
黄仁勋的战略布局与DeepSeek的生态担当






本文来自微信公众号: 未尽研究 ,作者:未尽研究
英伟达推出了一款近乎完全透明的开源模型,将权重、数据集及训练方案悉数公开。而以DeepSeek为代表的中国开源模型,目前仅开放了模型权重。
2026年GTC大会将于下周一召开,继去年12月发布开源模型Nemotron 3 Nano(简称Nano)后,英伟达又推出了开源模型Nemotron 3 Super(简称Super),其开放性已然超越了DeepSeek。
黄仁勋此次可谓全力以赴。本周他还罕见地发布了一篇内部博文《AI是个五层蛋糕》,将AI产业划分为能源、芯片、基础设施、模型、应用五个层级。
他特意强调了开源模型的重要性:“全球多数模型都是免费的。研究人员、初创企业、各类企业乃至国家,都依赖开源模型参与先进人工智能项目。当开源模型达到技术前沿时,它们不仅会改变软件领域,还会激活整个技术栈的需求。”
他还以DeepSeek-R1为例:“该模型通过广泛应用强大的推理能力,加速了应用层的普及,同时增加了底层训练、基础设施、芯片及能源的需求。”目前,DeepSeek在中国正扮演着“激活整个技术栈”的角色,任重而道远。
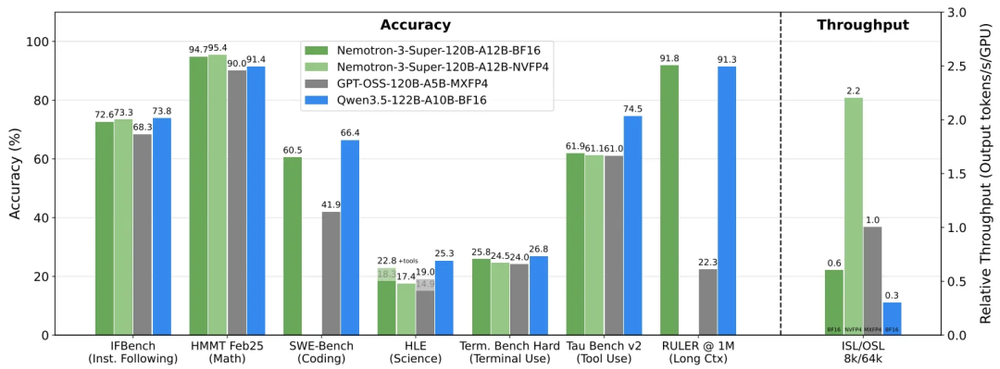
Nemotron 3系列的Super以及后续的Ultra,承载着黄仁勋的期望。Super总参数量达1200亿,在MOE架构下活跃参数为120亿。英伟达表示,它能在软件开发、安全故障排查等多智能体应用领域,实现效率与准确性的最大化。
Super支持百万token上下文,可助力智能体实现长期记忆,达成对齐与高精度推理。英伟达称,Super并非Nano的简单放大版,它引入了架构创新,能平衡高参数推理模型中常见的效率与准确性矛盾。
混合Mamba-Transformer主干网将Mamba层与Transformer层相结合,提升了序列处理效率并实现精确推理,使吞吐量、内存及计算效率均提高4倍。
Super在预训练阶段的大部分浮点乘加运算采用了英伟达的4位浮点格式NVFP4。该格式针对Blackwell架构优化,与FP8相比,在保持精度的同时,大幅降低了内存需求并加快了推理速度。
Super在多项智能体基准测试中准确率领先,吞吐量更是表现突出。
英伟达公布了Super的训练数据集:预训练包含10万亿整理token,额外加入100亿推理token及1500万道编程题;后训练数据集有4000万条新的监督与对齐样本,覆盖推理、指令遵循、编程、安全及多步骤智能体任务,用于监督微调、偏好数据及强化学习轨迹,其中约700万条直接用于SFT(监督微调)。
英伟达还公开了强化学习任务与环境:在21种环境配置和37个数据集上进行交互式强化学习训练(约10个数据集将发布),包括类软件工程师智能体训练任务及带工具增强的搜索与规划任务。这将训练从静态文本扩展到动态、可验证的执行工作流,训练过程中共生成约120万条环境rollout。
英伟达发布了Nemotron 3 Super从预训练到对齐的完整训练与评估方案,开发者可据此复现训练过程、针对特定领域调整方案,或作为自身混合架构研究的起点。
开源模型可分为权重开放、数据透明、训练流程开放三类。通常而言,公布训练数据意味着在研究可复现性上达到了更高的开源水平。
开放权重即直接发布模型权重,任何人都可下载运行,但训练数据与流程往往不公开。中国开源模型企业采取生态扩张优先策略,开放权重能让企业部署、开发者微调及本地推理,快速形成应用生态;在与闭源API竞争时,开放权重可帮助企业客户实现本地部署、成本优势与自主可控。
提高数据透明度涉及版权、网络抓取、合作数据等问题,公开这些数据需规避法律与商业风险。
对比Nemotron与中国的DeepSeek等模型:
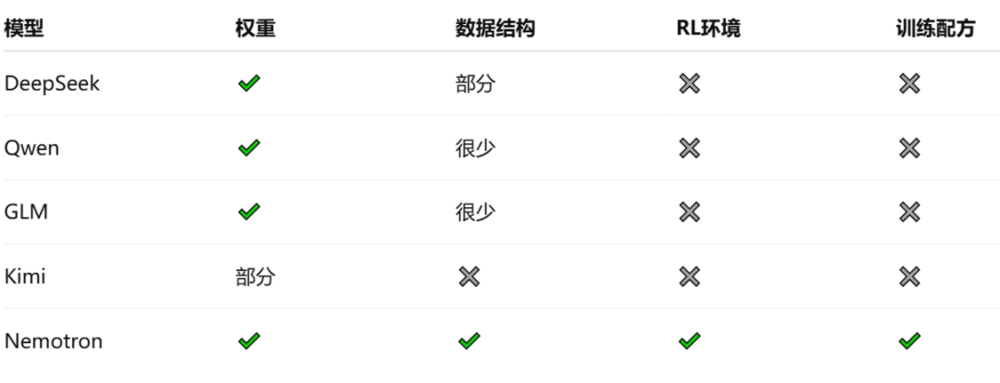
Nemotron是真正意义上的开源模型,它不仅是一个模型,更是一套“开源模型开发平台”。
由此可见,英伟达推出Nemotron不只是打造一个模型,更像是在推动围绕GPU计算体系的AI生态。
需明确的是:英伟达的核心商业模式并非售卖模型,而是算力平台。其收入主要来自GPU、CUDA软件栈、网络互连及数据中心系统。只要全球AI训练与推理规模持续扩大,就会带动更多GPU需求。因此,对英伟达而言,关键并非某个模型是否领先,而是整个AI生态是否继续依赖GPU计算体系。
在黄仁勋的“五层蛋糕”理论中,发布Nemotron这类开源模型具有多重战略意义。
首先,将开源作为GPU销售的强力杠杆,这是核心所在。英伟达不卖模型,而是芯片与计算基础设施。
Super通过NVIDIA NIM打包,可在工作站到云端等多平台运行,支持vLLM、Google Cloud Vertex AI、Oracle Cloud、CoreWeave等众多平台。模型越开放、部署越广,运行模型所需的H100/H200/Blackwell GPU销量就越高。
其次,以架构创新绑定自家硬件。Super是Nemotron 3系列中首个融合LatentMoE、多token预测(MTP)层与NVFP4预训练的模型,其中NVFP4是英伟达Blackwell架构独有的数值格式——原生NVFP4预训练专为NVIDIA Blackwell优化,大幅降低了内存需求。
也就是说,尽管模型开源,但在英伟达GPU(尤其是最新Blackwell)上的性能远超其他平台。开源方案实际上在全球范围内“传授”了一套天然向英伟达硬件倾斜的技术路线。
最后,以“比DeepSeek更开放”抢占技术话语权。英伟达此时以高度透明的姿态进入,是向全球开发者社区传递信号:最领先的模型技术来自美国、来自英伟达生态。
Nemotron 3包含针对现实世界智能体任务的多环境强化学习,相关RL环境与数据集对开发者开放,用于领域定制与可复现性研究。这种透明度会快速聚集全球研究者与企业开发者,围绕英伟达生态构建论文、工具链与社区,形成对竞争对手的软性护城河。
开源加速了模型的商品化,真正有价值的变为底层计算平台与系统架构,而这正是英伟达最擅长且希望掌控的领域。
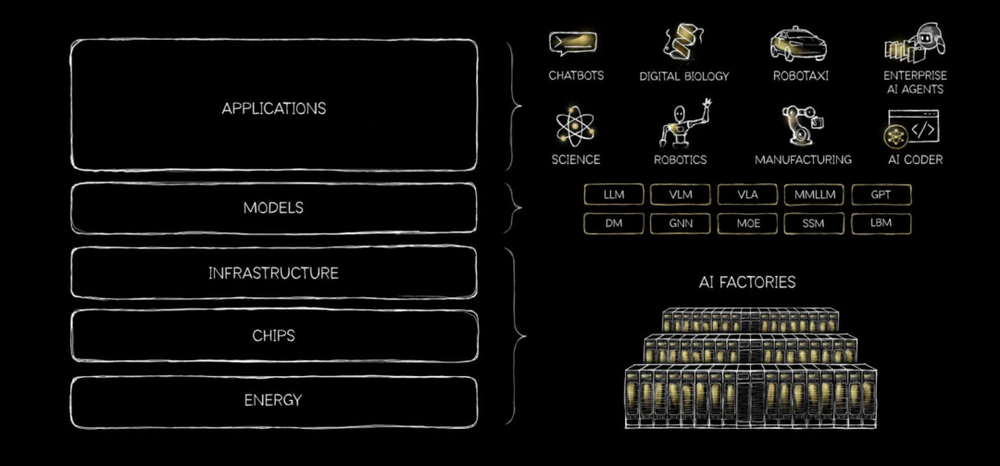
这也表明AI产业正从模型竞赛转向平台竞赛。未来的竞争很可能不是谁拥有最强模型,而是谁能构建完整、高效、可扩展的AI计算与应用生态系统。
如此看来,仅专注于模型而不涉及应用的DeepSeek,其关键或许并非简单发布DeepSeek-4——单个模型在中国也难以摆脱商品化——而是它在中国AI计算与应用生态中所发挥的作用。
DeepSeek主动适配国产芯片,相当于为整条国产算力供应链提供背书与激活。每一位基于DeepSeek开源版本开发应用的中国开发者,都会将算力需求导向国产硬件,这对华为昇腾、海光、寒武纪、摩尔线程、燧原等企业而言价值重大。
DeepSeek-4的推出,确实需要一定时间。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com