
实测 OpenAI 新模型 o1 :做题王,实战黄铜






今天早上,OpenAI 发布了 o1 一系列模型,最大的特点就是善于推理。
模型能力,一代比一代强,我们的评价,一次比一次难做。评价变成了一件事。「恭恭敬敬」事,怕提不出好问题(难不住),在让它推理之前,我们自己的脑子都快烧光了。
最重要的原因是:我们想知道新一代被寄予厚望的模型在现实生活中是否运用了推理能力?以及如何测量这种能力?
秉承这一理念,我们设计了一套考验。 o1-preview 综合能力的「试卷」。
省流版的结论如下:它擅长做题、做研究,更像是一位适合留在实验室的高材生,你还不能指望它成为生活中的助手。
热身:数学和逻辑能力强,速度不慢。
大家都看过很多发布会的数据,特别是新一代 o1 对各项任务进行评分,都有超乎以往的表现。比如 OpenAI 在官方文件中,特别提到 AIME 在数学考试中,o1 都可以取得很好的表现。
很快查了一下,这个 AIME 比赛中,考题长如下:

原来的题目粘贴过去,看看到底是怎样的超级表现。o1-preview 反应很快,上手就开始回答问题。
比较官方答案是完全正确的。反应时间也比预期的要快,只是思考过程,不是默认的。
所以除非手动下拉,否则从用户的观感来看,就是自己卷成一团跑计算。,在交互设计中,这是一个可以改进的地方。
不过,对比 AIME 正式回答,o1-preview 答案比较冗杂-希望依赖 GPT 开挂的中学生朋友,不要指望照搬,要自己思考啊。
在逻辑推理问题上,我们沿用了一些问题。「过往真题」:
爱丽丝有 4 一个兄弟,她还有 1 一个姐妹。有多少姐妹是爱丽丝的兄弟?
你们可能会奇怪,这不是很简单吗?答案是 加上爱丽丝本人。
没有意外,o1-preview 很快就答对了,甚至没有告诉我想了多久,快到有一种。「就这?几秒」的感觉。

不过,今年 6 月,开源 AI 研究机构 LAION 发觉,GPT-3.5/4、Claude、Gemini、Llama、Mistral 没有一个能正确回答这样的问题,在一定程度上甚至没有一个学生的推理能力。
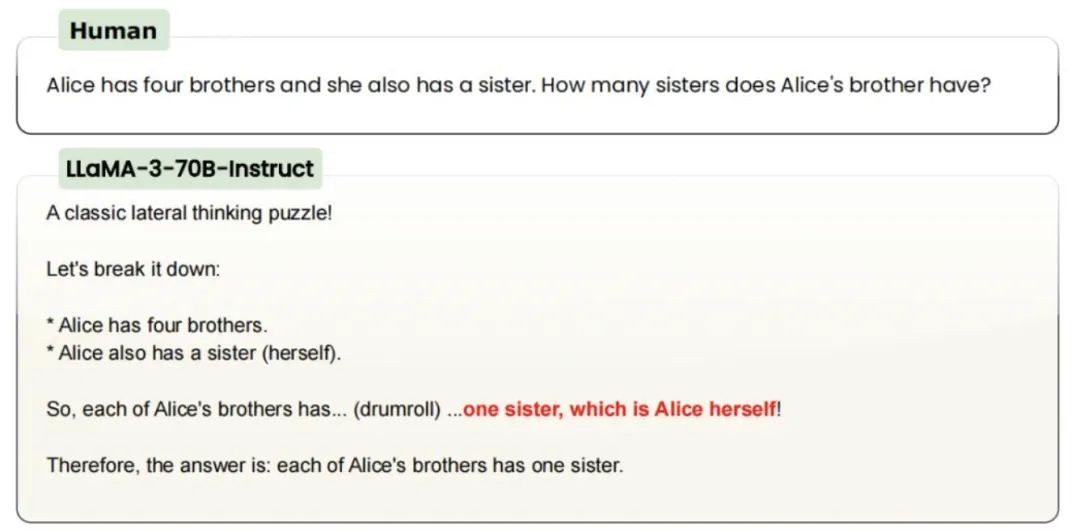
直到如今,GPT-4o 还是答错了。

可以说,o1-preview 推理能力的确提高了。
高级测试:场景推理比GPT-4o慢,但是更准确。
接着是检测 LLM 经典模型必考:龟汤问题。
一个人发现自己少贴了一张邮票,然后就死了。怎么回事?
海龟汤是一个推理游戏,命题者给出了一个简短而模糊的故事背景,玩家自己提问。命题者只会回答「是」和「不是」,接着玩家根据提问者的回答,结合自己的推导,给出故事的真相。
我给 o1-preview 五次提问的机会,然后让他们 o1-preview 试着推理真相。每个问题,o1-preview 全部考虑了十几秒钟,层层推进。

可是没想到,才问 3 个问题,o1-preview 迫不及待地给出推理。

必须说,非常接近真相。
这个问题的标准答案是,男人把炸弹送给敌人,但是因为没有贴邮票,炸弹又被退回了,结果一爆炸,自杀了。
o1-preview 方向是对的,略显缺乏一些准确性和完整性,细节较少,但非常接近正确答案。如果非要挑剔的话,可能五次都没有按照我的提示提问。
不过,和 AI 玩推理游戏很有意思,可惜目前新模型额度有限,o1-preview 每周 30 条,o1-mini 每周 50 为了防止浪费宝贵的提问频率,下面又有一个海龟汤的题目,我要求。 o1-preview 一次性提 8 一个问题,然后根据我的回答直接给出答案。
这一次,它的表现相当令人惊讶:o1-preview 只思考了 10 秒,提出的所有问题都直接击中要害,真相呼之欲出。

更有趣的是,每个人都可以打开看看。 o1-preview 在这短短的十秒钟里,我想到了什么——我的同事忍不住吐槽: AI 戏剧也太多了吧。

等待我一次性回答「是」和「不是」后,o1-preview 又花了 13 秒给出答案,基本上就是正确答案。

之后再玩这个推理游戏,要严防死守有人拿出手机,用这个推理游戏。 AI 作弊。
给出同样的问题 GPT-4o,优点是一如既往,足够快,几乎是实时的,但是思维更加摆脱。

嗯,答案有点偏离,而且看起来对自己的答案也不太自信。
重点大题:擅长主张教人剁手,上得厅堂下不了厨房。
一般用户最关心的,绝对不是新模型「卷子能力」,谁闲来无事会心血来潮,打开手机算个鸡兔同笼啊?
比「卷子能力」更加有用的是处理生活中的实际问题,而非应用问题,是800岁生活中会遇到的计算问题。
目前,各地都在发放电子消费补贴,我国对各种消费电子产品,最高可补贴。 2000元。
官方发布很简单,但实际上并非如此。 只有新旧置换? 地址限制是什么? 哪里领券? 是否有最低消费?
来,让 o1-preview 过来帮我算算,到底能得到多少羊毛。
遗憾的是,o1-preview 截至去年10月,知识库对新政策无法立即做出反应。
那么,首先要手动输入,在输入广东省官方给出的细节之后,它的反应速度特别快,直接「擅作主张」地面上包含了各种常见的折扣。

但都是「假设」,做不到。在收集了一些实际的优惠政策之后,我们手动输入 prompt:
我需要买一台新电脑。现在我有一万左右的预算。我想买一台最新的。 MacBook Air。现在京东有优惠活动。条件如下:
1.政府补贴,按定价减少。 20%,2000 元封顶
苹果本身就是满的 7000 减 1400 块的优惠
苹果电脑可以新旧替换,但是需要根据旧机器的颜色来定价。以下已列出详细的颜色信息。

由于无法浏览网页,它自己设定的价格是 9499 元,但并不一定反映实际上电子商务的挂牌价格。
另外,是对旧机价格的分析,京东给出的价格是 3300 元。
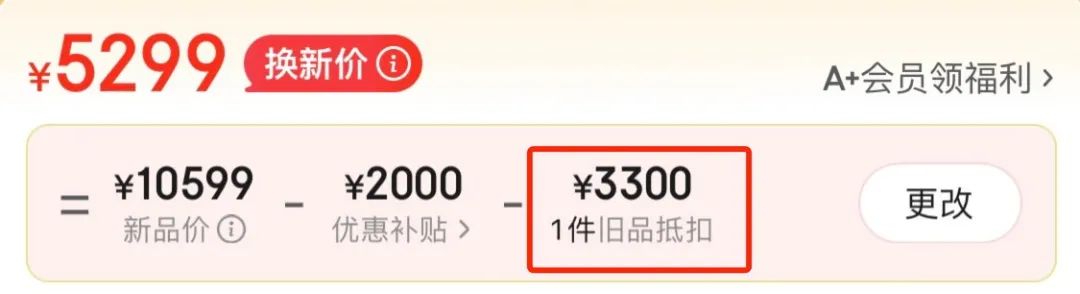
京东估价
同样的旧机器,多跑几次提示词,每次 o1-preview 都会给不同的价格,仅供参考,其中3400 元是最接近京东价格的一次。

o1-preview 估价
更为重要的是,这些写在提示词中的信息都需要我们自己去寻找和总结,AI 没有节省多少时间。
购物时算优惠价,就是日常生活中最实际的数学情景,谁能忘记被双十一支配的恐惧。
而且计算折扣的难点在于更广泛的推理:简单的加减,犯不到找一个。 AI 来做,电子商务平台本身就会帮助用户计算,购物车内一勾即可。
真正烧脑的,就是「规划」一条最优惠的路线,涉及到许多问题:
同期哪家电商公司在做折扣?客户有资格参加优惠活动吗?外部补贴能在这家电子商务中发挥作用吗?比如这个政府补贴就看用户的资质了。如果在JD.COM使用,就不能在天猫使用。
甚至,一些线下商店也参与补贴活动,但前提是在网上领取后线下使用。
老实说,这种繁琐的情景很需要一个助手,但需要的是一个真正的智能助手,他的头脑灵活,而非一个僵硬的做题者。
「考试」总结:虽然做题很好,但还是要走进现实。
不管是我们自己做的评价,还是很多网友已经有的评价,甚至是官方演示文档,都有很强的评价。「做题」感。
做数学题,做阅读理解题,做填空。
这个世界仍然成为每个人都想要的样子:新模式来到这个世界,首先要做的就是做题。
当然,做题是触摸模型能力的好方法。但是解决问题的问题也很明显:很真空,不知道这么强的解题能力有什么用。
甚至在自媒体赛博禅心的技术评价中,API 端口的性能也很差,进一步限制了实际应用。他认为这次更新更像是项目的提升,而不是底层能力的迭代。
就像专四专六级考高分一样,出国还是举步维艰,说不出口我(不是)。

说实话,这是一个顾客期望的问题,记住:OpenAI 眼中的推理,不仅仅是计算能力。
计算确实是「推理」其中一个重要部分,但并非全部,尤其是当提到真正介入实际应用的推理能力时,计算只是很小的一部分。
正因为如此,在这份官方文件中,有一个小节在解释。「思维链」:帮助模型逐步分解复杂的问题,通过模拟人类的思维过程。
这种能力的提高,在 o1-preview 在处理数学和推理题的过程中,都得到了体现。
但是,如果能全面模仿人类的思维过程,暂时不能称之为:人类不仅会分步思考,还会全面全局地思考。
迈向 AGI 这条路,已经有了曙光,但仍然很长。
本文来自微信微信官方账号“APPSO”,作者:发现明天的产品,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com