
苹果新研究:AI 靠文本描述零样本识别 12 种活动,或用于 Apple Watch





IT 之家 11 月 22 日消息,科技媒体 9to5Mac 于 11 月 21 日发布博文,报道称苹果在最新公布的研究报告中指出,大语言模型(LLM)可通过分析音频和运动数据的文本描述,精准识别用户活动,未来该技术可能会应用于 Apple Watch 上。
名为“后期多模态传感器融合”(Late Multimodal Sensor Fusion)的这项技术,主要是将 LLM 的推理能力与传统传感器数据相结合,即便在传感器信息不足时,也能准确判断用户正在进行的具体活动。
该研究的核心方法十分新颖。大语言模型并不直接处理用户的原始音频录音或运动数据,而是对专门的小型模型生成的文本描述进行分析。
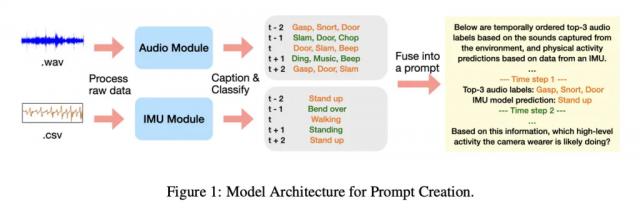
具体而言,音频模型会生成描述声音环境的文字,例如“水流声”,基于惯性测量单元(IMU)的运动模型则会输出动作类型的预测文本。这种方式既保护了用户隐私,又验证了 LLM 在理解和融合多源文本信息以进行复杂推理方面的强大能力。
为验证该方法,研究团队采用了包含数千小时第一人称视角视频的 Ego4D 数据集。他们从中挑选出 12 种日常活动,如吸尘、烹饪、洗碗、打篮球、举重等,每段样本时长为 20 秒。
之后,研究人员把小模型生成的文本描述输入到谷歌的 Gemini - 2.5 - pro 和阿里的 Qwen - 32B 等多个大语言模型中,并测试其在“零样本”(无任何示例)和“单样本”(提供一个示例)两种情况下的识别准确率。
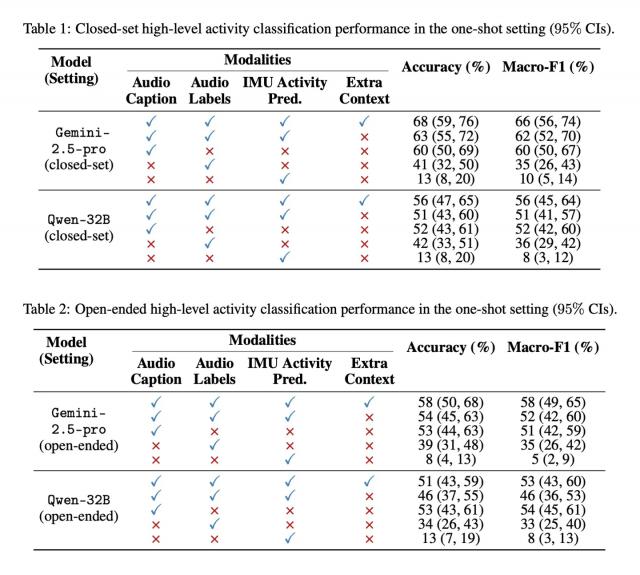
测试结果显示,即便没有进行任何针对性训练,大语言模型在活动识别任务中的表现也远高于随机猜测的水平,其 F1 分数(衡量精确率和召回率的指标)表现出色。当获得一个参考示例后,模型的准确度还会进一步提高。
这项研究表明,利用 LLM 进行后期融合,能够有效开发出强大的多模态应用,无需为特定场景开发专门模型,从而节省了额外的内存和计算资源。苹果公司还公开了实验数据和代码,方便其他研究者复现和验证。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com