
OpenAI新模型达到博士水平?我找了几个医生来测试一下。






今天早上,OpenAI 业界期待已久的新模式毫无预告地发布。
在此之前,大家都从 CEO 在奥特曼的推文中猜测这个模型会被称为 “ 草莓 ”。

但是在实际发布的时候,这个模型的名字叫做 OpenAI o1 模型。
奥特曼对这一模型的评价是什么?:到目前为止,它们是最强大、最一致的模型。
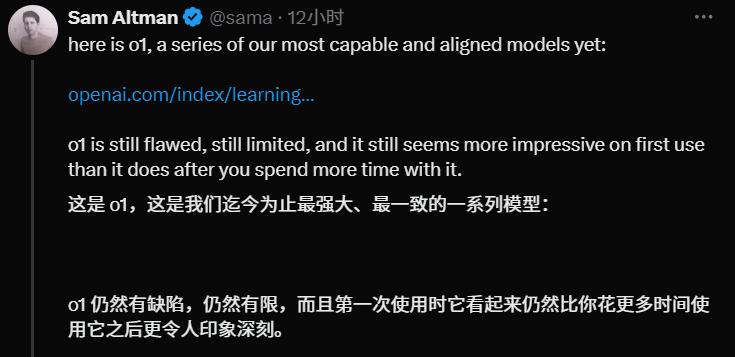
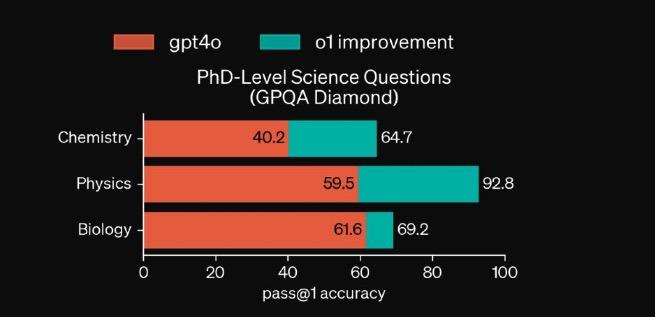
我们可以清楚地看到官方给出的一组数据图。 o1 在国际数学奥林匹克竞赛、编程竞赛和博士学位的科学问题上,模型有了很大的提高。
图片的最左边是 GPT-4o,预览版目前已在中间开放。 o1,最右边的高红柱是满血版。 o1。我们可以看到,基本上每个项目,o1 与自己的前辈相比,他们都很接近。 8 倍的提高。
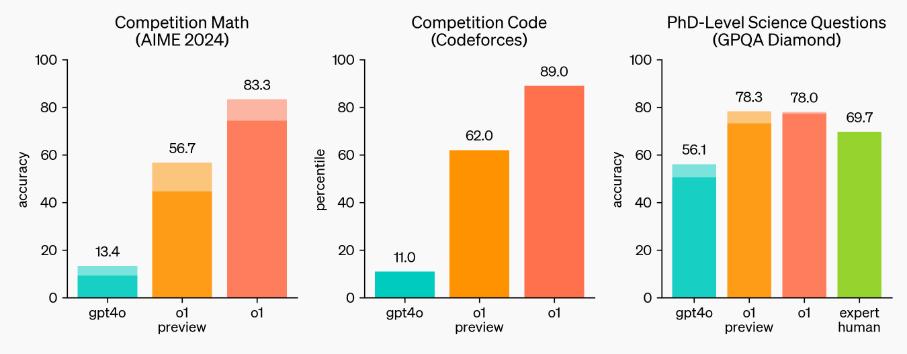
若将这些测试结果拆除, o1 而且几乎在各个学科、各个领域,都是全面、全面、全方位的超越。 4o 版本模型。
而且最可怕的是:OpenAI 他说自己特意请了博士专家一起解决问题,结果发现,在医生级别的检测结果上, o1 解决问题的结果都超过了博士专家,o1 评分 78,人类评分 69.7。
01
所以,人类一败涂地?
为能够大致了解 o1 模型( 预览版 )真正的能力到底是几何,知识危险编辑部邀请了三位知名大学博士。 o1 提问模型,并要求他们提问。 o1 对答案进行评分。( 订阅 ChatGPT Plus 会员每周有 30 次向 o1 提问预览版模型的机会)
为保证多样性和客观性,我们邀请了生物、物理、材料化学等各自的博士。
其中,崔博士,南京大学物理学博士, o1 对模型的评价是最高的,他认为 o1 已经达到 60-80 分( 满分 100 分 )的水准。
甚至在某些问题上,他认为答案可以给出。 90 分。
崔博士的研究方向是量子光学,所以他给出的第一个问题是:长距离纠缠光子分布,有什么办法可以克服白噪音?
思考 9 秒后,o1 就给出了 10 一些可行的措施。

崔博士对答案的评价如下:“ 答案的全面列举符合目前最新的研究进展,可能会为知识储备不足的人提供研究方向,但可能不会为高层次专业人士提供真正有用的信息,属于科普级别的答案。"
在评分方面,崔博士感觉到 o1 这个答案可以打 80 分,他指出,o1 答案中提到的自适应光学的方向是今年最新的。 Science 结果,答案是创新的。
接着,崔博士追问 “ 能不能扩展到量子自适应光学?o1 思考 19 几秒钟后给出答案。

崔博士对这一答案的评价如下:“ 可以给到 90 分数,这个回答对我也很有提示,虽然不具体,但是对于我们来说,只需要指出一个可能的方向,剩下的我们自己去调查思考。
崔博士指出,“他的很多答案都是我知识薄弱的地方,我只是简单的理解了一些概念,但他说我觉得都是有道理的,所以我觉得还是不错的。”
相比之下,崔博士对老版本模型相同问题的评价是否达不到标准或不达标? 60 分。
然而,关于试验细节的问题 "在持续泵浦和脉冲泵浦的情况下,如何测量基于非线性相互作用的高纯度解关单光子的自关联函数?" 在这个问题上,崔博士认为 o1 答案平淡无奇,只能给出。 75 分。
总的来说,崔博士认为在物理方面,o1 表现还算不错,与老版本相比,基本上是在提升。 20 分左右。
接下来,我们来看看北京大学在读材料化学。 K 博士对 o1 模型评价。
K 博士围绕 Fe-N4 资料问了一系列问题,o1 给出一长串答案,为了精简篇幅,我们这边只展示了一些问题和结果。

经过整体测试,K 医生给出的评价也差不多:也许有研究生水平,但深刻的认识和给计划的能力较差,主要针对已知内容进行回答。
比如问怎样调整 Fe-N4,o1 可以说出基于电子状态的调整,但是如果你问它怎么调整,它就会有点卡住。尽管与之相比 4o 模型没有那么胡说八道,但是在具体问题上他们都不能给出太多的建议,老版本 4o 就是失去了细节乱说,新版本 o1 那就是能力有限就会词穷。
接下来,我们再来看看清华大学在读生物学的信博士的评价。 ,“他的问题是:” 如何从质谱数据中区分赖氨酸残基的乳酰化和羧乙基装饰?
o1 还有一个特别长的答案,有些像综述,后面还贴了参考文献。

但是出乎意料的是,在我们把这个答案交给信博士的时候,他看了之后发现有些不对劲。
倒不是这 AI 所有的答案都是错的,而是 AI 乱编参考文献,这篇论文根本就没有!
然而,总的来说,信博士仍然感觉比以前更好了。 AI 强大了许多,至少理解能力是肉眼可见的增加,编辑时还是很相似的。。
实际上,这一测试的结果并没有超出知危编辑部门的预期,因为根据官方数据,o1 物理学分数已经达到。 92.8,已远远超过其它两门学科,这也许就是崔博士对它比较看好的原因。
02
综合来讲,真要说超越专业博士水平,三位博士认为还得慢慢来。
崔博士直言,在实际的科研工作中,大多数学者还是要自己动手,AI 只能提供大致的方向,所以花钱要如此细致。 AI 意义不大。
他指出,他更建议本科生选择这个。 AI,假如是硕士阶段,那么 AI 答案实际上并不符合导师的标准,在小组会议上肯定会受到批评。
清华的信博士也有同样的看法,更不用说了。 AI 就专业程度而言,幻觉编造文献问题,AI 答案也只能忽悠大同行,即同一学科中不同方向的人;但是在小同行、专业研究这一方向的人眼里,AI 问题仍然十分明显。
北大 K 医生们谈得更深,他觉得这个 AI 只能说在认知上有硕士学位,但也只是作为一名修补工,并不能说出什么创造性的结果。就创造性而言,AI 远远落后于硕博的水平,这也是 AI 重要的问题需要解决。
对于医生的评价,我们似乎可以抓住一个重点:o1 这个模型之所以比较强大,是因为它有更高维度的认知和思维模式。
这,也是 o1 这次更新的要点。是的 OpenAI 关于 o1 在模型原理解释的文章中,他们表示 o1 变强主要是因为他们使用了长思维链。( CoT,Chain of thought ) ,而非传统的提醒链( Prompt chain )。
第一眼看上去有点傻,说实话,这个大模型改变了以前那种你问我答案的思维方式。
在以前的模式下,大模型的问答就像下意识地得到答案一样。比如你问我天是什么颜色,我都不想这个问题,每一秒都是蓝色的。这显然需要我已经知道的知识点,然后直接给你反应。
但这条长长的思维链相当于,我不仅要知道什么是蓝色,还要考虑为什么是蓝色,什么是大气透射,光谱波长。
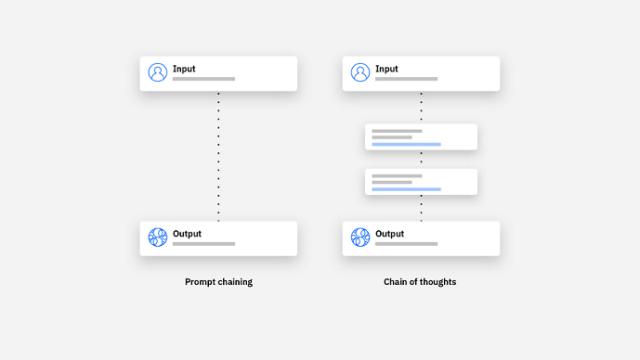
这,就需要 AI 要有实实在在的构建逻辑,推理论证的能力,也就是说,他不仅要有大脑,还要动脑。
尽管思维链这个概念是 2022 年谷歌提出的,但是 OpenAI 这次是第一次实现。
在实际操作过程中,现在你和 o1 模型对话,除了得到答案,还可以看看他在回答问题时的思维能力,他的思维是具象的,而非黑盒。
我问崔博士这个问题 "长距离纠缠光子派发,有什么办法可以克服白噪音? ” 以这个问题为例,o1 模型思维过程如下:

当我们问崔博士的思维过程是否合理时,崔博士说:“ 理性地说,达到博士学位,或者高学段博士学位。
因此,o1 由于他的思维链达到了医生的水平,他会像医生一样思考物理问题,所以模型在物理问答上表现得更好。
同样,o1 模型在生物学和化学方面的年表现相对较差,很可能是思维链还没有训练到最佳状态。,但就物理问题的表现而言,当训练越来越成熟时,o1 我们可以期待变得更强, o1 发布模型正式版本。
03
哦,对了,最后放一个有趣的小蛋。
虽然思维链是推动的 o1 模型可以像医生一样思考,但是在基本问题上的训练似乎还不够全面,我们发现他在简单的问题上仍然会犯低级错误。

他思考了 12 几秒钟后,自信地告诉我们 8.11 比 8.9 大。。。
怎么说呢,医生也会犯错,没问题~
本文来自微信微信官方账号“知危”,作者:知危编辑部&差评,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com