
Claude全球宕机背后:AI基础设施的系统性脆弱性暴露
03-04 06:48







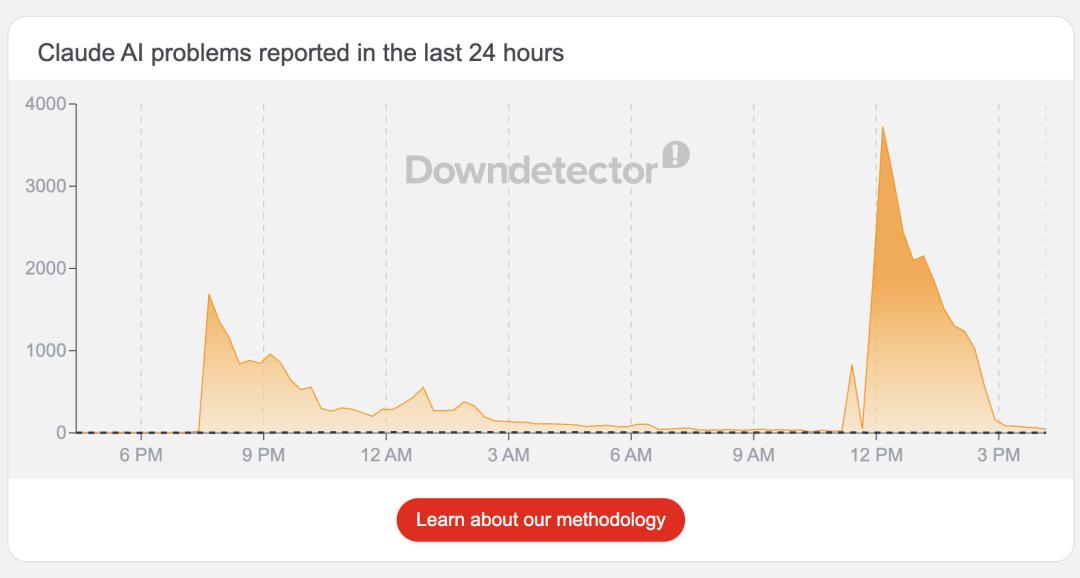
北京时间2026年3月2日晚19点49分,Anthropic旗下的AI助手Claude在全球范围内突发大面积服务中断。无论是claude.ai网页端、开发者控制台,还是AI编程工具Claude Code与移动端应用,几乎同时出现故障提示。数千名用户涌向Downdetector平台报告问题,高峰期报障量达数千条。用户登录时,屏幕上显示的要么是HTTP 500、529错误码,要么是一句简短的提示:“Claude will return soon.”

01 “打地鼠式”的宕机过程
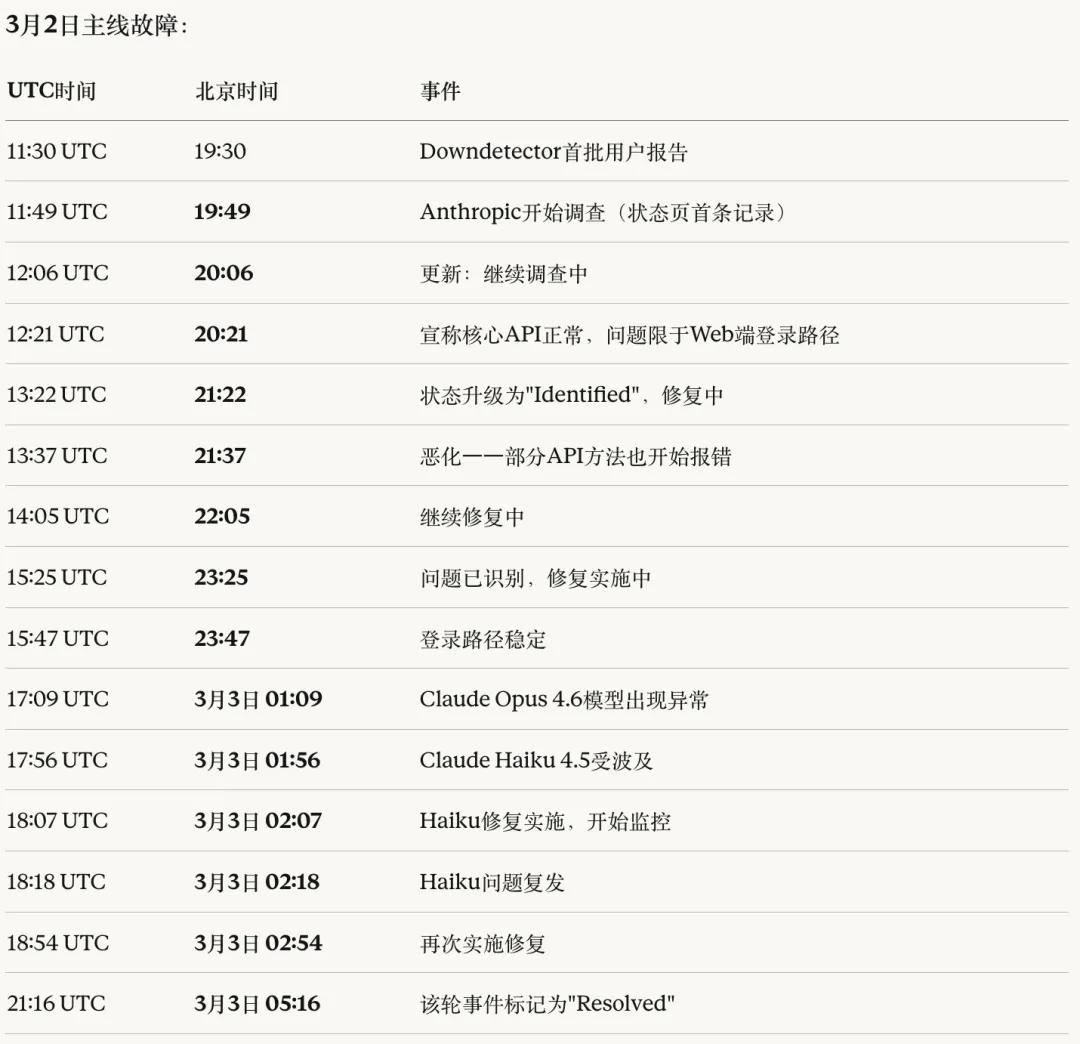

02 下游生态的连锁反应
03 AI基础设施的脆弱性
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com