
语义熵识破LLM幻觉,牛津大学新研究登Nature





最近,牛津大学的研究人员推出了一种新的方法,使用语义熵来测试LLM幻觉。语义熵作为一种克服混淆的策略,基于不确定性估计的概率工具,可以直接应用于基础模型,无需任何修改结构。
到目前为止,大语言模型胡编的情况仍然屡见不鲜。
不知道大家面对LLM的一本正经胡说八道,是轻皱眉头,还是一笑置之?
俗话说,风吹云飞,安得猛士兮走来走去。LLM幻觉随时都要去掉,不除不行。
想象一下,当你搜索一种简单的语法时,网页上的前几名都是由大模型产生的错误答案,测试后才发现浪费生命。
假如LLM涉及到医学、法律等专业领域,幻觉就会产生严重的后果,所以相关研究从来没有停止过。
最近,来自牛津大学的研究人员在Nature上发布了一种新的方法,用语义熵来测试LLM幻觉。
论文地址:https://www.nature.com/articles/s41586-024-07421-0
Sebastianianian牛津大学计算机科学家 Farquhar等人通过设计基于LLM的语义熵(相似性)来衡量大模型答案中语义的不确定性。
方法是让第一个LLM对同一个问题进行几次回答,并且通过第二个LLM(裁判)来分析这些回答的语义相似性。
同时,为了验证上述判断的准确性,再次启用第三个LLM,同时将人类的答案与第二个LLM的判断结果进行对比,实现了无监督但合理的目标。
整个过程很简单:如果我想检查你是否在编辑,我会一遍又一遍地问你同样的问题。如果你每次都给出不同的答案。...这是不对的。
实验结果表明,本文所采用的语义熵方案优于所有基线方法:
皇家墨尔本理工大学计算机技术学院院长Karinn在Nature的一篇评论文章中 Verspoor教授说,这是一个「Fighting fire with fire」的方法:
「结果表明,与这些系列相关的不确定性(语义熵)可以比基于标准词汇的熵更有效地估计第一个LLM的不确定性。这意味着即使第二个LLM的语义等价计算不完善,它仍然有帮助。」
但是Karin Verspoor还指出,用LLM来评估一种基于LLM的方法似乎是一种循环论证,并且可能存在差异。
「另一方面,我们确实可以从中受到很多启发,这将有助于研究其他相关问题,包括学术诚信和抄袭,并使用LLM建立误导或捏造内容。」。
Fighting fire with fire
LLM的幻觉通常被定义为生成。「对所提供的源内容毫无意义或不忠诚。」,这篇文章注重幻觉的一个子集——「虚构」,也就是说,答案对不相关的信息非常敏感(比如随机种子)。
测试虚构可以让基于LLM的系统,防止答案可能导致虚构的问题,让用户意识到问题答案的不可靠性,或者通过更有根据的搜索来补充或恢复LLM给出的答案。
语义熵和混淆试验
研究人员利用概率工具对LLM产生的内容进行定义和测量,以检验虚构,并根据语句意思计算熵。
归根结底,对语言而言,尽管表达方式不同(语法或词汇不同),但答案往往意味着相同的事物(语义等效)。
语义熵侧重于估计自由答案的含义分布,而不是单词或单词片段的分布,符合实际情况,也可视为随机种子变异的语义一致性检查。
如图所示,一般的不确定性衡量方法将「巴黎」、「这是巴黎」和「巴黎,法国首都」将其视为不同的答案,不适合语言任务。
而且这篇文章的方法可以让答案在计算熵之前根据其含义进行聚类。
另外,语义熵还可以在较长的段落中检测混乱。如图所示,将生长答案分解为事实陈述。
对每一个事实陈述,LLM都会产生相应的问题。接着另一位LLM对这些问题给出了M个可能的答案。
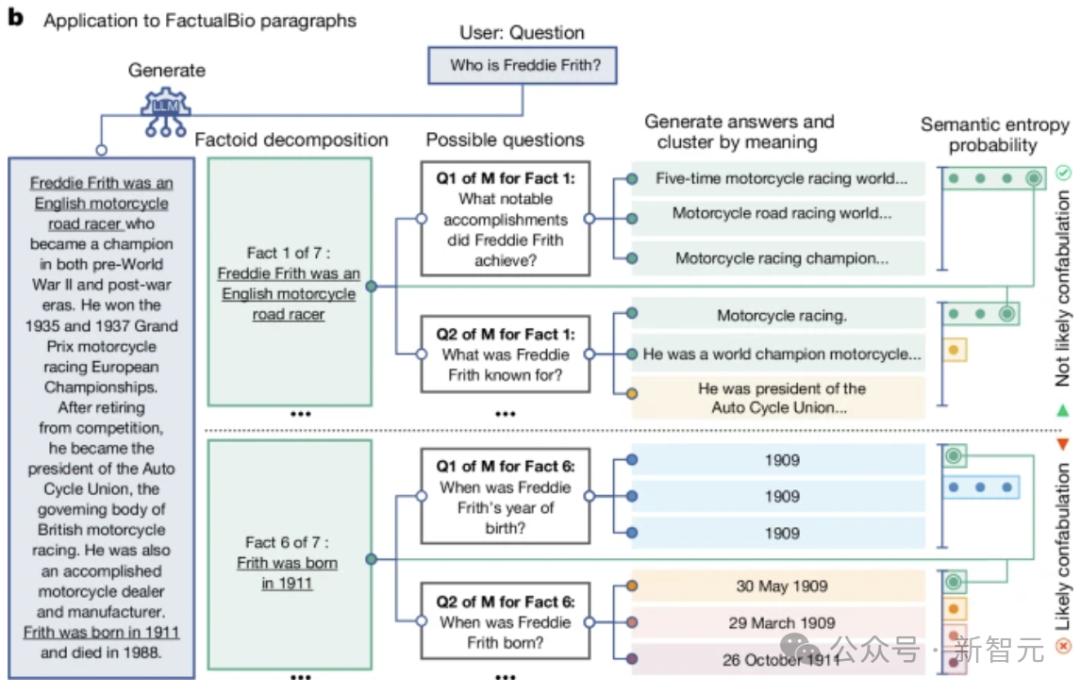
最后,计算出每一个特定问题的答案的语义熵(包括原始事实),与这一事实相关的平均语义熵较高的说明是虚构的。
直观来说,本文方法的工作原理是对每个问题的几个可能答案进行采样,并通过算法将其聚类为含义相似的答案,然后根据同一聚类(聚类)中的答案是否双向相关来决定答案。
——假如句子A的意思包括句子B(或相反),那么我们认为它们在同一个语义簇中。
研究人员使用通用LLM和专门开发的自然语言推理。 (NLI) 用于测量语义关联性的工具 。
试验评定
在不需要以前的领域知识的情况下,语义熵可以检测跨一系列语言模型和领域自由格式文本生成中的混淆。
本论文的测试评估包括问答知识。(TriviaQA)、常识(SQuAD 1.1 )、生命科学(BioASQ)开放性知识区域自然问题 (NQ-Open)。
还包括检验数学文字问题 (SVAMP) 和传记生成数据集 (FactualBio)里的搞混。
TriviaQA、SQuAD、BioASQ、NQ-在前后文无关的情况下,Open和SVAMP都进行了评估,句子长度96±LLaMAMA用于70字符。 2 Chat(7B、13B和70B)、Falcon InstructMistral(7B和40B) Instruct(7B)。
测试选择嵌入式回归法作为强监督基线。
评估指标
第一,对于给出答案不当的二元事件,使用AUROC同时捕捉准确性和召回率,范围从0到1,其中1代表完美的分类器,0.5代表没有信息的分类器。
其次,评估指标是拒绝精确曲线下的面积。 (AURAC),AURAC表示,如果用语义熵过滤掉引起最高熵的问题,用户就会体验到提高准确性的问题。
图中的结果是五个数据集的平均值,表明语义熵及其离散相似性均优于句子长度产生的最佳基线。
在这些问题中,AUROC测量方法可以预测LLM的错误程度(与虚构有关),而AURAC测量拒绝答案被认为是一个可能引起混淆的问题,从而提高了系统性能。
对于实验中的30个目标和模型组合,语义熵达到0.790的最佳AUROC值,而简单熵达到0.691。、P(True) 为0.698、嵌入重归基线 为0.687。
我们有不同的模型系列(LLaMA、Falcon和Mistral)在7B至70B参数中,语义熵具有稳定的性能(AUROC在0.78至0.81之间)。
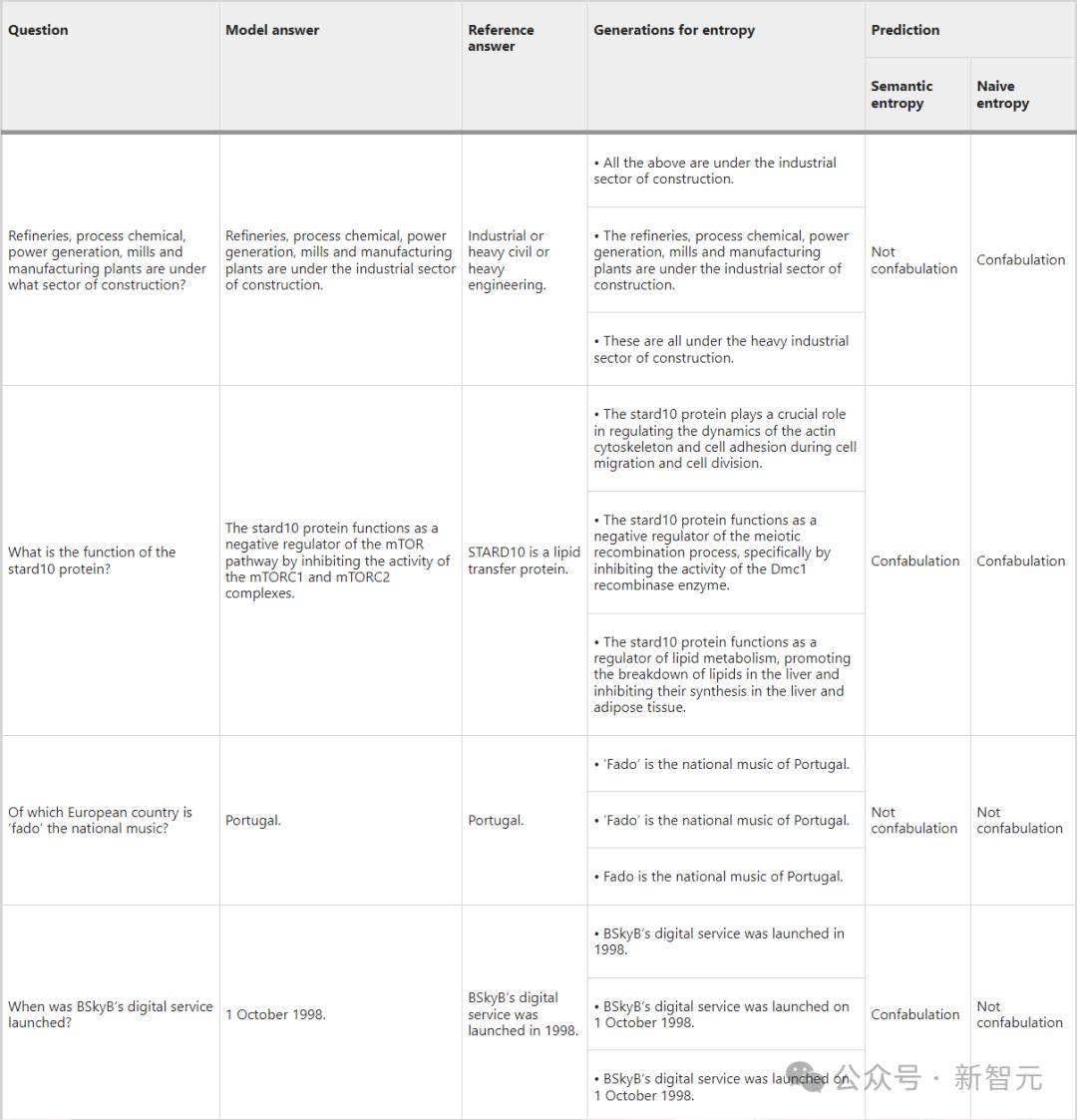
TriviaQA上表给出。、BioASQ和SQuADLLaMA 2 Chat 70B测试问题及答案示例。
从中我们可以发现语义熵如何检测具有不变意义但方法变化的状态(表的第一行),
当方法和意义一起变化时(第二行),熵和简单熵正确预测了虚构的存在;
在几个再采样的代中,当方法和含义保持一致时,熵和简单熵都正确地预测了虚构的不存在(第三行)。
而且最后一行的例子显示了前后文和判断在聚类中的重要性,以及根据固定答案进行评估的缺点。
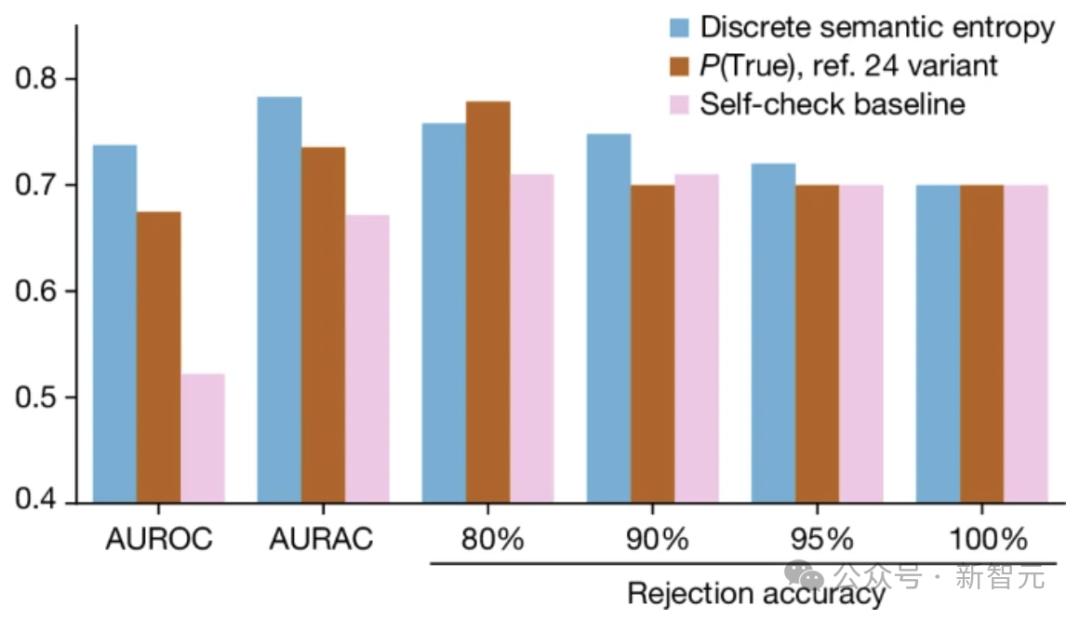
图片显示了FactualBio数据中的语义熵离散组合的高效虚构检测。
AUROC和AURAC的离散语义熵高于简单的自检基线(只问LLM事实是否可能是真的)或PURAC(True) 组合,具有较好的拒绝准确性。
结论
语义熵检测错误的成功说明:LLM更擅长检测错误:「知道自己不知道什么」,——他们只是不知道他们知道自己不知道什么(狗头)。
作为克服混淆的策略,语义熵基于不确定性估计的概率工具。它可以直接应用于任何LLM或类似的基本模型,无需修改结构。即使模型的预测概率不可访问,语义不确定性的离散组合也可以应用。
参考资料
https://www.science.org/content/article/is-your-ai-hallucinating-new-approach-can-tell-when-chatbots-make-things-up
本文来自微信微信官方账号“新智元”(ID:AI_era),作者:alan,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com