
O3权威评价:AI能力的关键跃升,但是仍然没有达到AGI水平









十二月二十一日,著名的法国计算机科学家和机器学习研究人员在OpenAI发布最新一代推理模型o3的同一天,ARC 弗朗索瓦·肖莱莱基金会的创始人(François Chollet)写作报告说,o3在ARC-AGI基准测试中取得了突破性高分。ARC-AGI是一种专门设计的基准测试,用于检测人工智能模型对极其困难的数学和逻辑问题进行推理。
肖莱在报告中指出,OpenAI最新推出的o3模型是基于ARC的-AGI-在1公共训练集的实践下,在10,000美元的计算限制下,遵守公开排名。(compute limit)在半私有评估集中取得75.7%突破性高分的前提下。在高计算量(172倍)下,o3模型的评分达到了87.5%。
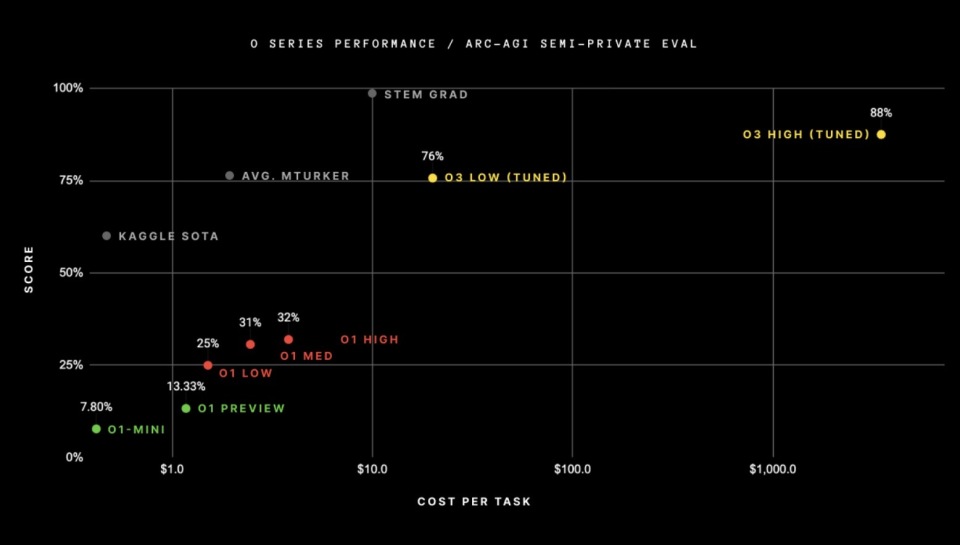
这一成就意味着人工智能能力出现了令人震惊和关键的飞跃,显示了GPT系列模型中前所未有的新任务适应性。例如,在ARC。-AGI-在测试中,分数从2020年GPT-3的0%增加到2024年GPT-4o的5%,这个过程已经持续了四年。现在,对人工智能能力的所有预设认知都需要因为o3而重新评估。
ARC Prize,这场超过100万美元的公共竞赛,旨在引领我们走向通用人工智能,而不仅仅是超越ARC的第一个基准测试。(AGI)“北极星”。ARC Prize基金会兴奋地与OpenAI团队和其他合作伙伴一起设计下一代长期的通用人工智能基准测试。ARC-AGI-2025年将与ARC在一起。 一起启动Prize。ARC 在出现高效开源的解决方案之前,Prize基金会承诺继续举办挑战赛,其评分达到85%。
下面是整篇报告:
对于o3系统,我们对ARC-AGI数据集进行了两次测试:
--半私人评估集:100个用于评估拟合的私人任务;
--公开评估集:400个公开任务。
在OpenAI的指导下,我们在两个计算级别的不同样本大小下进行了测试:6(高效率)和1024(低效率,172倍计算)。
下面是检测结果:
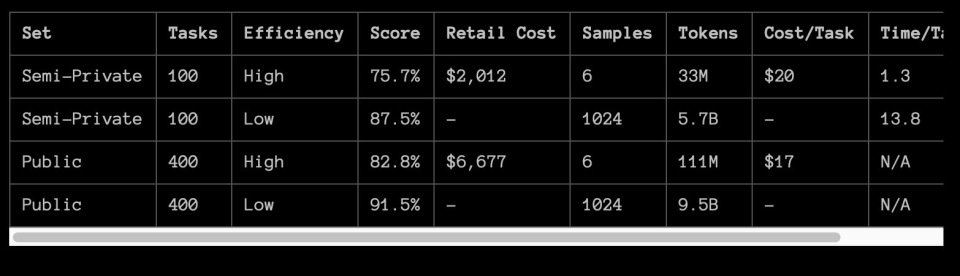
注意:由于定价和功能可用性尚未确定,目前无法提供o3高计算量的成本信息。高计算量的计算量约为低计算量的172倍。
鉴于推理预算的不同,效率-尤其是计算成本-已经成为衡量性能不可或缺的指标。总成本和每项任务的成本已经被记录下来,作为衡量效率的初步指标。在整个行业中,我们需要确定哪个指标最能反映效率,但总的来说,成本是一个合理的起点。
75.7%的分数符合ARC的高效模式。-AGI-根据Pub的预算规定(费用低于10,000美元),所以有资格在公共排行榜上名列前茅。
尽管低效率模式下87.5%的评分价格昂贵,但它仍然表明,随着计算量的增加,新任务的性能确实有所提高——至少在这一层面上。
这些成就不仅仅是通过增加计算率资源来完成的。OpenAI的新o3模型在适应新任务方面取得了长足的进步,这不仅仅是一个渐进的改进,更是一个真正的突破,这意味着人工智能能力比以前的大语言模型有了质的飞跃。o3可以适应它以前从未遇到过的任务,它在ARC-AGI领域的表现接近人类的水平。
这种泛化能力的成本当然相当高,目前看起来并不经济。在完成ARC-AGI任务的同时,你可以为人类支付大约5美元(我们确实这样做过),只消耗少量的能源。而且o3在低计算模式下每项任务的成本在17-20美元之间。然而,预计在未来几个月到几年内,成本性能将大幅提高,因此我们可以预见,这些能力将在不久的将来与人类工作发生竞争。
通用人工智能o3吗?
ARC-作为关键的基准测试,AGI可以突出人工智能的泛化能力,这是那些已经饱和或要求不高的基准测试无法实现的。但是,我们必须明确,ARC-AGI不是衡量通用人工智能的最终标准——我们现在已经多次强调这一点。在人工智能领域,它是一种研究工具,旨在集中精力解决未解决的问题。在过去的五年里,它在这方面发挥了重要作用。
通过ARC-AGI测试并不意味着通用人工智能已经完成。事实上,我认为o3还没有达到通用人工智能的水平。o3在一些相对简单的任务中仍然表现不佳,这表明它与人类智能有着本质的区别。
另外,初步数据显示,ARC即将到来-AGI-对于o3来说,基准测试仍然是一个重大挑战。即使在计算量高的情况下,它的分数也可能降低到30%以下,一个普通人即使没有训练有素,也很容易得到95%以上的分数。这说明我们有能力在不依赖专家领域知识的情况下,建立一个具有挑战性、未达到饱和状态的基准测试。当设计一个对普通人来说容易但对人工智能来说难的任务时,就意味着普通人工智能真的来了。
与旧模型相比,o3有什么不同?
为什么o3的分数远远超过o1?同样,为什么o1的分数远远超过GPT-4o?在我看来,这一系列结果为普通人工智能的持续追求提供了一个非常有价值的数据点。
我对大语言模型的理解是,它们就像一个向量程序的仓库。当收到提醒时,它会搜索与提醒相匹配的程序,并在当前输入中“执行”它。大语言模型可以通过被动触摸人类产生的内容来存储和操作数百万个有用的小程序。
这种“记忆、搜索、应用”的方式,在给定合适的训练数据时,可以在任意任务中达到任意水平的技能,但很难适应新情况或立即掌握新技能(换句话说,这里没有所谓的流动智能)。在ARC-AGI中,这一点体现在大语言模型的表现上,ARC-AGI是专门设计的基准测试,以衡量新事物的适应性。——GPT-3得分为0,GPT-4接近0,GPT-4o达到5%。将这些模型扩展到极限,并没有使ARC-AGI的分数达到近年来基本蛮力枚举(高达50%)的水平。
你需要两样东西来适应新事物。首先,你需要知识——一套可重复使用的功能或程序。大语言模型有足够的知识。其次,面对新的任务,你需要把这个功能重新排列成一个全新的程序——也就是程序生成。大语言模型长期缺乏这一特性,而o系列模型则弥补了这一点。
现在,我们只能推断o3的确切工作模式。但是o3的关键机制似乎是在token空间中搜索和执行自然语言程序——在测试过程中,模型搜索可能的思维链(Chains of Thought, CoTs)这种方法可能类似于AlphaZero风格的蒙特卡洛树搜索,以描述处理任务所需的步骤。在o3的情况下,搜索可以由某个评估模型引导。值得注意的是,Demis 在2023年6月的一次采访中,Hassabis暗示DeepMind一直在研究这一想法——这项工作已经考虑了很长时间。
所以,虽然单一代大语言模型在新事物中挣扎,但是o3通过生成和执行自己的程序来解决这个问题,其中程序本身(CoT)成为知识重组的产物。虽然这不是测试时重组知识的唯一可行方法(你也可以在测试时进行训练,或者在潜在空间中搜索),但根据这些新的ARC-AGI分数,它代表了当前技术的最新水平。
事实上,o3代表了一种深度学习引导的程序搜索方法。在“程序”空间(在这种情况下,自然语言程序-描述处理手头任务步骤的思维链空间)上搜索模型,由深度学习引导。处理单个ARC-AGI任务最终可能需要数千万个token,成本超过1000美元,因为这个搜索过程必须探索程序空间中的大量路径——包括回溯。
然而,这里发生的事情与我之前描述的“深度学习引导程序搜索”有两个显著的区别,即实现通用人工智能的最佳途径。关键是,o3生成的程序是自然语言指令(由大语言模型“执行”),而非可执行的符号程序。这个意思是两件事。首先,他们不能通过执行和直接评估任务来触及现实——相反,他们需要通过另一种模式来评估适应性,而在使用分布之外,缺乏这种基本评估可能会出错。第二,系统不能主动获得生成和评估这些程序的能力(就像AlphaZero这样的系统可以自己学习棋盘游戏一样)。取而代之的是,它依赖于专家标记的CoT数据,人类生成。
目前还不清楚新系统的实际局限性及其可能的扩展范围。我们应该进一步测试来找出答案。无论如何,目前的性能代表了一项伟大的成就,并且清晰地验证了程序空间搜索是一个强大的范式,可以构建一个可以适应任务的AI系统。
下一步会发生什么?
第一,通过2025年的ARC Prize竞赛促进o3的开源复制对于促进研究社区的发展尤为重要。有必要深入分析o3的优势和局限性,这将有助于我们了解其扩展行为和潜在瓶颈的特点,并预测进一步发展可能解锁的能力。
此外,ARC-AGI-1现在已经饱和了——除了o3的新分数,事实上,一个大规模的低计算量Kaggle解决方案集现在可以在私人评估中获得81%的分数。
我们将通过新版本——ARC-AGI-2-提高标准。这个版本自2022年以来一直在开发中。它承诺重置技术的最新水平。我们希望它通过具有挑战性和高信号的评估来促进AGI研究的边界,这突出了当前人工智能的局限性。
对于ARC,我们-AGI-早期测试表明,即使对o3来说,它也将是有用和具有挑战性的。当然,ARC Prize的目的是为了获得大奖而制定一个高效和开源的解决方案。我们计划在ARC Prize ARC同时推出2025(预计启动时间:第一季度末)-AGI-2。
展望未来,ARC Prize基金会将继续创建通用人工智能道路上最难解决的问题,以集中研究人员的注意力。我们已经开始了第三代标准工作,完全脱离了2019年ARC-AGI的格式,融入了一些激动人心的新想法。
邀请参与开源分析:
今天,我们发布了高计算量的o3标记任务,希望得到外界的帮助进行分析。特别是,我们对大约9%的公共评估任务感兴趣,这些任务在大量计算资源的支持下对人类来说非常简单。
我们邀请社区帮助我们评估处理和未解决任务的特点。
这里有三个高计算量o3未能解决的任务示例,以激发外部想法。

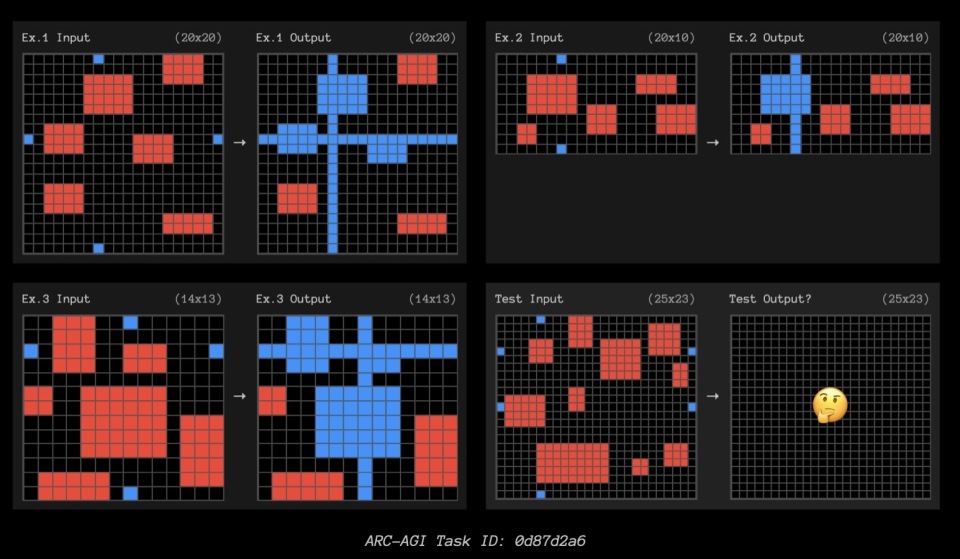
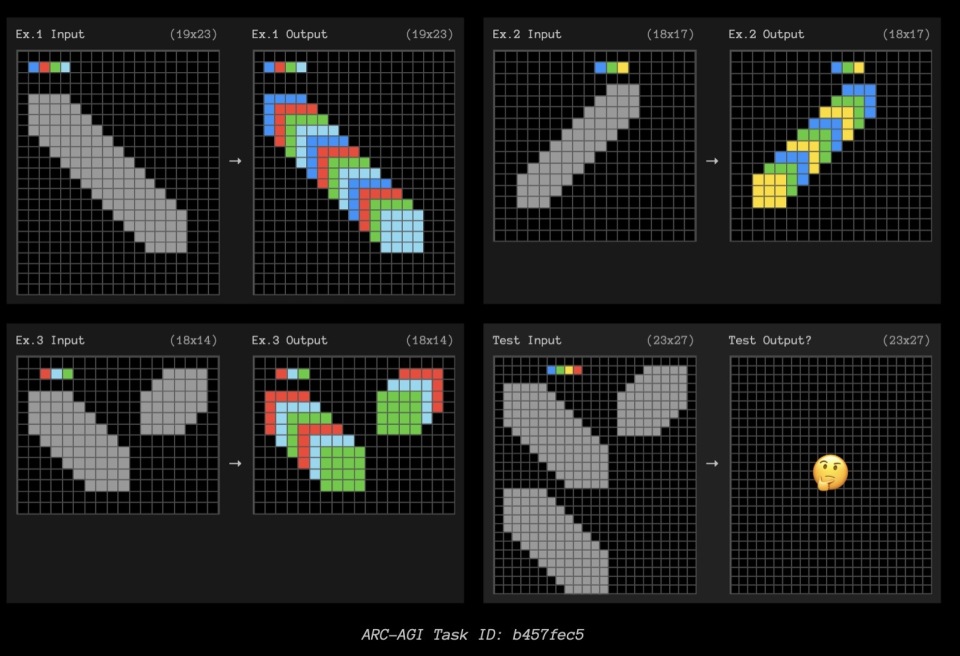
结论
综上所述,o3代表着前进的重要一步。它在ARC-AGI方面的表现突出了其在适应性和泛化方面的真正突破,这是其他任何基准测试都无法如此清晰地展示的。
o3通过大语言模型引导的自然语言程序搜索方法,处理了大语言模型范式的根本局限性——在测试过程中无法重新排列知识。这不仅仅是一个渐进的进步;这是一个新领域的发展,需要严肃的科学关注。
本文来自微信微信官方账号“腾讯科技”,作者:无忌,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com