
大厂“拥抱”Deepseek,打不过就加入?








今年春节,人工智能无疑成为社会话题的C位,有人形机器人在春晚跳秧歌而爆红,之后又有“Deepseek“强势崛起。
网民们疯狂地涌入Deepseek,有些人在寻找Deepseek算命,有些人问Deepseek如何致富,还有科技金融行业的农民工,年还没结束,就得忙着加班写研究报告和测试模型。
但是外国市场对此的态度却很微妙,OpenAI曾经声称Deepseek“盗窃”了它的“技术成果”,但是一转头,微软、英伟达等大厂商都宣布将Deepseek接入自己的产品,OpenAI CEO山姆·奥特曼甚至表示,Deepseek的R1模型“令人印象深刻”。
国内互联网巨头也没有错过这波Deepseek的热度,2月6日,有道正式宣布全面拥抱DeepSeek-R1。另外,Hi Echo、有道智云、QAnything等商品也将全面接入DeepSeek的推理能力,并于近期相继升级。
有一段时间,AI大模型的技术迭代在不知不觉中变成了全球科技行业的现象级事件,Deepseek也被视为推动大模型行业从“专精”到“小精”的全新变量。
但是热闹过之后,Deepseek还会回答更多的新问题,如何把握全球大模型产业的“变革之火”,也许就是下一步的关键。
01 Deepseek三大变量点爆
对于普通用户来说,Deepseek是在这场中美大模型技术之争中“一战成名”,但是早些时候,Deepseek就因为“便宜”而受到AI圈的高度关注。
去年年中,国内大型产业大打出手,但第一个“挑起战争”的不是阿里、百度等大厂商,而是Deepseek,当时其新推出的DeepSeek-V2价格仅为 GPT-4-Turbo 大约1%左右。
这次“降价”也使得Deepseek被称为“AI界拼多多”,但与大厂商“以价换市场”的惯例相比,Deepseek对“降价”的压力并不大,因为降价后还是有利可图的。
事实上,这就是Deepseek能够震惊全球科技界的主要原因。它可以以更低的成本换取更高的性能,颠覆了过去依靠堆叠显卡和资本来发展AI的大型行业。Scaling law”。
由于Deepseek的模型训练路径不同于传统的大型通用模型,以ChatGPT为代表的传统AI主要采用监管微调(简称 SFT)作为大模型训练的核心环节,即通过人工标注信息进行监督训练,然后结合强化学习进行优化。本质上,大模型不会思考,只是通过模仿人类的思维方式来提高推理能力。
然而,Deepseek-R1-Zero在1月底发布,却颠覆了这一规则,通过简单的强化学习,全方位创新了模型架构。(RL)培养推理能力。简而言之,SFT就是人类生成数据,机器学习;而RL就是机器生成数据,机器学习。
此外,根据每日财经新闻报道,DeepSeek创新性地使用了FP8、MLA三种技术:(双头潜在注意力)和MoE(使用混合专家架构)。
在这些模型中,MoE架构与其它模型相比,DeepSeek-V3更简洁有效,就像医院的“分诊系统”。大模型可以分成多个“专家”,培训时可以分工合作,推理时可以根据任务分配给最合适的专家模块。据报道,Deepseek可以将无效训练从过去90%降低到60%。
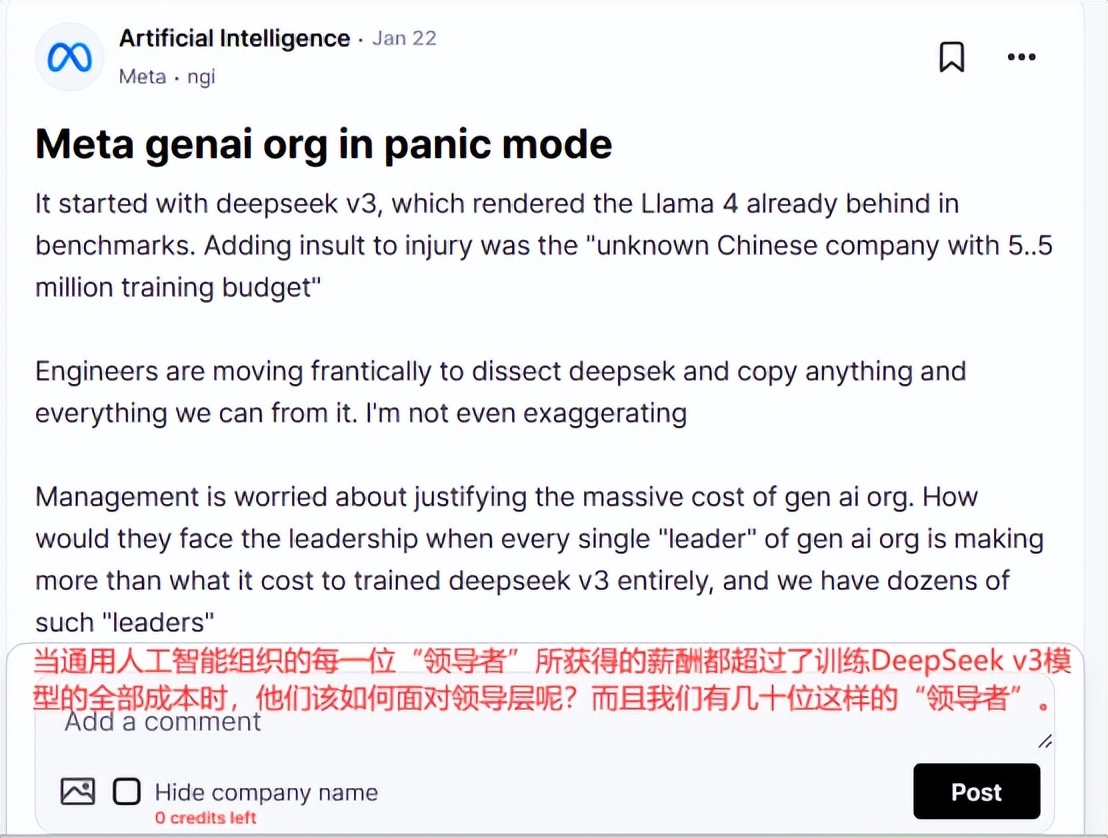
Deepseek-R1发布后,一名Meta员工在美国匿名职场社区teamblind上留言,称Deepseek最近的一系列动作让Meta的生成人工智能团队陷入恐慌。
根据该员工的消息,“Meta一位负责AI项目的高管的年薪已经足够训练Deepseek了”。根据国家商报的报道,Deepseek R1的预训练费只有557.6万美元,还不到OpenAI。 GPT-4o模型训练费用的十分之一。
但是从实际表现来看,Deepseek-R1已能与OpenAI-o1正式版本相媲美,特别是在数学、代码、自然语言推理等方面。
数学比赛在美国举行(AMC)以及全球顶级编程竞赛(codeforces)等待权威评估,DeepSeek-R1-Lite-Preview 这个模型已经大大超越了 GPT-4o 等待顶级模型,有三项成绩仍然领先于三项。 OpenAI o1-preview。
除了“低成本、高计算能力”的突破,Deepseek之所以在这个春节“点燃”,是因为它不是来自传统的大公司,而是一家量化的基金公司。
Deepseek成立于2023年12月,在此之前,其创始人梁文锋于2015年成立了一只名为“幻方量化”的量化对冲基金,可以说Deepseek的前身实际上是为量化交易服务的。
这种背景也为Deepseek增添了更多的“看点”,比如梁文锋之所以不缺钱,是因为它在量化交易中赚得很顺利,网友们甚至开玩笑说,Deepseek的练习费用来自于造空英伟达。
还有梁文锋,他背靠1000亿的量化基金,显然可以选择轻松躺着赚钱,但他选择投身于全球创新的浪潮。他承认“对AGI的好奇和探索比商业收入更有动力”,这种不屈不挠的“理想主义”希望让Deepseek的“故事”更加感人。
02 大厂打不过就加入
但是,技术上的反击,还不足以完全震惊科技界,真正点燃Deepseek的变量,其实就是“开源”。据报道,Deepseek已经开源了模型架构和参数,目前在模型公司普遍选择闭源的情况下,行业内很少有开源培训数据的例子。
梁文锋曾在接受媒体采访时表示:“在过去的几年里,中国公司习惯了别人的技术创新,我们把它们作为应用来实现,但这不是理所当然的事情。我们的初衷不是借机赚钱,而是走在技术的前沿,促进整个生态发展。”
从商业角度来看,很难下结论“开源”是否是更好的策略。毕竟培训模式需要成本,吸引客户也需要广告成本。从字节豆包大规模投放广告和kimi几次接受融资可以看出,大型公司有自己的困难。
但是对中国的大模型产业来说,也许正是梁文锋的“理想主义”,让Deepseek成为颠覆行业格局的“变量”。
另一方面,开源可以吸引更多的大型工厂和技术人才加入,通过共创共创,使Deepseek更加强大,从而促进整个人工智能大模型生态的发展,形成全新的生态。
梁文锋曾经告诉媒体,未来公司不会像OpenAI那样选择从开源到闭源。“我们认为首先拥有强大的技术生态更重要。” 。
另一方面,对于以OpenAI为代表的竞争对手来说,这也是一个致命的打击。毕竟,当消费者面前出现平等或免费的产品时,人们不可避免地会进行比较。谁性价比更高,谁性能更好,都需要用实际效果来检验,而不仅仅是“吹泡沫”。
目前,英伟达、英特尔、亚马逊、微软、微软、微软、微软、微软等海外大公司都是第一个做出选择的。AMD、等待大型海外科技公司,都宣布将Deepseek接入自己的产品。
值得注意的是,欧美许多国家仍然对Deepseek的安全性和隐私问题提出质疑。许多美国官员表示,他们正在对Deepseek进行国防安全调查,包括国防部、国会和NASA部门,他们都被要求禁止使用Deepseek。
另外,根据彭博社等媒体的报道,微软也进行了调查。 OpenAI 中国的Deepseek团队是否以未经授权的方式获取技术输出数据,例如通过“蒸馏技术”非法获取模型导出数据。
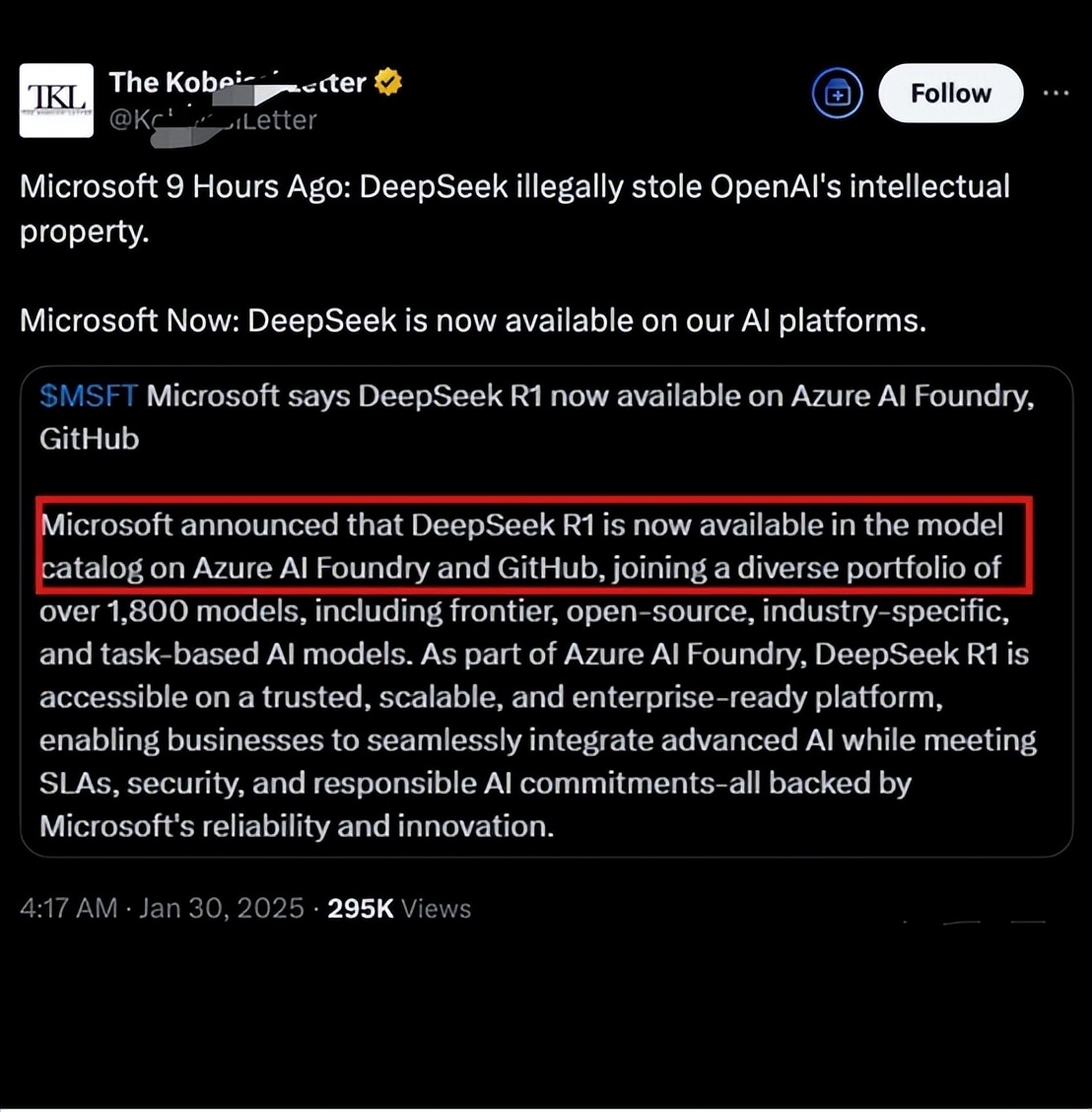
然而,在这些争议得到解决之前,大公司显然迫不及待地想加入Deepseek生态系统,这仍然是基于“利益至上”的原则。
根据斯坦福大学计算机科学系和电子工程系副教授吴恩达的说法,OpenAI - tokeneno1模型每百万导出模型。 而Deepseek-R1的费用是60美元 则只需 2.19 美元,这接近30倍的成本差距,相信大厂也会算账。
其次是生态效应,吴恩达认为,“降价” “开源”正在商业化基础模型层,为应用开发者创造了巨大的机会。尽快加入这个生态系统,让自己的大模型与之结合,也有望带来更多的创新感受,“收缩”一些DeepSeek用户的需求。
因此,除了海外大厂商,如阿里巴巴云、百度云等国内大厂商也逐渐集中接入Deepseek,在各自的平台上提供适应服务。只有当他们打不过的时候,他们才能加入,共享创新收入。
03 东风乘坐Deepseek
事实上,在春天爆红的Deepseek,不仅给大型行业带来了一股“微风”,也给普通用户带来了更多的新机遇。
第一批使用Deepseek赚钱的人已经出现了。面对更智能、更高效的大模型,AI取代了人类的焦虑,再次成为收获用户的“武器”,就像当时诞生的ChatGPT一样。
社交媒体上已经出现了很多“如何使用Deepseek进行XXX”的课程,面向社交媒体、电子商务、广告等不同行业的应用和实现。
当然,学习新知识是绝对正确的,但与被焦虑“收获”并成为大V私域流量的一员相比,你不妨先试试Deepseek,根据你的实际工作和你擅长的内容。
目前,Deepseek在技术上取得了意想不到的突破。对于普通用户来说,它可以展示思维链的全过程,更方便人类与AI的交流。业内人士甚至称之为目前最好的开源模式,但不需要太多的“神化”。Deepseek。
第一,从使用体验来看,Deepseek仍然无法承受蜂拥而至的流量。事实上,Deepseek在几年前就已经小规模地“爆红”了,那时它还可以一起使用深度思考和网络功能,输出文章的框架和成文的确令人惊叹。
但是随着用户数量的不断增加,目前Deepseek已经关闭了网络功能,整理导出质量大大降低,而且大部分时间Deepseek都处于“服务繁忙”的状态。
虽然梁文锋曾经说过“商业化”不是目前首要考虑的问题,但“幻方”的资金规模是根据私募基金的规模来计算的,1000亿的规模不等于1000亿的资金规模,“幻方”只收取1000亿的管理费,与大厂商的资金差距还是很大的。
但是要继续保持C端的使用体验,Deepseek必然需要烧钱,后续如何补充资金,或者如何调整使用,梁文锋都需要提出更清晰的玩法。
第二,目前Deepseek在图片、视频方面的优势是不够的,现阶段要说Deepseek可以直接与头部闭源模型进行挑战,恐怕还为时过早。
然而,它的发展也给了Open。 AI,而且更多的垂直模型带来了压力,相信会在一定程度上促进整个大模型生态的发展。
最终,Deepseek仍然面临着政策和数据安全的争议,走向世界仍然是一条漫长的道路。此外,它的计算资源和计算率仍然有限,这意味着国内硬件需要继续努力来支持软件的不断创新。
当然,对于全球大模型行业来说,只有竞争才有动力。就像智能手机行业一样,如果参与者多了,行业内的板块就会越来越多,爆发的机会也就越多。
Deepseek的出现就像国内大型模型行业的一个“火花”,不仅是思维碰撞的突破,也是灵感的瞬间。接下来,我相信只有国内大型模型行业在软硬件方面不断创新,才能抓住这个机会,让中国科技行业从“追随者”走向“领导者”。
本文来自微信微信官方账号“新媒体科技评论”,作者:新媒体编辑部,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com