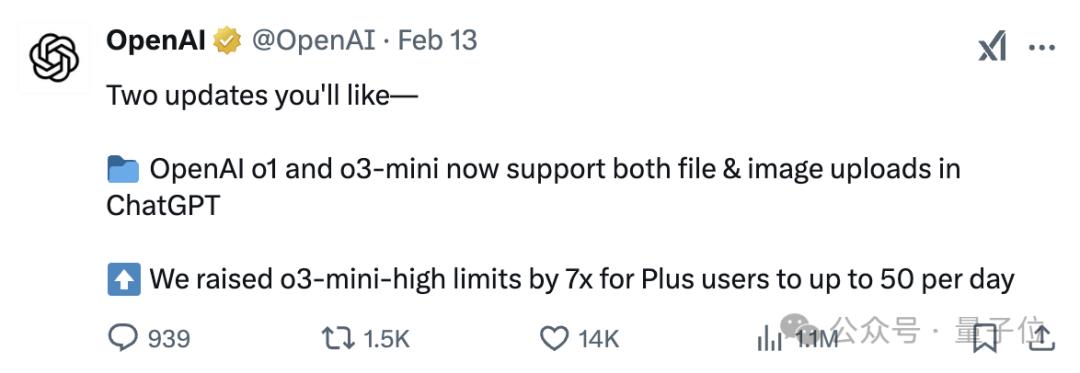
OpenAI,紧急情况下,第一次免费向用户推出推理模型o3-mini,在Reddit“有问题必答”活动中,CEO奥特曼很少公开反思:
关于开源权重AI模型这一问题,(个人认为)我们站在了历史错误的一边。
去年十二月底稳坐高台,拉长战线连续直播12天挤牙膏式游戏消失。
OpenAI现在可以在一天之内继续在GPT-4.5上线,GPT-五个月内出现,还有很多关于模型路线导航调整、现有模型迭代更新的新消息。
但是除了大型跑道之外,DeepSeek冲击带来的影响是什么?——
DeepSeek逢山开道,无数第三方争先恐后地与R1合作。、V3等模型。
根据不完全统计,目前接入DeepSeek模型的第三方包括infra平台、手机制造商、Web/App应用,智驾终端等等,已经超过100个。
在GitHub上,V3/R1的星标数量不断增加,这意味着更多的人可以使用DeepSeek。
后来生态繁荣,源远流长。
从海底巨鲸到AGI更深层次的追寻,留下R1这个深水炮弹后,一个新梗开始在市场上流传。
什么是DeepSeek冲击带来的?
是「一条鲸鱼,万物生」。
本文来自微信微信官方账号“量子位”(ID:QbitAI),作者:衡宇,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com