
大模型价格战,还可以再狠一点。









没有人想到,大模型产业的第一次“集体会战”,竟然围绕着价格进行。
五月六日,私募股权巨头幻方的深度追求,开始了第一枪降价。DeepSeek-V2(32k)深度追求发布模型,在数学、编程、中英文等方面已经接近GPT-4;然而,DeepSeek-V2的应用价格只有GPT-4o的1/35左右。
DeepSeek-V2的输入和输出价格分别为1元/百万tokens和2元/百万tokens,远低于市场价格。
比拼多多砍一刀还便宜,让不少美国专家大吃一惊。著名分析师Dylann 看完DeepSeek-V2的论文,Patel兴奋地说:“这可能是今年最好的一篇。[1]
DeepSeek-V2的论文
一个星期后,“卷王”字节跳动又增加了一把火。
豆包通用模型Pro-32k的输入价格被一刀切割到更低的0.8元/百万tokens。火山发动机总裁谭待表示,“豆包的价格比行业低99.3%,从那以后,大模型就以厘计费。”
看到同行如此不讲武德,其他科技公司从此不再淡定。
阿里率先回击,一狠心,大举降低了所有模型的价格。
几个小时后,百度干脆跑到价格终点:宣布两个轻量级模型完全免费。随后,科大讯飞星火Lite API、腾讯混合元大模型lite 同时,256k也相继宣布免费。
如此盛况,很难不让人梦到那段滴滴对决快,ofo摩拜互相扯头发的激情岁月。
但是,围绕大模型的价格战,远不如网约车、自行车共享那么直观,各种专业术语令人摸不着头脑。所以,这些大型企业,究竟热闹些什么?
B面价格战
要理解这一点,首先要了解大模型的商业模式。以阿里巴巴云为例,它提供三种大型服务[2]:
基本服务:模型推理。
模型推理,是指根据输入的信息内容,给出答案的过程。也就是说,推理就是“实际应用”模型的过程。
阿里云预设了多种不同性能的“专业模式”,供用户推理。这项服务的收费方式非常简单,即“以量收费”:以消耗的token数量为单位,使用越多,成本越高。并且性能越好,收费越高。
token是一个用于衡量文本长度的大模型计数单位,可以简单理解为“字数”。三篇75万字的《三国演义》大约需要125万个token。
(2)高级服务:模型微调。
如果觉得“专业版”不好用,阿里巴巴云还提供了“定制R&D”服务,即微调模型。具体费用取决于“定制R&D”消耗的计算资源和发展进度。
(3)超高级服务:模型部署。
如果顾客需要长时间使用大型模型,最好的办法就是将其部署到专属案例中。
专属案例是指直接承接一台或多台物理服务器的所有资源。翻译成人话就是把整个商业广场租下来,而不是租一家店。
这样做的好处是,没有其他商家和你争夺计算资源,响应速度更快。
它的收费模式也是以量收费,但是有两种形式:阿里直接按照“商业广场”消耗的计算资源收费;此外,百度还支持token的数量按模型推理收费。
这三种收费模式面向企业和个人开发者,代表着大模型开发的循序渐进过程。但各大科技公司疯狂讨价还价的,其实就是上面提到的“基础服务”,也就是“专业模式”的推理成本。
推理费具体定价,又分为“输入”和“导出”两部分。
简单来说,输入就是用户提问的内容,导出就是大模型的答案。技术公司通常会根据输入输出的token数量(字数)收取两次费用。
这一复杂而微小的差别,很容易成为科技公司的招数。
例如字节跳动的“0.8元/百万tokens”和“比行业价格低99.3%”,实际上只是输入价格。Pro-32k豆包通用模型的输出价格仍然是2元/百万tokens,与DeepSeek-V2等同行持平。
可以看出,虽然大模型的价格战打得火热,但背后其实还有另一个洞天。
千层套路降价
可见,本轮价格战最活跃的,基本上都是云计算公司,代表BAT和字节跳动。
他们之所以敢于这样降价,还是因为可以从别处弥补损失,羊毛出在羊身上。
正如前面提到的,降价甚至免费,实际上只是基本服务。
毫无疑问,这可以帮助中小开发者以更低的成本建立应用程序。但是,当开发者或企业需要更适合自己的业务,深入使用大模型时,通常无法避免模型微调和模型部署的高级化。——这两项服务,并非本次价格战的主角。
例如,百度宣布免费ERNIE-Speed-8K,如果实际安排,费用将变成5元/百万tokens[3]。
同时,所有降价最严重的其实都是轻量级预设模型;相比之下,性能更强的“超大杯”模型实际降价幅度并没有那么夸张。
例如阿里的Qwen-Max,实际上和字节跳动的豆包一般模型Pro-32k一样,只是降低了输入价格;而隔壁的百度,压根就没有提到超大杯模型。
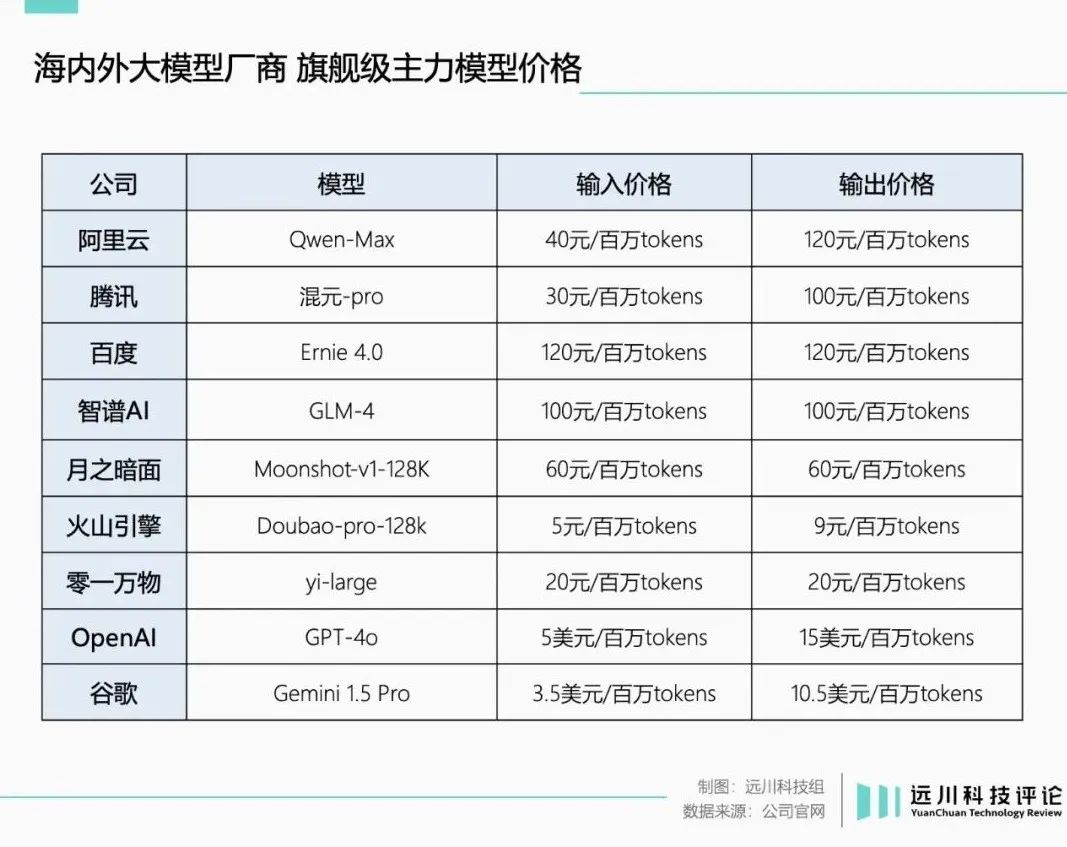
云计算厂商的价格战更像是通过“免费游戏”吸引更多玩家加入;但是如果你想继续“升级变强”,氪金就得氪金。
云计算制造商当然不是唯一的参与者。
以深度追求和智谱AI为代表的明星创业公司之所以敢于跟进内卷,很大程度上是因为有足够的弹药,尤其是计算资源。
2020年,模型还没有爆发,背靠私募巨头幻方的深度追求,投资上亿准备AI超级计算机。
现在,除了BAT,幻方是、除了商汤和字节跳动,第六家公司拥有超过1万张英伟达A1000张。 中国企业GPU储备[4]。
而且智谱AI背靠阿里和腾讯,是一家估值过百亿的AI独角兽公司。
到2020年,智谱AI也碰巧囤积了大量的GPU资源。 在接受《中国企业家》采访时,CEO张鹏提到:
那时,他认识的一家云计算制造商,有一批GPU积尘。 这个GPU最初是供应给游戏公司的,但是一次偶然的机会,对方又不买了。 得知这一消息后,张鹏顺势接管了这批计算资源[5]。
如果现金流量、计算率资源充足,即使烧钱换市场,这些创业公司也能扛得住。
所以问题来了:当初移动互联网补贴换市场,还可以简单粗暴地归因于“技术门槛低”;主要推广一手高科技的大模型,怎么也没有走出价格战的怪圈?
必经之路
大型智能化给世界带来的震撼,通常让人忽视其本质,实际上是一种基础设施。
在去年的公开演讲中,著名计算机科学家吴恩达提到:
事实上,AI是一系列工具的集合。这类工具包括监督学习、非监督学习、强化学习和目前生成的人工智能。 这一切都是通用技术,代表着它与电力、因特网等其它通用技术没有什么不同[6]。
电力和因特网,不能直接创造财富;事实上,电灯、电脑、电子商务、电子游戏是真正改变世界的。
然而,应用程序的爆发实际上有一个前提:基础设施足够便宜。在此之前,大型应用无法快速铺开的一个主要困境是使用成本过高。
哄骗模拟器就是一个典型的例子。
今年年初,一位名叫王登科的独立开发者开发了一个AI应用程序,模拟“愤怒女友”的形象。这个应用程序的玩法很简单,用户必须斗智斗勇地哄骗对话窗口的AI女友。
因为互动简单,构思相当有趣,哄哄模拟器在上线的第一天就吸引了超过60万的顾客。
突如其来的爆红,却让王登科哭笑不得。哄骗模拟器采用了预设的GPT-3.5模型,运行一早就花了他超过2000美元的推理费。
相当于,开发了一个App,还没想到怎么赚钱,先交了一万块电费。
纵观历史可以发现,当初移动互联网的大规模普及,也都是基于基础设施降本。
根据2014年的一份调查报告,当时由于流量成本高,手机用户每天使用流量不会超过3小时。而且很多用户在不使用移动网络的情况下会选择关闭,避免后台使用手机消耗流量[7]。
那时候,大部分用户,都曾经做过“一觉醒来,房子就搬回中国”的噩梦。
2013年,快手明确了“短视频社区”的定位,但增长相对缓慢。这背后,很难说没有大环境的原因。
事实上,短视频行业才真正开始爆发,直到通信运营商开始大做“降费加速”。
2019年,与2014年相比,手机上网流量费用下降了90%以上[8]。到目前为止,手机淘宝、微信、Tiktok逐渐成为字面意义上的“国家应用”。
可以看出,降价实际上是大型行业发展的必由之路。
或许在这一轮价格战中,云计算厂商和创业公司各有各的小九九;但是对于开发者和普通用户来说,建议多打一点。
参考资料
[1] OpenAI Is Doomed,SemiAnalysis
[2] 阿里云大模型服务平台百炼
[3] 大模型千帆平台
[4] 第一代大模型量化巨头发布:免费商业用途,完全开源,澎湃新闻
[5] 智谱AI CEO张鹏:中国大型企业家,不再追随OpenAI,中国企业家
[6] Andrew Ng: Opportunities in AI - 2023,Stanford Online
[7] 2014年中国数据流量使用报告:近40%的客户流量不够,中国新闻网
[8] 工信部组织召开“加速降费”客户零距离交流会议
本文来自微信公众号“远川科技评论”(ID:kechuangych),作者:叶子凌,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com