
O1-mini比o1-preview在北大AI奥数评估中的成绩仍然很高。







OpenAI 的 o1 系列一发布,传统的数学评价标准就显得不够了。
MATH-500,满血版 o1 直接取下模型94.8分。
更难的奥数邀请赛 AIME 2024,o1 也获得83.3%的准确率。
随着现有数学评价集的逐渐突破,人们不禁开始好奇:大模型能否在数学竞赛甚至奥林匹克竞赛中发挥更具挑战性的作用?
所以,北京大学和阿里巴巴的研究小组联合打造了一个奥林匹克评价标准,专门用于数学竞赛。——Omni-MATH。
Omni-MATH 专门用于评价奥林匹克大型语言模型的数学推理能力。评估集包括 4428 道路竞赛级别的问题。这些问题被仔细分类,包括 33 一个(以及更多)子领域,分为 10 各种难度等级的不同,使我们能够对各种数学课程和复杂程度的模型进行详细的分析。

最新排行榜,竞争十分激烈:
除去 o1 血版暂时还没有释放出来。 API,这是一个小模型 o1-mini 表现最佳,均分比 o1-preview 还高 8% 上下。
最好的开源模型是Qwen2-MATH-72b,甚至超过了 GPT-4o 的表现。
总体而言,o1-mini 这一优势只注重少数能力,放弃存储世界知识路线,再一次得到验证。
Omni-MATH:难度大,领域广
Omni-MATH 作为数学奥林匹克评价标准,其特点有三个维度:
人工验证答案的稳定性:4428 评价问题来自不同的数学竞赛和论坛数据,人工参与验证答案的准确性;此外,考虑到奥运会难度问题答案的多样性,它提供了基于 GPT4o 以及评估模型的评估方法,便于一键启动评估。
难度分类明确合理:评价集整体具有挑战性,难度跨越特别大。比赛(T4)来自奥林匹克的准备水平 CEMC 最好的奥林匹克数学竞赛(T0) IMO、IMC、普特南等。这些比赛不仅需要选手有扎实的数学基础,还需要高逻辑推理能力和创造力。数据显示,只有少数智力接近顶尖的人才能在这些比赛中取得优异的成绩。
主题类型很广:共有超过 33 个别领域的数学问题。根据数学领域的特点,团队建立了一个树形的行业分类,每个问题涉及一个或多个领域,即多个树木的路径,使我们能够仔细分析各种数学课程和模型的难度。"
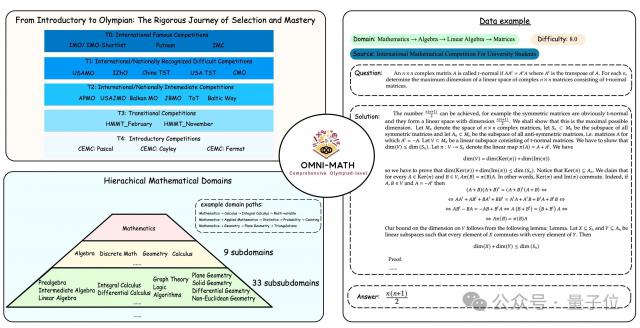
评测集 Omni-MATH 结构数据结构
研究小组首先对国内外基本奥林匹克数学竞赛进行了详细的调查。从中我们知道,一个学生要经过层层选拔,从比赛的准备到顶级比赛。
例如对英国的制度,要经过 JMC → IMC → SMC → BMO 1 → BMO 2 → IMO 选择整个一层链路(这个 IMC ( Intermediate Mathematical Challenge ) 和上述 IMC ( international mathematical competition for university students ) 这不是一场比赛);
但是,在美国体系中,要经过 AMC 8 → AMC 10 → AMC 12 → AIME → USA ( J ) MO → IMO 选择整个一层系统。
这启发了团队能否评价模型,同时也设置了这种难度水平的体现。因此,研究小组研究了世界各地不同难度水平的比赛,促进了 Omni-MATH 难度仍然多样化,在奥林匹克级别的数学测试中。
同时,在奥林匹克级数学测试中,其实涉及的数学领域很多。研究小组考虑了各个领域之间的数据在模型训练中是否会发生化学变化,比如领域。 A 数据能否将模型泛化到领域? B 从这个角度来看,数据工程是非常有意义的。
为了为这个方向的研究打下基础,研究人员借鉴了相关的竞赛辅导书籍,在这个评价中对数据行业进行了非常详细的划分,从数论、代数、几何等数学类别入手,直到具体的小领域或领域下的知识点。
评价数据的来源主要有两种,一种是各种比赛的题目和解题,另一种是著名的数学网站。 Art of Problem Solving。对需要的比赛,优先考虑问题的答案。
假如想要的比赛没有公开解决问题,团队就会从 AoPS 站点论坛上爬取回复。考虑到回复都是真正的客户写的,有一定的概率是有问题的,需要进行全面的选择。
选择了研究小组 AoPS 备选网站并且答案规则的数量大于 3 问题,并选择 3 所有答案一致的问题都是最终标准。团队在筛选问题时采用人工选择,进一步保证了准确性。
数据处理
处理数据本身:
在抓取到 PDF 开发者使用格式题解后, Mathpix 把它转化成 Latex 格式作为问题解决方案。论坛答案抓取后,先用。 GPT-4o 再次 format 定期回复,以后手动检查是否符合原问题的答案。
对这两种来源的数据,团队成员最终使用人工检查是否与数据库信息一致。
难度分类:
借鉴了 AoPS 站点中关于题目难度分类的情况。
具体而言,不同级别的比赛难度有本质的差异,例如, CEMC 和 IMO 题目之间的差别特别大,但是,每一场比赛的不同题目也有所不同,比如一次一次。 IMO 这场比赛既有简单的问题,也有难题。所以评价集的难度分类严格按照 AoPS 每个问题在网站上给出的不同比赛的难度系数(从 1 到 10 大部分是整数,少数是整数, .5、.25 这个难度)。
对网站上未覆盖的内容,团队成员将网页上的内容整理成 few-shot prompt,并使用了 GPT4o 标注题目难度。总体难度的分布与不同比赛试题的分布如下:
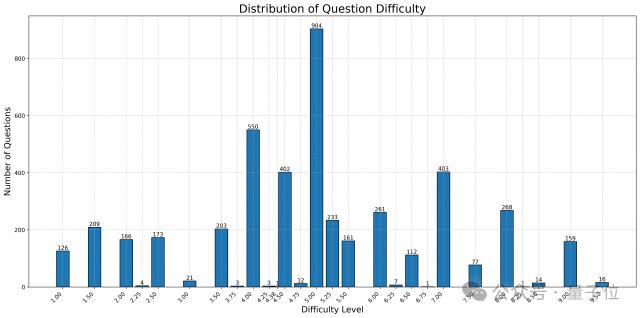
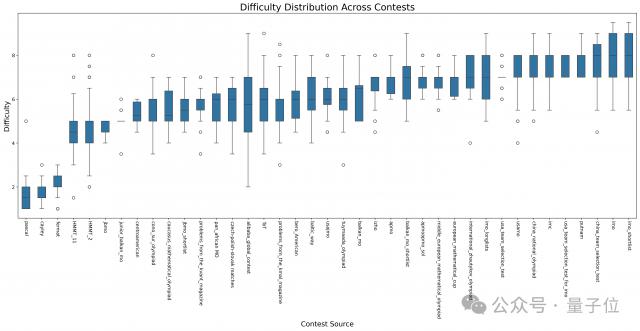
领域分类:
与传统数学测试标准的分类不同,奥数这一难题涉及的领域更多,知识面更广。
团队建立了更全面的树形分类体系,以便组织和统一奥数的话题,探索数学领域之间的数据关系。研究小组借鉴了相关的竞赛辅导书籍,将奥数相关领域分为几何、代数、数学理论、应用数学等领域。之后,从这些领域出发,继续细分为各行各业的小领域和微小的关键知识。
这种树形分类系统更有利于帮助理解不同主题之间的关系,以及模型在不同领域的表现。该团队将该树形分类系统作为模板,并结合竞赛指导书中的案例建立起来 few-shot 提示(具体的树形结构和提示内容可以参考文末的代码仓库)。
接着,团队使用 GPT-4o 将每个题目分为一至多个类别。
开源答案验证器
Omni-Judge 是微调 Llama3-Instruct 用于验证被测答案与给定答案是否一致的验证器。由于数学奥赛级别的题目答案种类很多,用规则来评价其实很难。对模型进行预测后,需要判断模型导出是否与正确答案一致。在使用 GPT-4o 除了评价之外,我们还提供了一种更简单的评价方法。 GPT4o 对模型进行评估 COT 数据微调 Llama3-Instruct 得到一个开源验证器,评估一致率和 GPT-4o 高达 95%。
参考链接:
Project Page:https://omni-math.github.io/
Github:https://github.com/KbsdJames/Omni-MATH/
Dataset:https://huggingface.co/datasets/KbsdJames/Omni-MATH/
Omni-Judge:https://huggingface.co/KbsdJames/Omni-Judge/
— 完 —
提交请发送邮件到:
ai@qbitai.com
标题标注【投稿】,告诉我们:
您是谁,从哪里来,提交内容?
另附论文 / 项目主页链接,以及联系方式哦
我们会(尽可能)及时回复你。

点这里� � 注意我,记住标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相遇。 ~
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com