
DeepSeek开启价格战,小米火速跟进降价:国产大模型洗牌开始了






昨日凌晨,小米MiMo大模型发布的一则公告,在开发者群体里掀起了不小的波澜。
公告的核心内容十分明确:降价,而且是力度极大的降价。
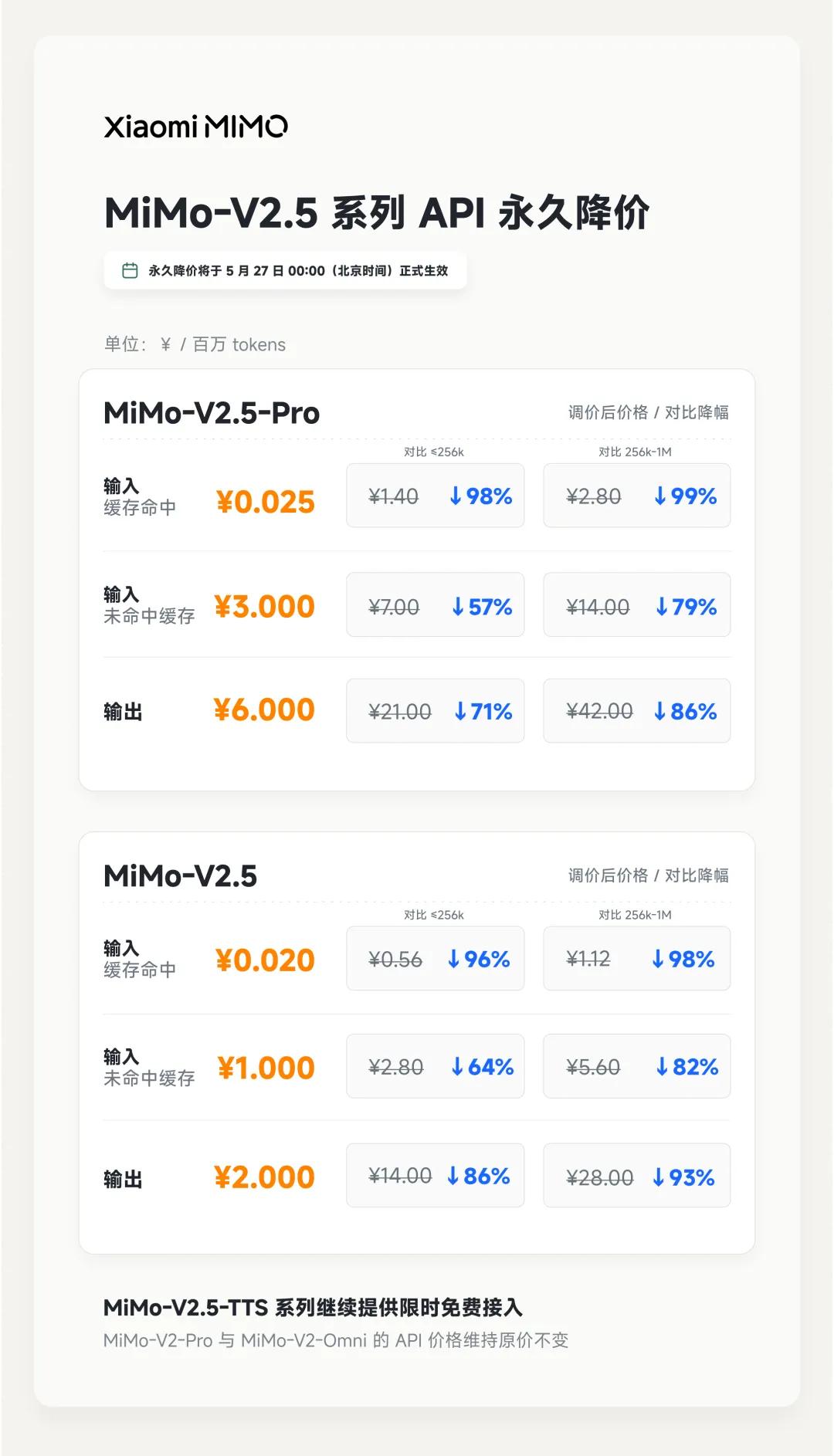
MiMo-V2.5系列的API价格做出永久调整,最高降幅达到了99%,同时不再对不同上下文窗口长度区分定价。此前沿用的Credits积分计费制度保留不变,同价位套餐的可用量提升了大约5到8倍。
如果站在行业全局的视角来看,这件事远不止一次普通促销这么简单:这是DeepSeek V4刷新行业价格底价仅仅四天后,国产大模型赛道里出现的第一次“闪电式”跟进降价。
在这场以“普惠”为名的行业变局背后,藏着国产大模型生存现状的残酷现实,也暴露出行业对token价值的普遍认知误区。
01
DeepSeek定调价格,小米快速跟进
不少AI行业观察者都对小米的响应速度感到惊讶。DeepSeek刚刚靠激进定价击穿了API价格底线,小米就立刻跟进,把自家两款对应模型的价格调到和DeepSeek V4 Pro、V4 Flash完全一致。
这释放出一个非常清晰的信号:我此前一直判断的国产AI行业第二次价格战,其实早已打响,而且已经悄悄进入了贴身肉搏的红海阶段。
客观来看,所有人都必须承认一个现实:当前国产大模型,和GPT-5.5、Opus 4.7这类海外顶尖模型相比,依然存在短时间内难以追赶的代差,而且这个差距未来还有可能进一步拉大。
在“顶级通用智能”这个赛道,国产模型还在埋头追赶;但在处理非复杂任务的规模化落地场景里,不同国产模型的能力其实拉不开绝对差距。
当模型能力无法形成代差优势时,投入产出比(ROI)就成了唯一的核心竞争力。
DeepSeek已经用接连几次的大幅降价证明,在保持国内第一梯队性能的前提下,低价就是获取流量、培养用户替代习惯最有效的方式。
而小米的快速跟进,也坐实了另一个行业逻辑:在这场价格竞赛里,不跟进降价的玩家只能眼睁睁看着用户流失。国内两家头部性能模型都做出了如此大力度的降价,足以说明过去不少厂商的API和订阅定价水分很大。这已经不是愿不愿意降价的选择,而是不降价就会被淘汰的生存问题。
02
高额度Credits数字背后的商业逻辑
虽然API价格出现了翻天覆地的调整,但小米此前推出订阅服务时采用的Credits计费单位,这次并没有改动。
从营销角度看,这确实是一个简单聪明的设计:99元买5亿token已经很有吸引力,换成99元对应110亿Credits,听上去更是堪比福利的力度。
这种大额数字带来的感知冲击,能很大程度缓解用户对“降价会不会缩水服务”的担忧。不过用户还是应该静下心算一算,看清这套设计背后的商业思路。
小米能喊出最高降幅99%的说法,很大程度是因为原来的定价在DeepSeek的冲击下显得过于传统偏高,为了对标对手、留住用户,必须做出这种幅度的降价调整。
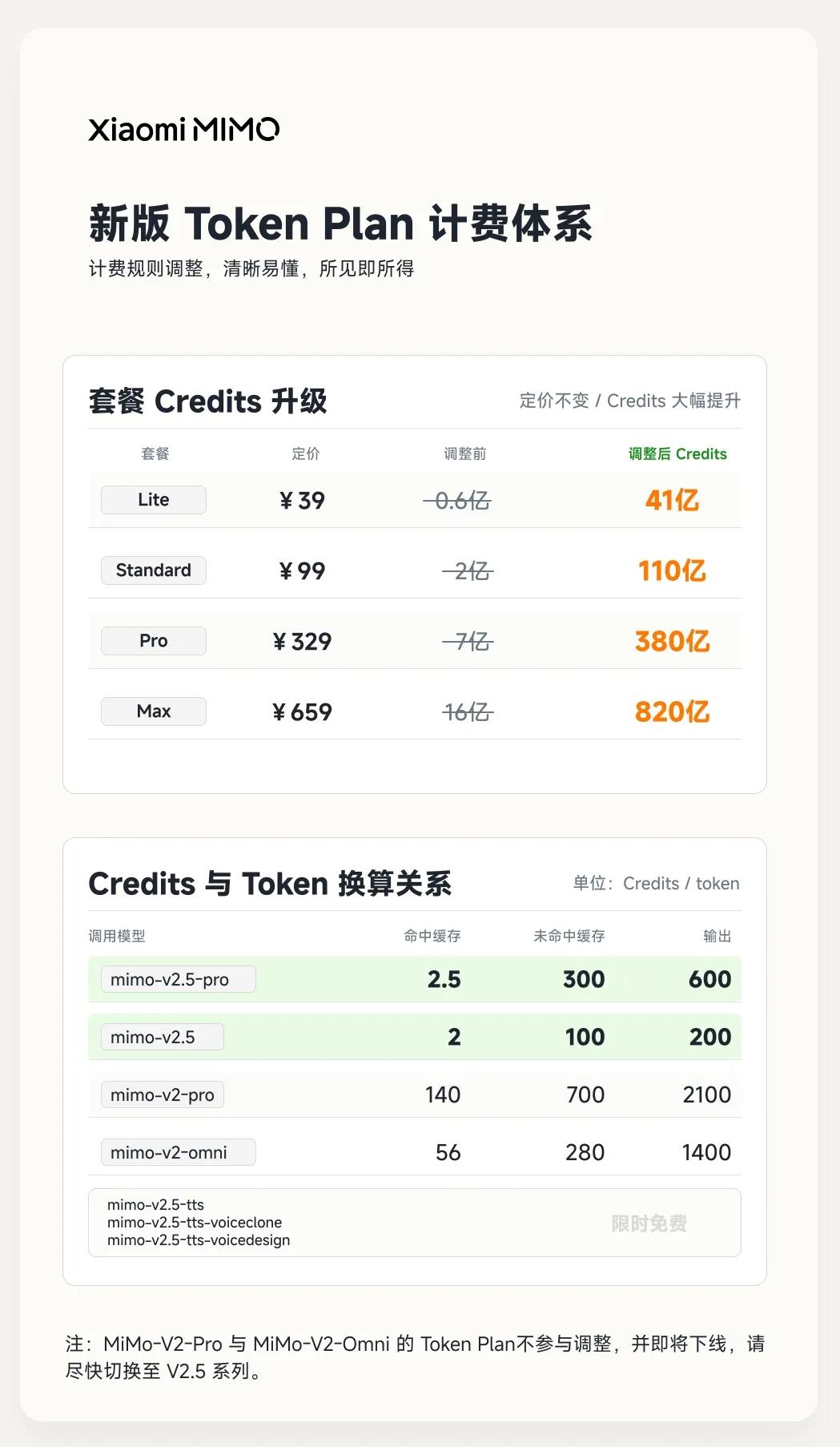
在订阅服务方面,小米首创了国内的Token Plan计费模式,这种模式透明度和可解释性更强,现在已经逐渐成为全球行业主流,官方称同价位套餐的token可用量提升了5-8倍。
以用户订阅最多、价格最低的Lite档位为例,token可用量从原来的60M提升到了500M,折算下来单位成本降幅大约是88%,比API的降价幅度略低,档位越高,成本下降的幅度也就越小。
这种差异其实很好理解,订阅服务本身就是“批发价”,本来就比单独调用API更划算,不管国内外,有长期使用需求的用户都会优先选择订阅。
所以小米这一套操作的目的已经很清晰:通过把API价格降到和DeepSeek同一水平吸引流量,再用订阅服务锁定高频使用的用户。哪怕订阅服务的折扣没有API那么大,但DeepSeek目前没有推出订阅服务,作为第二个推出Token Plan的厂商,小米的算力包已经是当前市面上性价比最高的选择。
这种差异化的设计,其实也是在引导用户行为:它鼓励用户进行高频、重复的智能体调用,因为这类场景下,小米的单位成本最低,用户也能感受到最明显的价格优势。
03
价格拉平后,token含金量才是胜负关键
当不同模型的价格被拉到同一水平线之后,决定竞争力的唯一指标,就变成了token实际能创造的生产力价值。
结合第三方机构Artificial Analysis的测评和实际使用反馈来看,小米MiMo V2.5 Pro和DeepSeek V4 Pro有着完全不同的方向侧重。
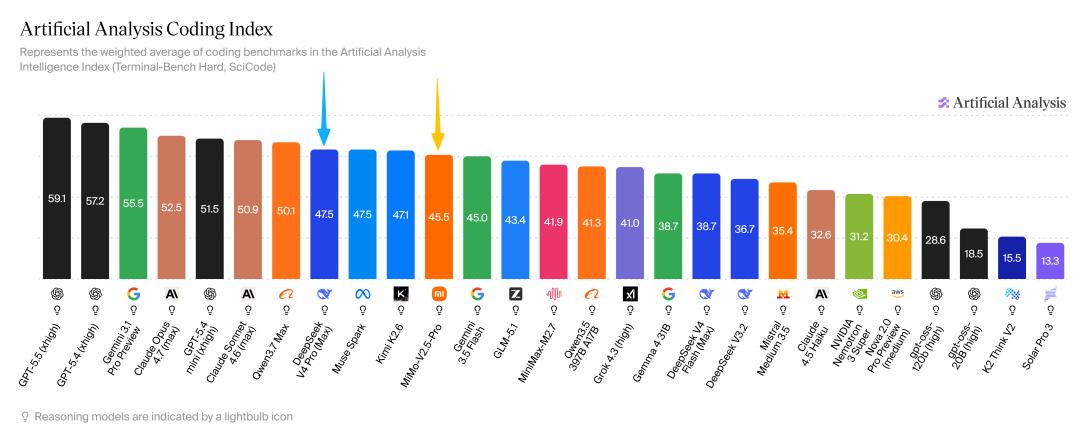
DeepSeek更偏向专项优势选手:编程和逻辑推理能力要略微领先,而且占据用户心智更早,现在是很多个人开发者和小型创业团队的首选。但它的短板也很明显,多模态能力的缺失,严重限制了应用场景的拓展,目前仅有的识图功能也只能满足基础需求,实际作用十分有限。
小米MiMo走的是全场景均衡路线,模型发布时就明确标注了全模态能力。在API定价相同的情况下,小米的token可以处理图像、音频、视频这类多模态交互任务,对比只能处理文本的DeepSeek,在开发智能体应用上会有明显优势。
这也是我之前反复强调的观点:多模态能力在智能体时代绝对不能忽视,反而应该得到更高的重视。
那么小米敢大幅降价的底气从哪里来?公告里提到的技术细节,其实已经透露出小米是怎么压低单位token的推理成本。
SGLang HiCache和SWA(滑动窗口注意力)这两项技术最值得关注。简单来说,小米认为大模型推理过程中,成本最高的环节就是GPU显存里的KV缓存。
SWA技术让模型不需要为了存储几万字前文的信息占用大量显存,这也就能解释为什么小米这次敢取消上下文窗口长度的阶梯定价。再加上多级存储优化,把数据在显存、内存、SSD之间的搬运量降低到了原来的七分之一。
技术优势最终转化成了定价的灵活空间。
当小米能把缓存命中的开销降低到上一代模型的十分之一甚至百分之一时,降价99%就不是赔本做慈善,也不只是营销操作,而是释放技术红利,同时淘汰那些技术架构陈旧、降不下成本的竞争对手。
04
别把token当货币,智能本身才是价值
最后,不管是DeepSeek还是小米降价,所有AI行业从业者都应该注意到一个深层次的行业乱象。
现在的AI市场里,token好像被异化成了一种“计价货币”。过去两个月里,已经有企业开始考核员工“每月消耗了多少token”,开发者之间也开始比拼token使用量。
但这本身就是一个错误的认知:token不是通用货币,不同模型的token价值完全不一样。
比如GPT-5.5和Opus 4.7这类顶级模型,它们的token价值更高,是因为少量token就能完成复杂任务,生产力密度非常高。
而能力不足的模型,哪怕给你按亿算token,要是解决不了实际问题,它的生产力价值也接近零。
前段时间,国内外不少厂商趁着编程代理工具的热潮涨价,本质上就是利用token概念的模糊性浑水摸鱼,让不熟悉AI的用户误以为所有模型的token都是同价值的生产材料。
现在DeepSeek掀翻了原来的价格桌子,小米进一步锁死了价格空间。两家企业动作的本质,是让token回归了它本来的定位:作为一种廉价的“数字工业耗材”,它必须足够便宜,才能支撑AI应用的大规模落地。
大模型的第二次价格战已经悄然开启,这次价格被打下来之后,绝不会像上一次价格战结束那样轻易涨回去。对于那些还抱着高价不放、又拿不出顶尖能力的厂商来说,行业寒冬可能比预想中来的更快。

最后,小米公告里的结尾值得分享给每一个人:技术的价值,最终要体现在被使用的广度上。
当token不再昂贵,国产大模型才能真正从实验室的测试样本,变成每个人都能随时取用的数字基础设施,就像水和电一样。
而这场围绕智能价值的行业洗牌,才刚刚拉开序幕。
本文来自微信公众号“硅基星芒”,作者:思齐,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com