
DeepSeek V4屡延发布,中国开源领军者缘何放慢脚步?






3月12日,白鲸实验室独家消息称,DeepSeek V4预计于4月正式上线。
消息一出,AI领域瞬间热议——“终于要来了?”“这次不会又是空谈吧?”。
之所以出现这种既兴奋又怀疑的复杂反应,是因为过去几个月里,DeepSeek的发布时间已被反复“预告”多次。
1月说春节前后,2月说中旬,3月又传本周上线,一次次让开发者翘首以盼。
然而,随着希望一次次落空,DeepSeek被网友调侃为“贾跃亭下周回国”式发布:
永远即将到来,却总差最后一步。

回想2025年12月1日DeepSeek V3.2发布的那天,堪称中国AI史上的高光时刻!
开源社区沸腾,全球开发者欢呼,中国力量首次在数学、代码基准测试中硬撼闭源巨头,被誉为“中国版OpenAI o1升级版”。
但如今,距离V3.2发布已过去整整3个月,V4却依旧“只闻其声不见其形”。
反观OpenAI几乎每月更新一次,Anthropic更是密集推出Claude 4系列,将“agent闭环”运用得炉火纯青。
DeepSeek到底怎么了?曾经的“火箭式迭代”为何突然刹车?
01 DeepSeek的步伐慢了
2025年是DeepSeek的“辉煌之年”。
V3系列、R1推理模型、V3.2-Exp(稀疏注意力)、V3.2正式版,平均1-2个月就有一次大更新。
数学/代码基准多次局部超越闭源模型,API价格极具竞争力,开源权重发布后甚至引发美股波动。
开发者们纷纷刷屏:“DeepSeek才是真正的王者!”“中国AI,终于将不可能变为现实!”
其App上线短短几个月,累计下载量突破1.1亿次,周活跃用户最高接近9700万!开发者的关注度被彻底吸引。
那个阶段的DeepSeek,就像一台不停运转的迭代机器,让整个行业感受到中国开源玩家的速度。
然而V3.2之后,DeepSeek仅有一些小调整:上下文扩展至1M、API微调等,没有新权重、无重大功能提升。GitHub和Hugging Face的新仓库停滞,API更新日志最后一条仍停留在2025年12月1日。
社区早已失去耐心。
DeepSeek V4的发布时间,从1月春节前后,到2月中旬,再到3月初,如今又到4月窗口,开发者已被反复吊足胃口。
而同期OpenAI和Anthropic却进入“月更模式”。
OpenAI:2025年4月推出o3/o4-mini,6月推出o3-pro,2026年进入GPT-5系列(5.3 Codex、5.4 Thinking),几乎每月都有模型、产品和接口同步更新。
Anthropic:2025年5月Claude 4首发,后续4.5/4.6密集落地,2026年2月同步推出Opus 4.6 + Sonnet 4.6,具备1M上下文、Agent长任务强化能力,从聊天机器人转向自主Agent。
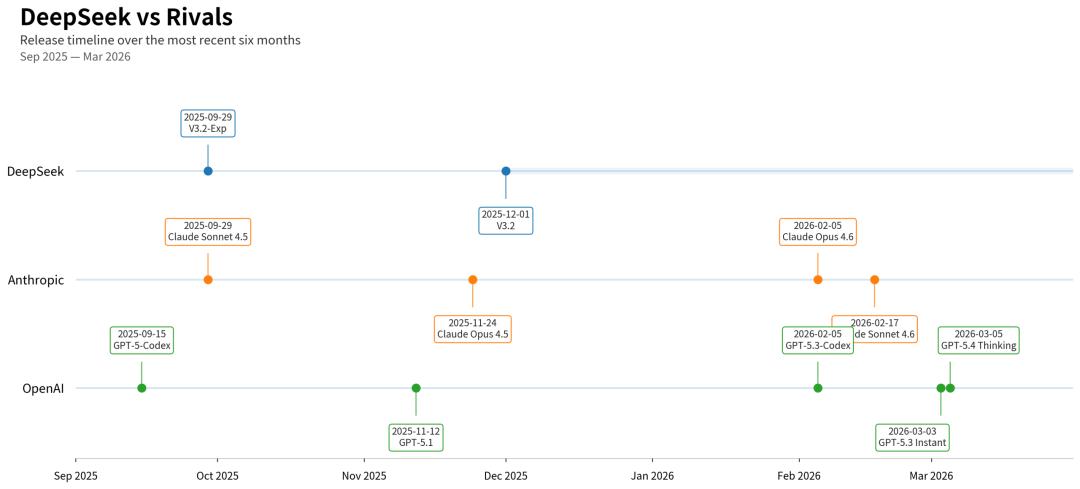
DeepSeek与对手发布频率时间轴图(2025.9-2026.3)
对比清晰可见:
2025年12月-2026年3月,OpenAI迭代4次,Anthropic迭代2次以上,DeepSeek大版本更新为0次。
曾经靠“火箭迭代”一路领先的DeepSeek,为何突然慢了下来?

02 DeepSeek放缓的背后
DeepSeek动作变慢,背后至少有三个原因。
从“模型发布”转向“系统工程”,难度大幅提升。
过去发布基础模型,重点在于参数、训练和基准测试。现在V4若要成为agent时代的主力,必须解决模型“能否连续执行任务”的问题。
DeepSeek V3.2已明确将重心转向工具使用和agent训练数据。官方提到引入了覆盖1800+真实环境、8.5万+复杂指令的agent训练数据合成方法。
这标志着DeepSeek已进入更复杂的阶段:不再是训练更聪明的模型,而是打造真正可执行的系统。
这与团队近几个月的研究方向完全一致:
梁文锋2026年1月署名论文《Conditional Memory via Scalable Lookup》提出条件记忆机制,2025年12月《mHC: Manifold-Constrained Hyper-Connections》优化Transformer记忆与长上下文瓶颈。
随着训练和验证复杂度呈指数级上升,模型迭代周期自然拉长。
DeepSeek的负担加重:开源明星的每一步都更艰难。
作为全球开发者眼中的“开源之光”,DeepSeek没有犯错的余地。
与OpenAI、Anthropic不同,DeepSeek背负着整个开源社区的巨大期望,任何一次平庸的迭代都会被视为“走下神坛”。
一旦性能不够突出,口碑反噬会更强烈;一旦过于激进,推理成本和部署门槛会劝退开发者;一旦权重、推理框架、工具链配套不到位,生态会迅速失望。
这让DeepSeek必须确保每次发布都有突破性进展。
在开源生态中,维持“代际领先”的压力远高于闭源巨头,因为你交出的是核心技术,而对手会根据你的技术调整策略。
如今DeepSeek仍是业界的“效率标杆”,市场期望是“用1/10成本达到GPT同等性能”。如果V4仅小幅提升性能却增加推理成本,DeepSeek的神话可能破灭。
因此,频繁小修小补对DeepSeek未必有利,一个没有明显代际优势的V4,反而不如不发布。
资源与组织的瓶颈可能正在显现。
2026年的大模型竞争已成为持续的工业化比拼,比拼的是算力持续供给、数据与后训练流水线、评测体系、工程团队规模、产品-用户-收入-再训练闭环。
OpenAI和Anthropic能每月更新,正是因为它们已形成强大的闭环体系。
例如,Anthropic将Claude 4重点放在编码、长任务、agent工作流和整套API能力;而OpenAI则同步推进模型、产品和API接口。
DeepSeek面临的挑战,不再是下一次能否刷新榜单,而是能否跟上工业化迭代速度。
更具战略意义的挑战在于硬件生态的重构。
据爆料,DeepSeek V4将深度适配国产芯片,有望成为首个完全运行在国产算力生态上的大模型。
在外部技术封锁与内部算力自主的双重压力下,这种从底层架构到国产硬件的“全面适配”,必然会延长研发周期。
这不仅是技术的博弈,更是对资源与工程能力的极限考验。

03 为何对手越来越快?
与DeepSeek的谨慎不同,美国巨头们正处于近乎疯狂的“月更模式”。
Anthropic尤为明显,近一年产品路线高度聚焦:编码、agent、企业工作流。
2025年5月Claude 4发布时,就直接将“长时间复杂任务”和“agent workflows”作为核心卖点,同时配套各种开发者能力。
Anthropic将有限资源集中投入最易形成壁垒的方向,因此更新节奏更清晰、落地更快。
OpenAI则是另一种快速模式。
它形成了平台化推进节奏:模型层小步快跑、产品层持续上新、API层不断增强,用户始终能感受到更新。
虽然两家打法不同,但结果一致。它们持续为开发者提供新功能,为企业赋予新能力,给市场带来确定感。
而DeepSeek的问题,恰恰是这几个月给外界的信号太少。开发者起初会等待,时间久了就会将注意力转向可上手的模型。
短期来看,DeepSeek与头部模型厂商的差距确实拉大了。
但值得注意的是,在基准测试层面,DeepSeek V3.2在数学/代码领域仍具竞争力;而V4传出的方向,也足够有冲击力。
爆料显示,梁文锋过去半年在弥补视觉内容处理和AI搜索短板,V4将聚焦多模态、长期记忆、代码能力提升,还将深度适配国产芯片。
3月11日OpenRouter上出现的Alpha模型,也让开发者提前感受到“多模态+长agent”的趋势。
如果V4真能同时实现多模态、长期记忆、代码能力和国产芯片适配,那么DeepSeek长期仍有竞争力。
4月发布窗口越来越近。
DeepSeek的“慢”,究竟是速度下降,还是蓄力待发,我们拭目以待。
本文来自微信公众号“世界模型工场”,作者:世界模型工场,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com