
沉默的雷声:OpenAI与微软的竞争悄然开始。








OpenAI 在开源Swarm演示Multi-Agent之后,微软开源magenticic。-one。虽然演示的功能不同,前者关注领域模型处理,后者关注文档浏览等基本操作,但这也是Multi-Agent的一个例子。横向对比,微软略好于OpenAI,能解决实际问题,真正可以使用。但是关键不在这里,如果你把两个项目放在一起进行比较,你会发现一场无声的竞争已经开始。
随着Multi-Agent的智能原生程序越来越关键,我们有理由相信这一竞争将会更加激烈。
很多做战略分析的同学可能不愿意读代码,愿意读代码的同学可能不愿意用心去发现这种竞争的导火索,所以我会在这里挑一个东西,再来说说。
OpenAI Swarm做了一个AI冲击游戏,记录参考:人类优先还是智能优先?(第十三期AI冲击游戏小记),当我空的时候,有必要再做一期magentic-one,用非技术语言谈谈这个项目,并做一个两者机制的对比。
AI战略要地
AI产业的战略要地是什么?
事实上,备受关注的大模型基本上不是,除非只有一家一骑绝尘,别人的模型水平是1,你是10。
假如大型模型是竞争最关键的地方,那么实际上OpenAI Swarm基于GPT-4o,微软magentic-one也基于GPT-4o,每个人都没有任何矛盾。您做好模型,我用好模型,您好我好,一点矛盾都没有。
关键是,如果你期待的是超级应用,我期待的是超级应用,那么随着超级应用价值的增加,超级应用全链的关键控制点就会有你死我活的竞争。
OpenAI与微软之间暗搓矛盾的根源不在于某个应用程序,而在于谁对AI的基础设施有控制力。
那么未来各种超级应用的关键控制点是什么呢?找到这个基准点,就可以找到AI的战略要地。
OpenAI与微软之间的潜在冲突与下面这张简图有关:
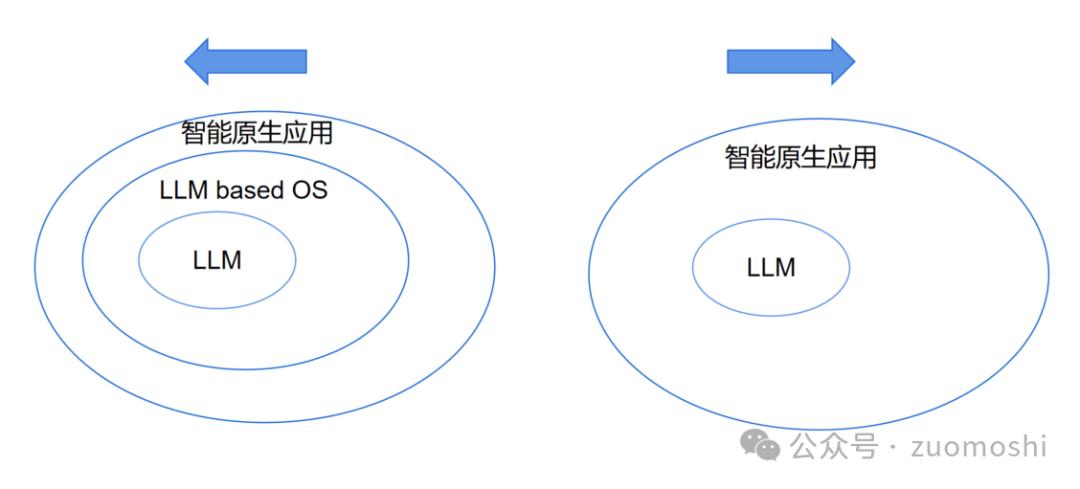
其中智能原生应用相关详细说明参考:真伪◎智能原生(AI Native)应用极具挑战性
由于我们在谈论微软,所以我们拿LLM。 based 与过去的Windows相比,OS。
比如我们常用的Windows也包装了很多算法,但是不管我们在Windows上写了多少程序,我们都不会直接使用内部包装算法,而是使用Windows提供的界面。这些算法对你来说是透明的。谁知道Windows里包装了多少算法?
为什么会这样呢,因为Windows中不仅有算法这一功能,还有帐户管理、消息机制等部分将功能联系起来。
以上两张图片中,核心区别就是这样:
左边的图片仍然有系统的概念,但是在右边的图片中,系统的概念消失了,模型不仅实现了逻辑判断的能力,也取代了系统。
为什么会引起强烈的冲突和竞争?
多大池子养多大鱼?
由于数据所有权不同,智能原生应用注定有多个,但是LLM based OS和LLM不是。
这是一个超大的基础设施,但是理论上,在联通的市场空间中,最终可能只剩下几个,Top1占市场份额的50%以上。。
谁在AI时代做到了这一点,谁就是新时代的巨头。
OpenAI需要这个,而微软显然不会放过这个。
可以左边的构图里面有微软的位置,右边没有。
假如世界最终选择了右边的图片,那么模型就是系统。,在AI这个地方,微软企业没有基础设施的位置!
一切都刚刚开始
上边实际上是一些猜测,这一猜测有一个前提:智能原生(AI Native)应用程序将席卷每一个应用领域。这个也需要一些时间,所以上面提到的深层差异也就在开源项目上漏出了一点线索。
但是数字的事情最违背人类常规感知的点就是速度,假如人类进化的速度是1,制度文化进化的速度是100,那么数字的进化速度至少是100万甚至更多。
一到两年前,大家都不知道什么是智能原生,但是现在以上两个开源项目,每一个都是智能原生的。
因此,这一潜在的冲突也可能在某一时刻爆发,重要的节点应该是智能原生应用的收入规模。
后续的走势
目前,这种竞争将以沉默的状态开始。短期内谁占优取决于用户的选择。但是,如果模型不迭代几次,应用范围还是会比较窄。微软开源项目附带的说明直接说明了目前的状态。

1、2、3、4、5、6如用一句话简单概括一下,就是你要把它放在沙盒里,然后人类看着点,以免造成不可预测的损失。
具体而言,以下任务在运行时可能会执行其他任务,例如,将系统搞停机这样的事情就有可能发生。

https://github.com/microsoft/autogen/tree/main/python/packages/autogen-magentic-one
在这样的前提下,这种新的智能原生方式并不是不能使用,而是范围会受到狭窄的限制,你不敢让它负责犯错后代价特别高的事情,比如直接做诊断和治疗。
好消息是这个精确的问题可以解决,目前还不知道在一般的大模型上到底什么时候处理。
如果你有足够的钱,你实际上可以在相对垂直的行业走特斯拉。 FSD12走过的路,如果没有那么必须等待通用大模型的升级,这两者实际上是等价的。
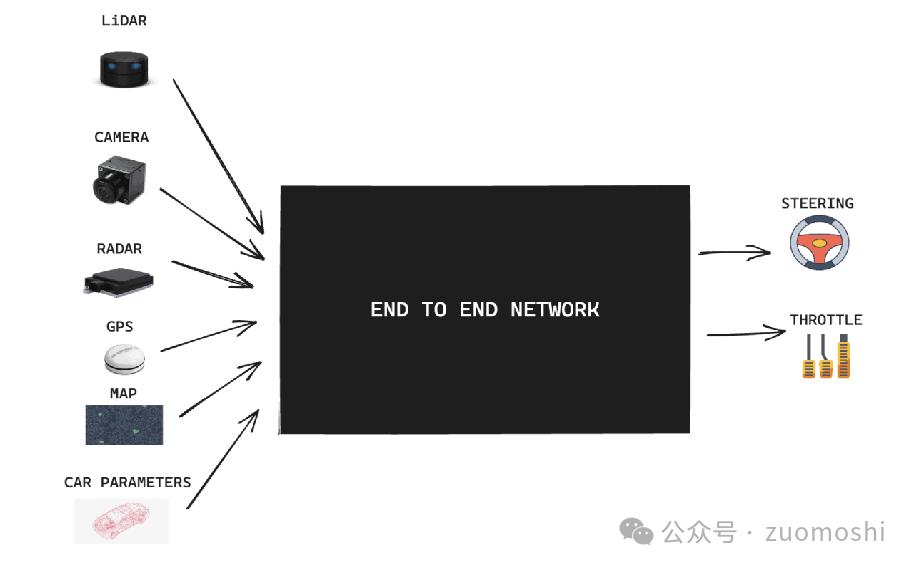
理论上,如果一般的大模型足够强大,那么专门训练一个E。-To-实际上,E模型与直接将数据丢失到通用模型没有什么不同。
通用模型没有任何智能界限!
实际上,终点应用的边界就是数据的边界。
无论如何,这里需要一个转折点。不然我们上面说的就是身影,不会漏出真面目。
这一转折点在技术上是通用大模型的进步,在商业上有一家Top智能原生应用企业。为什么因特网变得如火如荼?本质上是因为曾经的BAT啊,BAT的收入水平确实足以开始一个时代。
我认为美国人会到达这个临界点。Tesla的FSD12就不多说了,Glean的ARR每年增加4倍,5500万美元也不算少。商业总是存在的,而时代机会只有一次。
总结
更有趣的不是美国怎么样,而是美国和中国的AI显然可以分为两个难以连接的生态系统。中国的情况如何?美国和中国的生态系统最终会如何竞争和共存?互联网花了20多年才拿出这样的问题答案。从现在开始,AI可能需要这么多时间。因此,隐藏的小时代估计会过去。
本文来自微信微信官方账号“琢磨事”,作者:老李话一三,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com