
斯坦福新论文:揭秘大语言模型心智理论基础







如果你好奇没有情感和经历的AI如何学会“察言观色”、理解人类意图,这篇文章会给出清晰答案,它解释了被认为是人类专属的“心智”能力如何从最简单规则中诞生。
从去年起,Anthropic的系列研究揭开了大模型”心理学“序幕,让人们了解到模型可能有欺骗、自保等看似有”自主意识“的行为。
Anthropic曾开发“Circuit Tracing”(工作回路追踪)方法,剖析模型判断时神经信号传递规律,但行业在大模型心理解剖学上进展仍处于初级阶段。
近期,斯坦福大学发表在《nature》子刊《npj Artificial Intelligence》的论文《How large language models encode theory-of-mind: a study on sparse parameter patterns》,采用更间接研究方法,更清晰描绘了AI认知能力解剖学。

论文研究的认知能力是“心智理论”(Theory of Mind),长期被认为是人类独有关键特质,指个体“理解他人内心想法、意图与信念”的能力,是构建人类社会认知、实现情感共鸣与顺畅社交互动的基石。
如今,越来越多的Benchmark和测试表明,LLM似乎开始掌握这项能力。这个原属人类或其他高等生物认知的特有现象,为何会发生在硅基智能上?
论文研究者发现,驱动模型复杂社交推理能力的根源,并非分散在整个庞大神经网络,而是集中在仅占模型总参数0.001%的一小撮“神经元”上。
更重要的是,论文揭示的不仅是人工智能新秘密,还清晰展示了智能从最基础秩序中涌现的动力学原理。
1
一台机器也有心智剧场
“心智理论”(Theory-of-Mind, ToM)最早由心理学家大卫·普雷马克在研究黑猩猩时提出,指个体推断自身与他人心理状态(包括信念、意图、欲望和知识等)的能力,是理解他人言外之意、有效沟通、形成社会纽带的核心。
人类心智发展中,约四岁孩童会迎来决定性时刻,开始理解别人想法可能与自己不同且可能错误,这是“心智理论”觉醒标志。
科学家常用“错误信念”测试评估这种能力。论文中描述了一个场景:桌上有精美巧克力袋,山姆看到并读标签,相信里面是巧克力,但实际装的是爆米花。
此时,具备心智能力的人会被问两个问题:一是袋子里真实装的是什么(爆米花);二是山姆认为袋子里有什么(巧克力)。能区分客观现实与他人主观信念,是心智能力核心体现。

过去认知测试中,这些问题能有效筛查心智发育进程。
然而,研究人员将问题抛给Llama、Qwen等最新一代大型语言模型(LLMs)时,它们大多能像心智成熟的人一样准确回答。它们似乎能“代入”故事角色视角,理解信息差并做出合乎逻辑的推理。
这些模型没有真实生活体验、情感、意识,也未经历心理学上自我觉醒的“镜面阶段”,它们对情景和主体的“理解”从何而来?
2
解剖一个数字幽灵
为揭开这个“黑箱”,斯坦福研究团队深入“神经回路”探险,试图找到并解剖负责心智能力的功能器官。
研究团队运用基于“Hessian矩阵”的敏感度分析方法,精确测量模型每个参数对特定任务的重要性,目标是找到控制心智能力的总开关。
经精密计算和筛选,他们发现,在数十亿甚至更多参数的庞大模型中,驱动ToM能力的关键参数仅占0.001%。这是极其稀疏、高度集中的“心智核心”,颠覆了许多研究者关于高级能力在神经网络中“广泛分布”的传统认知。
论文指出,这些参数并非随机分布,而是呈结构化低秩特性,主要集中在与注意力机制直接相关的查询(Query)和键(Key)矩阵中,这暗示模型社交推理能力与核心信息处理中枢注意力机制有直接物理联系。
识别出0.001%的“心智核心”参数后,研究人员设立对照组。他们发现,扰动这些参数时,Llama和Qwen这类使用RoPE架构的模型,心智能力会崩溃。
将同样“手术”应用于不使用RoPE的Jamba模型,其心智能力未受影响,说明这种脆弱性与特定技术选择RoPE有关。
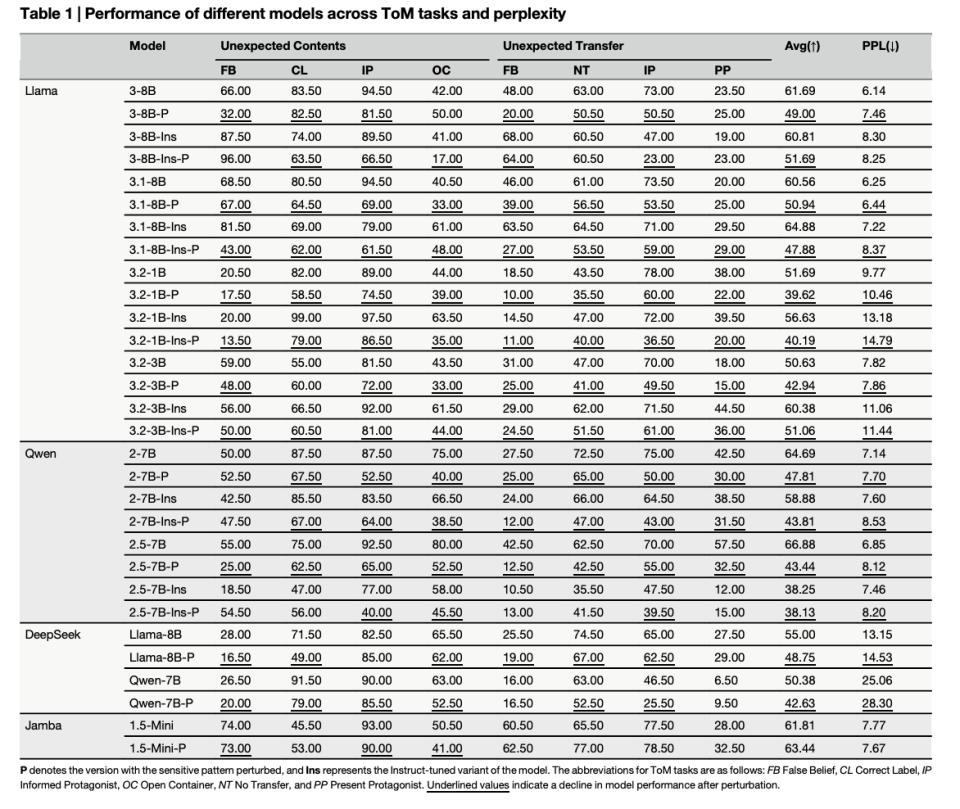
RoPE的作用是,语言是序列,词语顺序定义意义,RoPE为每个词的位置赋予独特旋转操作。如词在句子第一个位置时,位置是90度,不旋转;在第二个位置时,旋转小角度;在第三个位置时,再旋转小角度,以此类推,每个词在上下文中的相对位置被精确编码在RoPE展示的角度标签里。
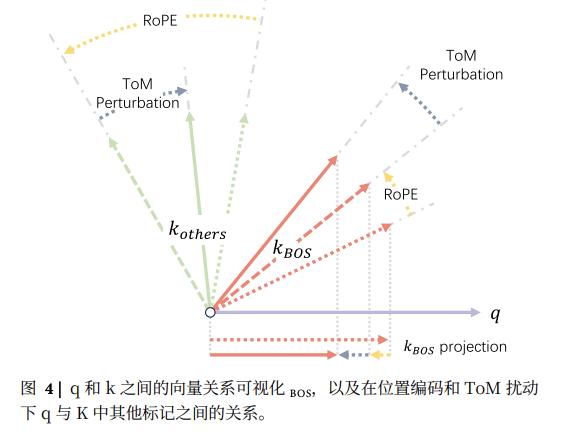
论文发现,RoPE运作依赖特定“主导频率激活”模式。RoPE给词做角度标记时,有的词旋转幅度大,为高频维度,用于承载最重要上下文顺序信息。
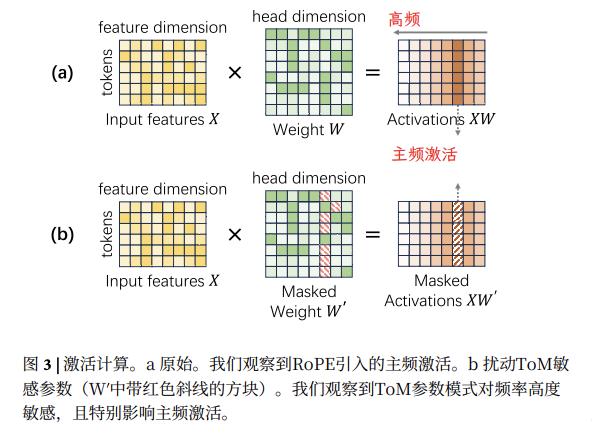
研究人员进一步搅动比较发现,稀疏的“心智核心”参数在模型中的作用与“主导频率”模式精确对齐。
因此,搅动这部分参数后,使用RoPE的模型丧失“上下文定位能力”,语言结构在其“眼中”模糊,扰动破坏几何关系,导致注意力分散到不相关信息上,瓦解了模型连贯理解能力。
而在Jamba中扰动心智参数,不会通过位置编码影响其上下文定位能力,也就不会导致心智能力突然衰退。
这至少为解释模型心智能力找到底层基础,即对句子前后位置的理解。
3
重构心智能力的基础
这项对“硅基大脑”的研究,展示了如“心智理论”般复杂的智能如何从最基础规则中涌现。
首先是搭建智能基石的语序。论文解剖模型心智参数得出,对序列和结构的精确把握是所有高级认知能力的绝对前提。
模型需要像RoPE这样强大稳定的内部“GPS系统”,构建有序、可依赖的语言世界模型。没有对“谁在先、谁在后”、“谁对谁做了什么”等基本位置关系的精确理解,后续推理无法进行。
第二步,是在秩序之上学习世界的规律。
在秩序搭建的坚实骨架上,模型通过对人类语言文本进行统计学分析,发现并内化语言中蕴含的世界规律。
如文本中,动词时态变化(如puts变为moved)和时间副词(如before、later)的出现,与事件在时间轴上的先后顺序高度相关。某些事件描述(如“玻璃杯掉到地上”)常出现在另一些事件(如“玻璃杯碎了”)之前。这些文字模式构成模型对因果关系模拟的基础。
虽然模型可能并非真正“理解”时间和因果,但通过语序根基,能学习到这些概念在人类语言中的“统计学投影”。
之后,便是智能的“涌现”。
最终,论文作者认为,心智能力可能不是孤立认知模块,而是“模型在掌握词语定位和意义构建等通用机制时产生的涌现属性”。
当模型对语言底层结构(秩序)、中层规律(时间与因果)掌握足够好时,自然获得更高级推理能力,能根据语序为不同角色模拟可能与客观现实相悖的“信念路径”。
这其中存在潜在Gap,因为模型要有心智能力,需在预训练中学会隐含统计学规律:一个角色的知识和信念受其感知范围限制。但这都建立在秩序、时间因果等基础认知之上。
对高级心智能力涌现的初步解剖至此完成。
4
认识涌现
最容易的方法就是重构其基础
2008年,著名哲学家大卫·查尔莫斯对涌现现象做过经典分析。

简单说,查尔默斯将“涌现”(Emergence)定义为复杂系统从低层次组分相互作用中产生高层次、新颖的整体特性。
弱涌现的核心是:高层次现象是低层次组分相互作用的意外或不可预见结果。但原则上,它完全可由低层次规律和初始条件解释和推导。
涌现现象看似意外,如无生命原子组成有生命细胞、硅基芯片和算法产生能理解他人意图的“心智理论”,但可通过物理规律解释,我们要通过科学方法弥合中间的关联性,找到从底层到高层的路径。
而这篇论文证明,重构是建立对大型语言模型“心理”认知、破解其涌现之谜的最佳方法。
沿着论文定位、解剖、重构的路径,我们定能将如魔法般的技术还原为微观、逻辑清晰的计算过程。
本文来自微信公众号“腾讯科技”,作者:博阳,编辑:可君,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com