
智能体“烧Token”引算力危机,模型服务商纷纷调整套餐策略






本文来自微信公众号:特大号,作者:特大明白
近日,大模型第一股智谱发布的退款公告在行业内引发关注。公告显示,因算力紧张导致用户体验不佳,智谱决定为Coding Plan用户提供限时退款服务。这一举措并非个例,近期多家大模型服务商都在悄然调整Coding Plan策略,包括限购、停售、调整套餐配额等。背后的核心原因,是以“小龙虾”为代表的智能体对Token的巨大消耗引发了算力荒,让服务商难以维持原有的包月套餐模式。甚至用户简单的一句“你好”,都可能导致智能体消耗大量Token。

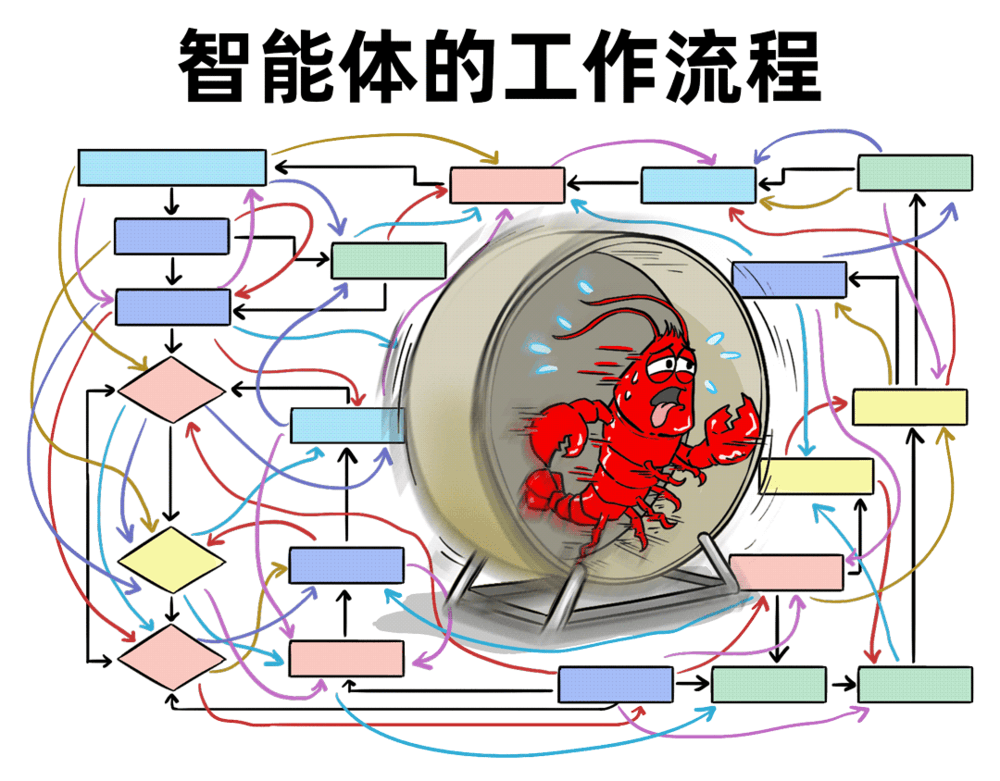
智能体为何如此消耗Token?
在人类看来,简单的对话如“你好”与“您好”仅需少量字节,但智能体的工作逻辑截然不同,其内部运行存在大量“隐性消耗”。
01 固定“起步价”高昂
普通AI聊天工具的“起步成本”几乎为零,而智能体如“小龙虾”的起步消耗却很高。用户发送“你好”二字时,智能体向底层模型传输的内容远不止于此——首先需要发送包含角色定位、功能说明的system prompt(类似“岗位说明书”),这部分内容会直接消耗大量Token,构成基础开销。

02 工具调用增加额外消耗
智能体如OpenClaw在调用工具时,不仅要向模型传递工具名称,还需附带工具的JSON schema(结构描述),以便模型理解调用方式。这意味着工具调用会产生两层Token消耗:工具列表文本和schema内容,且schema会被计入上下文,进一步增加成本。
03 技能清单的隐性开销
即使未实际调用某个技能,系统提示词中也会包含紧凑版的技能清单,说明各技能的功能。这部分内容同样会消耗Token,如同在“工具箱”之外额外携带“操作手册”,进一步推高Token用量。
04 历史对话反复加载
用户发送新消息时,智能体通常会将完整的历史对话重新带入上下文,以维持会话连贯性。会话越长,每次新消息的Token消耗就越高。即便对历史对话进行压缩或剪裁,仍需承担可观的成本。用户感受到的“智能联想”能力,实则是Token消耗的直接体现。
05 工具输出占用上下文窗口
智能体调用工具(如读取网页、文件、日志等)后,工具输出的结果和附件会持续占用模型的上下文窗口,成为“隐形消耗大户”。这些内容即使不再直接相关,仍会被计入Token用量。
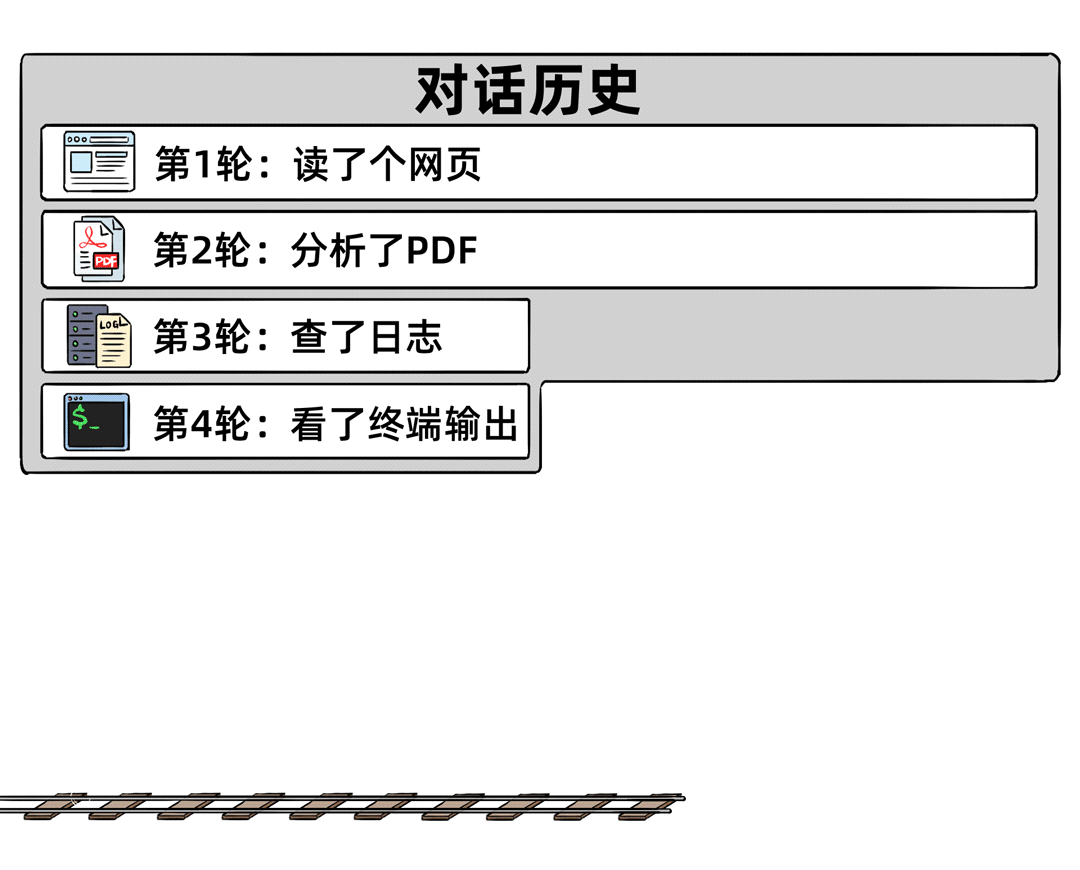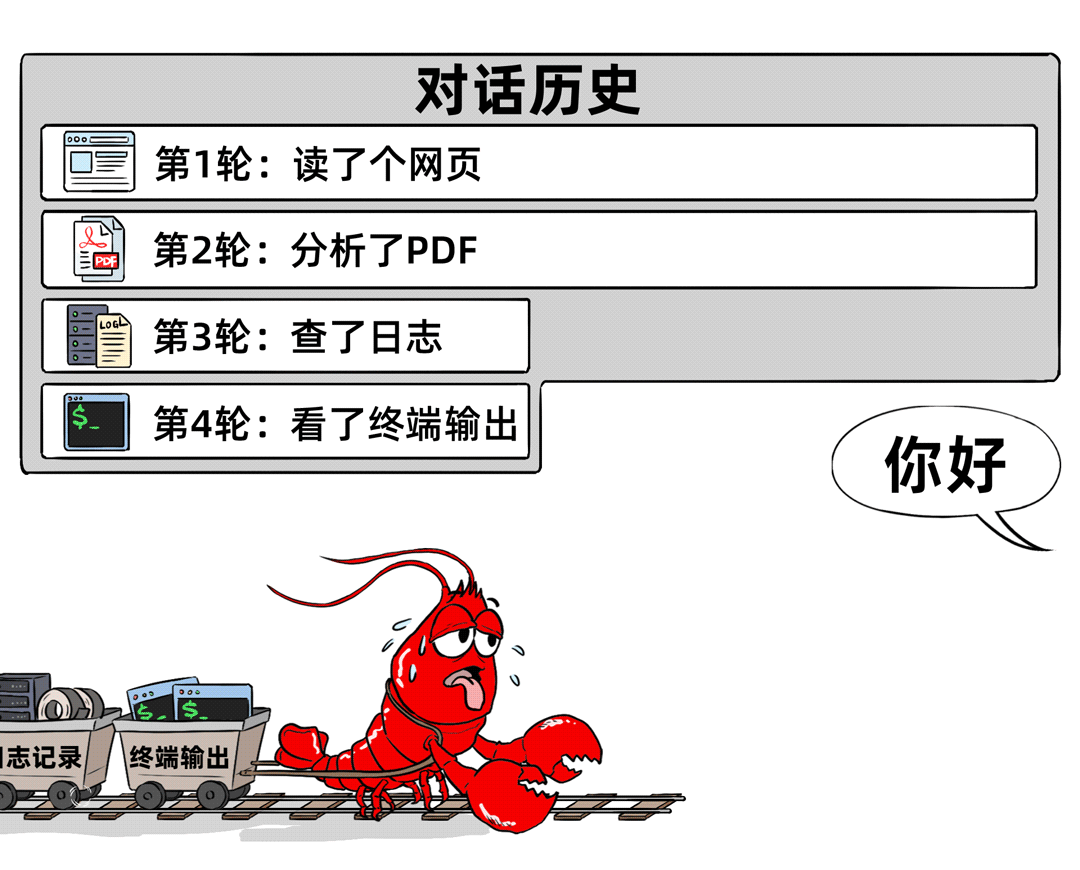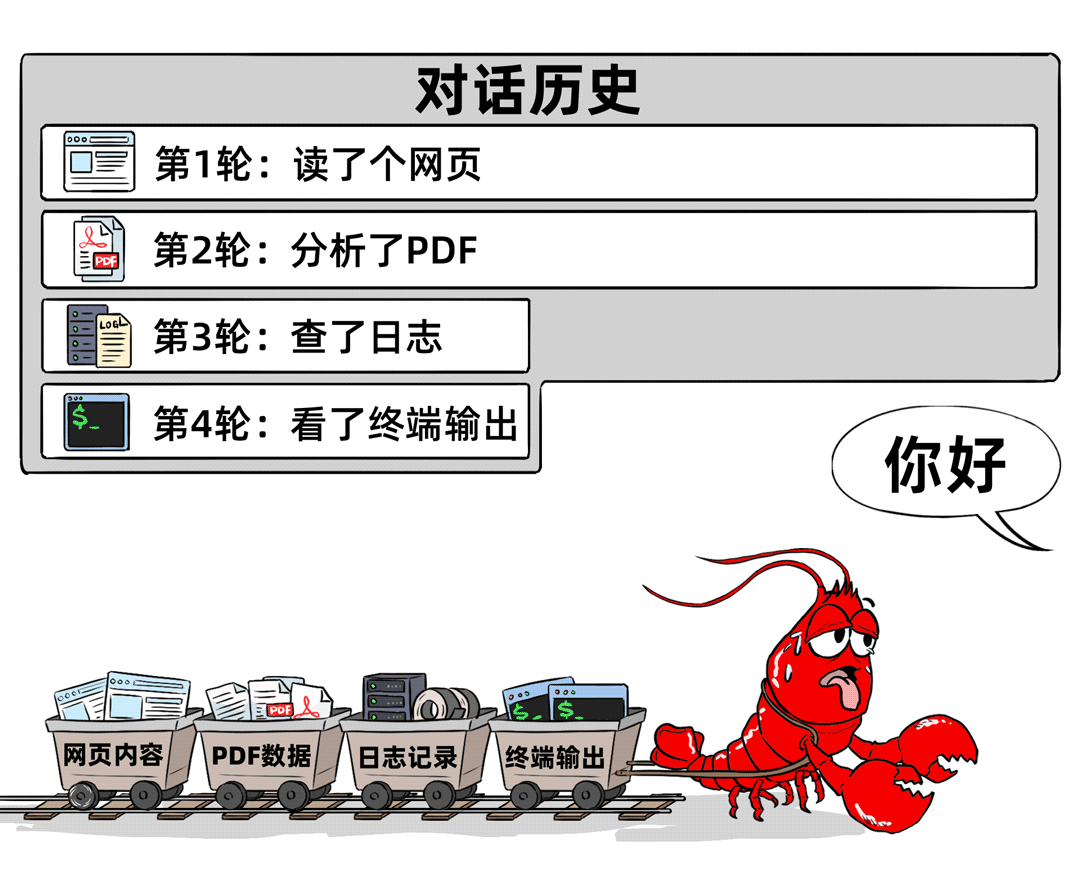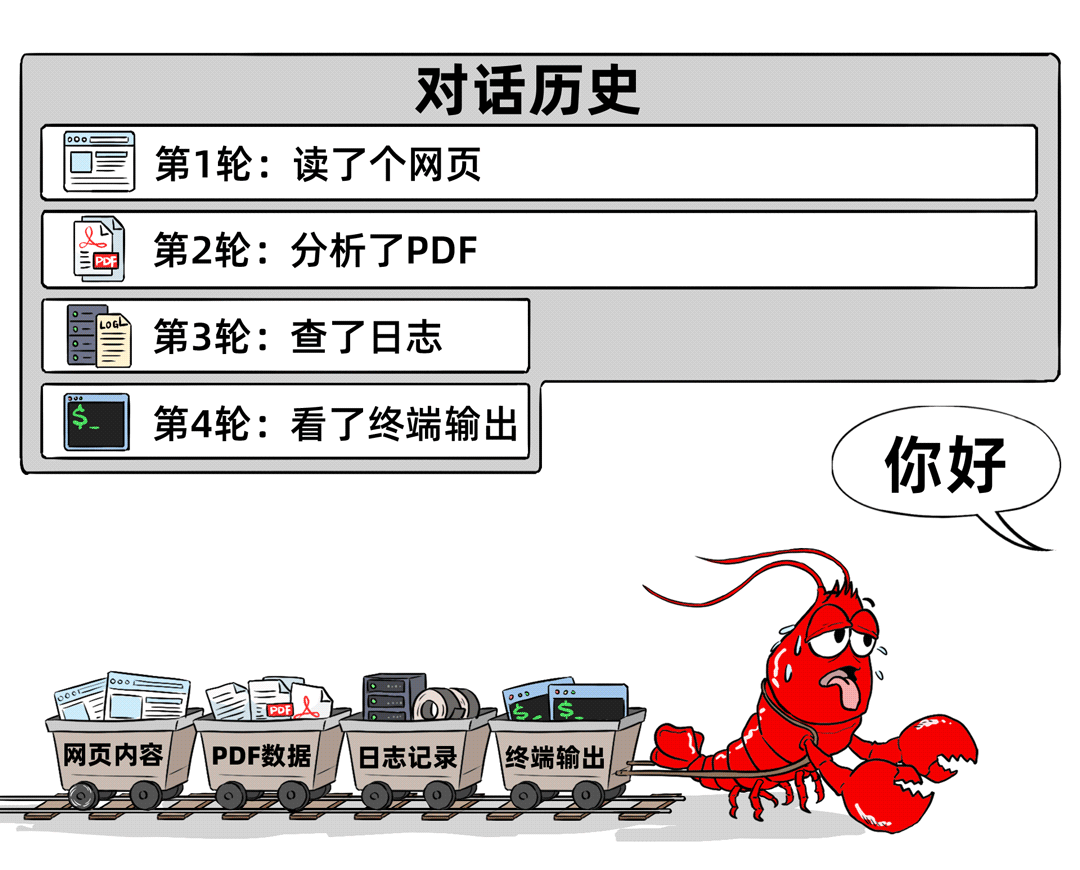
06 记忆文件加载的代价
为解决智能体“失忆”问题,用户常使用MEMORY.md等记忆文件。这些文件平时存储在磁盘中,但一旦需要加载到模型窗口,就会消耗大量Token。此外,智能体调用子智能体、模型选择不当导致的“弯路”、技能调用额外API等,都会进一步增加Token消耗。
智能体的工作流程本质是“大力出奇迹”:即使用户输入简短,系统内部也可能触发多步思考和多次模型调用。从消息标准化、系统提示词拼接(包含工具、技能、身份等信息),到会话历史、工具结果的整合,再到模型对输入意图的判断,每一步都伴随着Token消耗。例如,用户发送“谢谢”,智能体需完成全套流程后才会回复,过程中已消耗大量Token。
这种现象并非“小龙虾”独有,近期走红的Hermes等智能体也存在类似问题。为减少Token浪费,用户可养成以下习惯:
①减少寒暄,直接下达任务指令;
②使用精准完整的提示词,避免重复沟通;
③拆分大型文件(如日志、代码库),避免整份投喂;
④明确回复篇幅要求,减少冗余内容;
⑤不同任务切换会话,避免单一会话过长;
⑥及时删除无用工具和技能,简化功能;
⑦选择更智能的模型,减少无效消耗;
⑧简单任务(如翻译、修图)优先使用普通AI工具,避免浪费智能体资源。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com