
首次发布清华团队「具有智能环境的真实开放环境」EmbodiedCity









当前人工智能被视为具体智能(AI)该领域最具潜力的方向之一,重点关注智能体感知、学习和与环境动态互动的能力。
近几年来,具体智能发展迅速,在许多领域取得突破。但是,目前大部分具体智能研究都集中在室内场景等有限环境上,对城市级开放真实世界场景的探索相对较少。,迫切需要建立相应的模拟平台和基准测试集。
近日,清华大学城市科学与计算研究中心以虚幻引擎5为基础开放发布。具有智能模拟环境的城市EmbodiedCity,专为多模态大语言模型而设计(MLLM)以及大语言模型(LLM)赋能智能体量身定做,基于真实城市开放场景打造3D城市环境,进一步为不同维度、不同水平的开放空间提供智能能力,构建相应的任务集和数据,可以支撑真实开放空间,拥有智能化的多项研究任务。

官方网站:https://embodied-city.fiblab.net/
论文链接:https://embodiedagentbenchmark.github.io/agent/static/article/EmbodiedCity.pdf
该平台提供离线运行和在线接入两种形式,基于Python,可以下载在不同操作系统的本地环境中运行,也可以访问智能体在线平台。 开发智能体的SDK调用,直接用于平台网页编程。
EmbodiedCity模拟环境
EmbodiedCity基于虚幻引擎5构建了基于北京市国际贸易区的真实道路和建筑布局,结合人流和车流的真实数据和模拟算法。一座真实、动态、开放的城市环境。


下列元素主要包括在环境中:
街道:机动车/非机动车道、十字路口、交通指示灯和人行道,街道布局合理多样。


(2)建筑物:办公楼、购物中心、居民小区等,粗粒度建模还原真实建筑。

其它元素:长椅、路灯、植被、动态车辆和行人,城市场景充满活力。


城市具体智能任务基准测试集

为充分探索具有智能身体的开放环境的感知、推理和管理能力,EmbodiedCity构建了一系列评估任务,包括行人模拟、交通模拟、场景理解、问答、对话、导航和规划等具体任务,以及传统的感知、预测和决策任务。
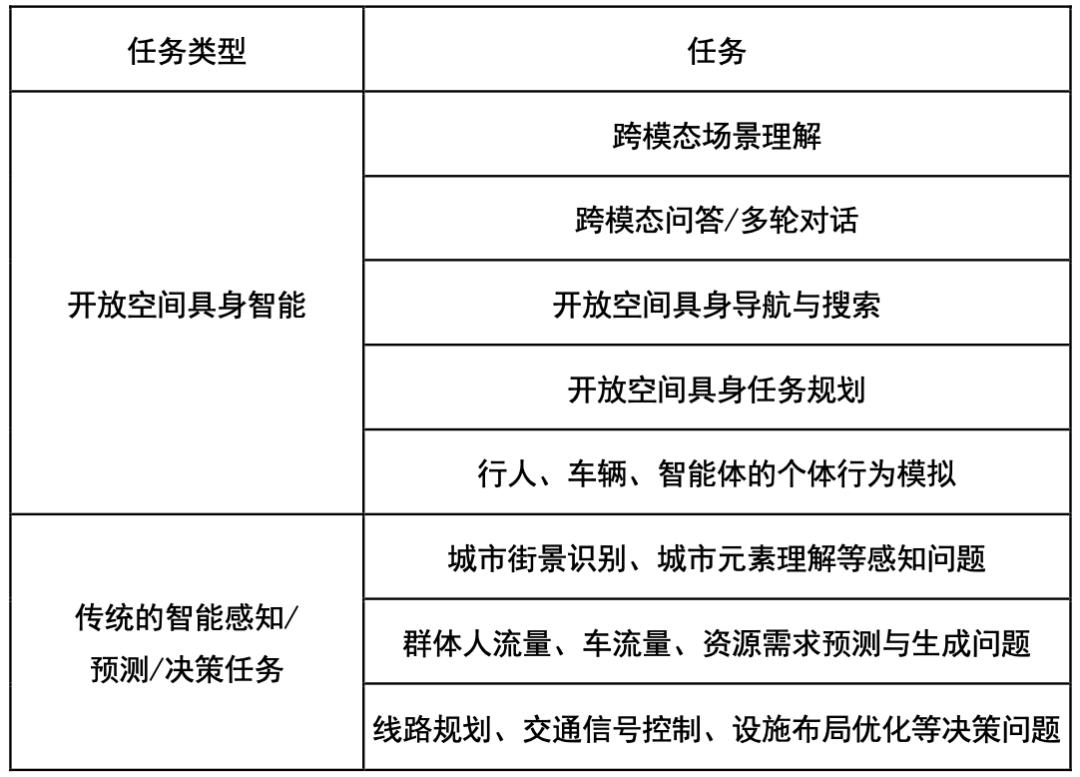
在这些任务中,针对开放空间具身智能建设的任务集如下:
1. 理解跨模态场景:通过在同一位置从不同角度观察,智能体观察环境元素并给出准确的描述,生成一组RGB图像作为输入,从而获得相应的文本描述。
2. 跨模态问答:智能体在了解具体情景的基础上,接受相关环境语义和空间信息的自然语言咨询,例如,「场景中有多少栋建筑?」以及「A建筑在当前视野下是否在B建筑的左侧?」输入RGB图像和相关环境问题,包括第一视角,直接用文字回答问题。

3. 多轮对话:具体对话涉及到智能体与用户之间的持续互动,需要保持前后文和理解对话流程。例如,「后面有多少棵树?-> 它们是什么颜色的?」输入任务包括具体观察和多轮查询,以获得多轮响应。
4. 具体导航/搜索:智能体根据自然语言指令在环境中进行具体导航,输入视觉感知和自然语言指令,通过复杂的环境引导智能体实时感知、推理和决策。任务导出是环境中的行动序列。

5. 任务规划:智能体需要能够将复杂而长期的具体任务目标分成多个子任务,例如,「我要去便利店购物,但是我不知道该怎么走,该怎么办?」输入包括分析第一视角和描述自然语言的任务目标,导出是智能体规划、拆解的一系列子任务。
6. 个体行为模拟:对于不同类型的智能体,如行人、车辆、无人机等。,需要从第一个角度进行分析和当前任务规划,生成类似真实个人、符合真实个人规律和模式的行为和动作。这项任务取决于开放世界中的感知、规划和决策的智能能力,这些都体现在上述任务中。
文章来源:清华大学城市科学与计算研究中心
本文来自微信微信官方账号“学术头条”,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com