
亚马逊云服务宕机:数字化世界的脆弱警钟






云塌的那一刻,我们才惊觉数字化的世界竟如此脆弱。猫咪无法进食、多邻国打卡成泡影、金拱门外卖无法下单……甚至早上醒来,想眯着眼刷会儿Snapchat,看到的却是永远的“连接失败”。切换到Venmo想付室友外卖钱,卡在支付页面转圈圈;打把《部落冲突》清醒一下,游戏匹配界面卡在“正在连接”,半天没反应。小猫在门外嗷嗷叫,开门一看,自动喂食机一夜没出粮。叫Alexa放首歌,它只回了句“抱歉,无法响应”。
这些不相干的糟心事,背后都是亚马逊云宕机惹的祸,就像一场“赛博世界末日”的预演。

这时,门口有响声,到门前一看,Ring门铃的摄像头也失灵了,连昨晚的监控视频都没录下。门突然被打开,原来是室友。他哭丧着脸说:“AWS挂了,机场的调度系统死机了,我回来的飞机在跑道上排了两个小时!”
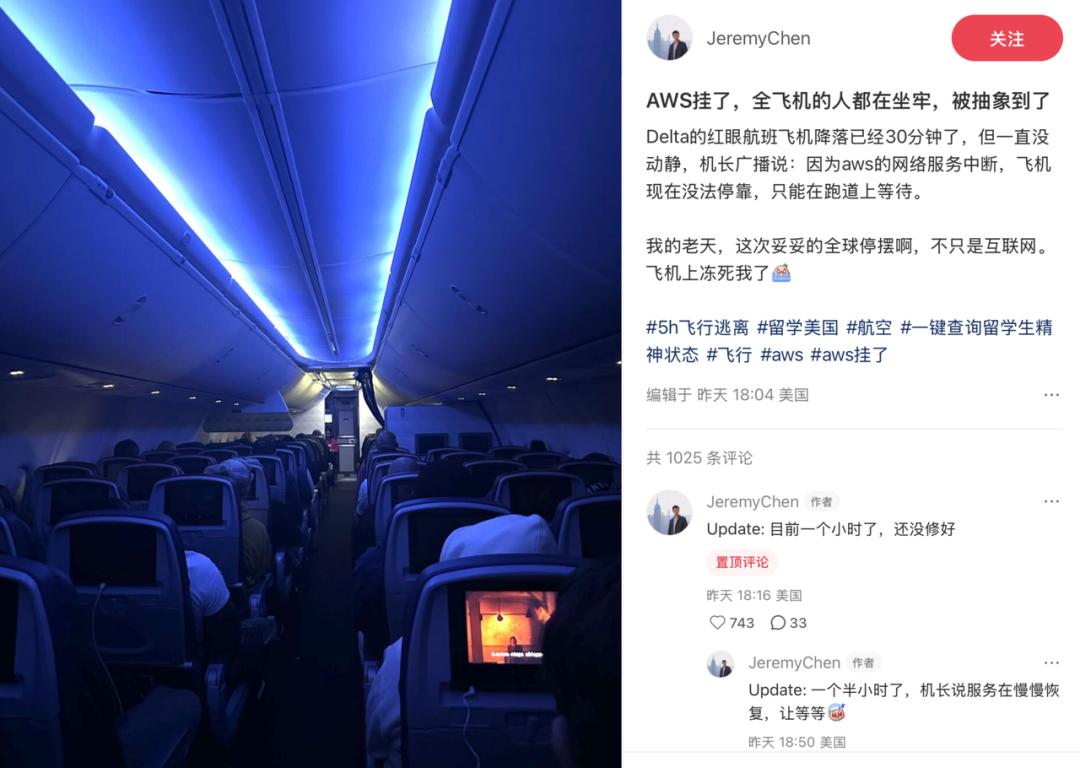
这不是科幻末日电影里的场景,而是昨天无数人的亲身经历。
脆弱的数字化世界
一切的罪魁祸首是亚马逊的AWS云服务。这个支撑着全球三分之一互联网基础设施的“隐形巨人”,在美东当地时间10月20日凌晨3:11(北京时间15:11),US - EAST - 1(美国 - 东部 - 1)多个服务出现“错误率增加和延迟”。一小时后的4:26,故障急剧升级,流量均衡器崩溃。短短数小时内,从日常社交软件、在线游戏、智能家居,到大企业、金融机构、教育平台,皆在这一刻“掉线”。

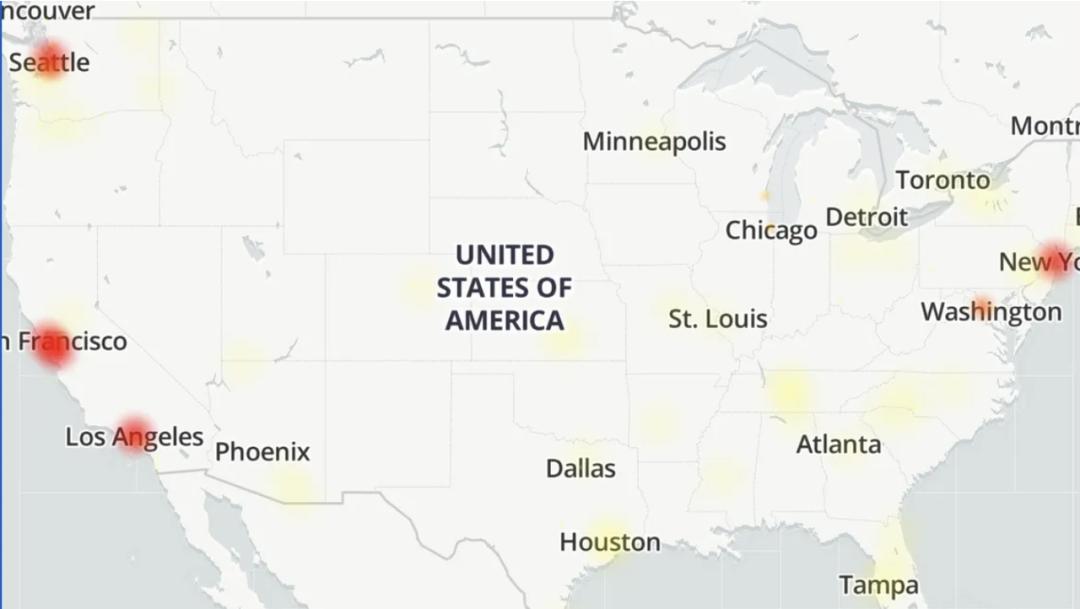
影响巨大丨Down Dectector
互联网流量监测平台Down Dectector数据显示,有超过2500家公司受到影响,超过1100万条用户在此期间汇报了各种服务中断的问题,全球数百万网民的数字生活被按下暂缓键。
先说社交媒体和即时通讯,Snapchat、Signal都出现了服务问题,数百万用户发不了消息,刷不了Stories,甚至许多用户因反复尝试登陆,导致账号被锁定。游戏玩家们也“躺枪”,《堡垒之夜》《罗布思乐》等热门在线游戏,服务器挂机,玩家要么登录后黑屏,要么战斗中途掉线。Steam、Xbox、PSN、育碧的部分服务器也受影响。
其他常用工具也没幸免。语言学习app多邻国、约会App Hinge、出行服务Lyft,还有社交论坛Reddit都报告了不同程度的故障:Reddit刷不出贴,Hinge用户抱怨匹配页面加载失败,Lyft打不到车,多邻国打不了卡。

玩不了游戏,发不了消息,正好放下手机“数字排毒”,但赚不了钱才是真要命。Venmo宕机,用户无法付款和转账,小企业主欲哭无泪;Coinbase加密交易所中招,用户登录卡顿,交易订单堆积如山;Robinhood和Webull等股票app全线崩溃,投资者眼睁睁看着市场波动却下不了单;同时,星巴克、麦当劳的app也出现了访问问题。
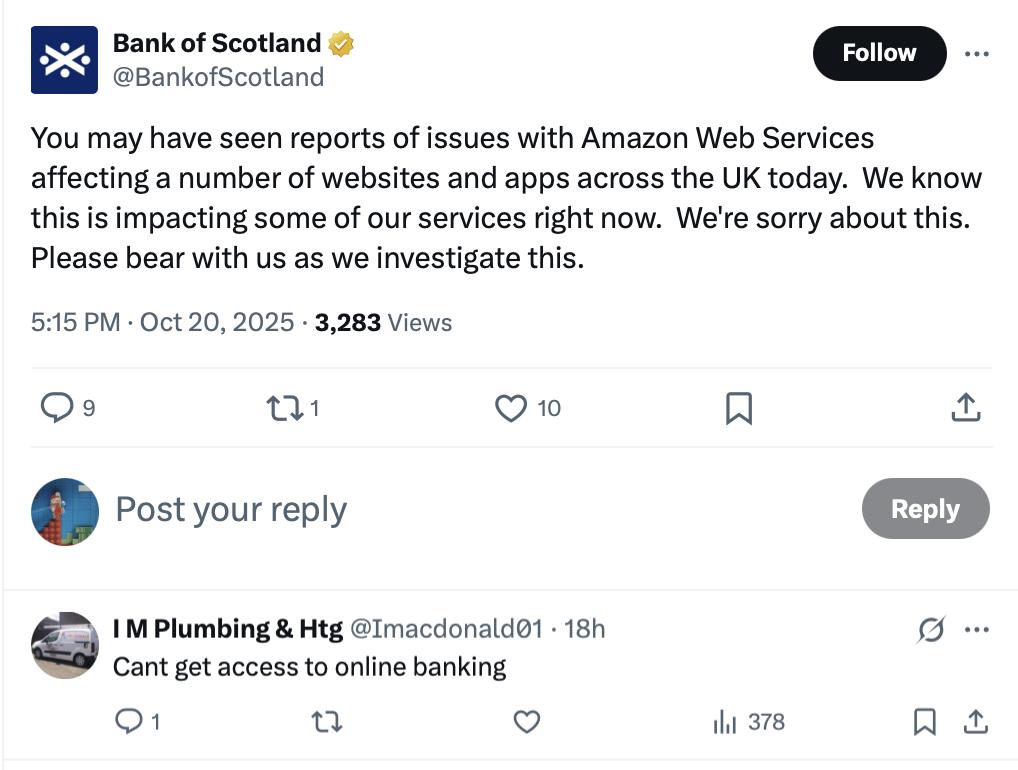
政府机关也受到影响,苏格兰银行发帖称“AWS影响了英国许多网站和程序,包括我们的服务”,用户用不了网上银行。英国税务、支付和海关当局的网站也都掉线。
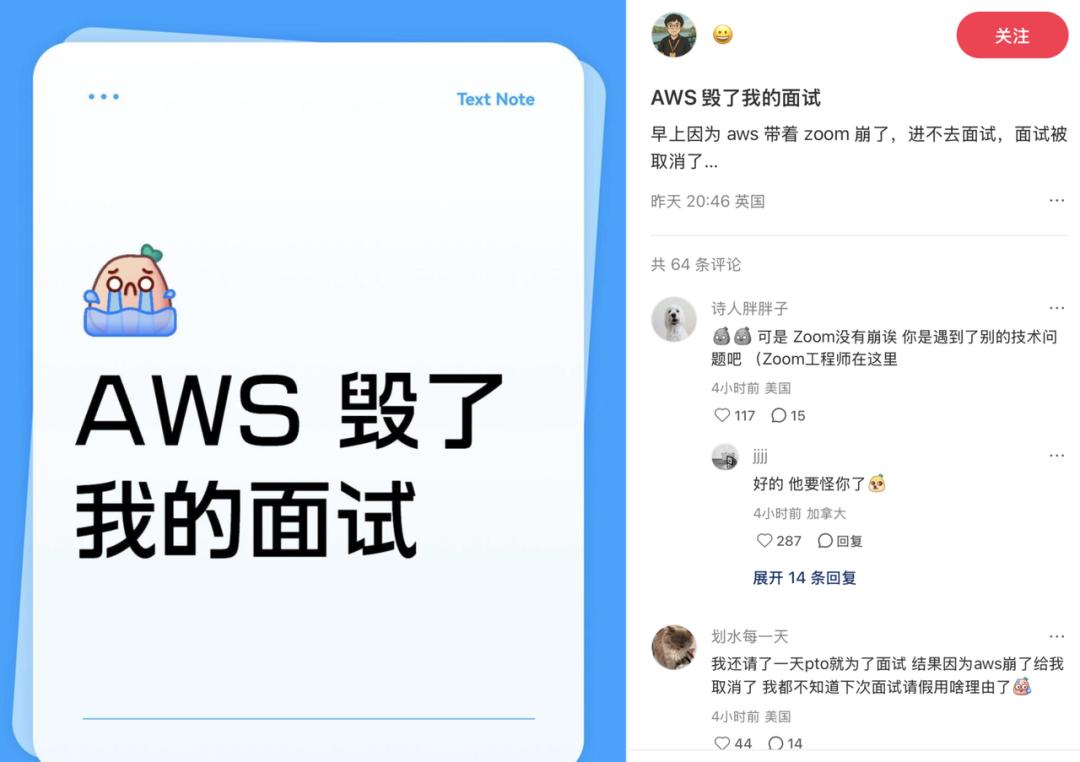
企业级影响同样惨烈,Zoom会议断断续续几乎不可用,Canva错误率飙升,设计师们无法导出海报,项目延误;教育平台Canvas瘫痪,学生上不了网课,交不了作业;政府网站如部分联邦服务也短暂下线,健康保险网站能登录,但拉不出理赔记录。
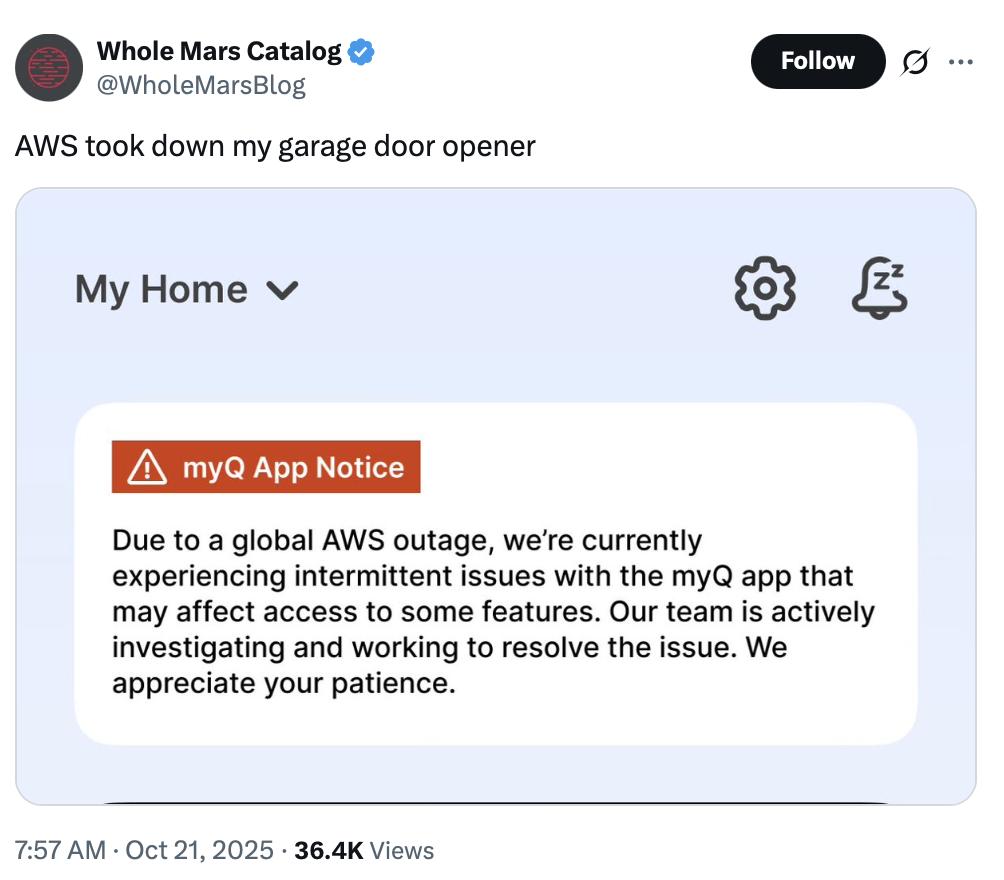
智能家居也是受害者重灾区。亚马逊自家的Alexa语音助手停摆,语音控制家电成空谈,有网友称“Alexa闹钟一响就关不掉”,评论区网友跟帖:“我家Alexa和Echo都挂了,定的闹钟一点没响”。
Ring智能门铃服务挂了,用户看不了监控,甚至打不开房门。还有用智能车库的特斯拉车主,打不开车库门。就连美联航的机场调度系统都受到了影响。
迪士尼+、Apple TV、Prime Video、Netflix、Twitch都遭遇大规模无法连接或卡顿问题。之前人们用“蝴蝶效应”形容复杂系统的脆弱性,如今,这只蝴蝶换成了AWS的服务器,只要它在弗吉尼亚的机房里轻轻“抽风”一下,半个互联网的屋顶就会塌,无数网站、app、物联网设备、支付系统像多米诺骨牌,全线塌陷。
生活在云端
当你看到这里时,AWS的服务器已经修复,但网友们还陷在那几个小时无限加载的恐慌里:原来支撑现代生活的那张数字之网如此脆弱?要理解这次大规模故障,首先得认识一下AWS是什么。
AWS,全称Amazon Web Services,它是亚马逊旗下的云计算服务平台,也是一个数据中心、服务器机群和网络节点遍布全世界的巨型网络服务平台。它就像现代互联网의“电网”和“水管”,我们并不直接看到它,但几乎所有的数字生活都靠它运转,是互联网最重要的“基础设施”之一。全球上百万家公司把网站、应用、数据库都托管在AWS上。

而这次出问题的“US - EAST - 1”区域,是AWS在弗吉尼亚州北部的旗舰数据中心集群,也是它全球业务的核心节点之一。业内人士分析,这个区域承担着过高的负载,很多全球知名网站、金融系统、API服务都默认部署在这里。
根据亚马逊的初步解释,事故源于内部一个监控网络负载均衡器的关键系统出错,引发大面积连接失败。通俗点说,即DNS解析出了岔子,系统找不到正确的“地址”,各大网站就像看不到收货地址的外卖员,手里拿着饭却不知道该送给谁。这本是可控的小故障,但在修复过程中又触发了“级联效应”:为了止损,工程师关闭了一部分入口,却导致新的服务器无法接入,流量分配再次紊乱。越修越乱,一环扣一环,就像一场小车祸让整个市中心大堵车。
截止到当地时间下午6时左右,亚马逊旗下服务健康仪表板更新显示,其服务已“恢复正常运行”。
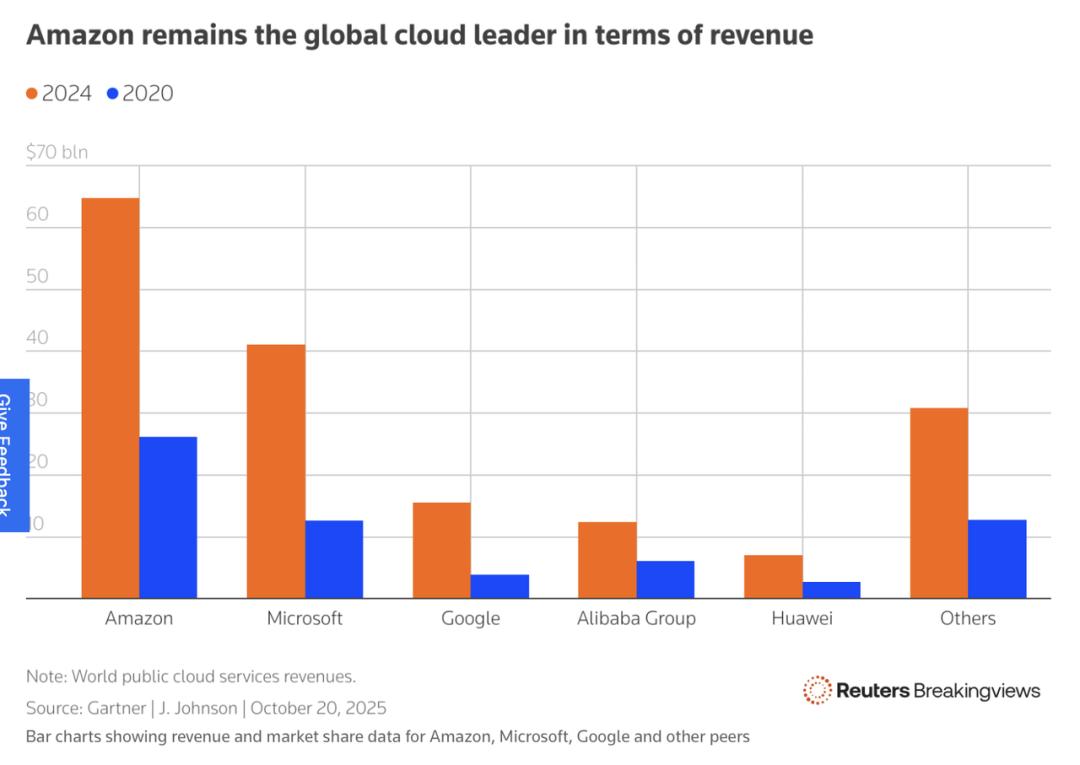
“蝴蝶效应”为何会引发?核心原因在于云计算的“集中化魔咒”。AWS是云市场的“老大”,占全球30%的份额,而US - EAST - 1是它的旗舰区域,亚马逊在这里砸了500亿美元建数据中心,吸引了无数企业“安家”。根据AWS网站上的文档,US - EAST - 1站点是许多AWS服务的默认站点。为了省钱和便利,很多公司把核心数据全堆在这里,没做足够的“多区域备份”,就像把所有鸡蛋放一个篮子,篮子晃一下就全碎了。同时,AWS的系统就像一座极其精密咬合的机器,任何一个子系统的异常,都可能像倒下去的一块多米诺骨牌,让整个系统短暂崩溃。强大来源于高度整合,而脆弱也是因为过于集中。
这次短暂的宕机也让无数公司和网友意识到,我们的生活、公司、政府服务是不是过于依赖某家公司的服务。互联网的理想是分布式与开放,但现状却是集中与垄断。我们所认为“随时可用”“永远在线”的背后,就是一张由少数几家巨头所搭建的网络。一次短暂的宕机,为我们敲响了警钟。
本文来自微信公众号“果壳”(ID:Guokr42),作者:糕级冻雾,编辑:沈知涵,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com